GenAI 基礎概念解鎖
課程概述
想把生成式 AI 用好,得先搞懂它底層是怎麼運作的。這堂課不碰數學,直接帶你把生成式 AI 從輸入到輸出的整個流程拆開來看,幫你建立一套清楚的技術心智模型。之後不管你是要設計 Prompt、挑模型還是評估 AI 系統,這些基礎都會用得上。
你將學到
- 解釋 Tokenization 的過程與其對成本和效能的影響
- 理解 Embedding 如何將文字轉換為數學表徵
- 掌握 Inference(推論)過程中的關鍵步驟
- 區分不同模型架構的適用場景:僅解碼器、僅編碼器、編碼器-解碼器
核心概念
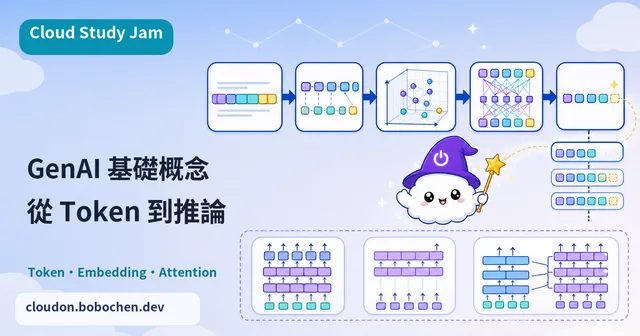
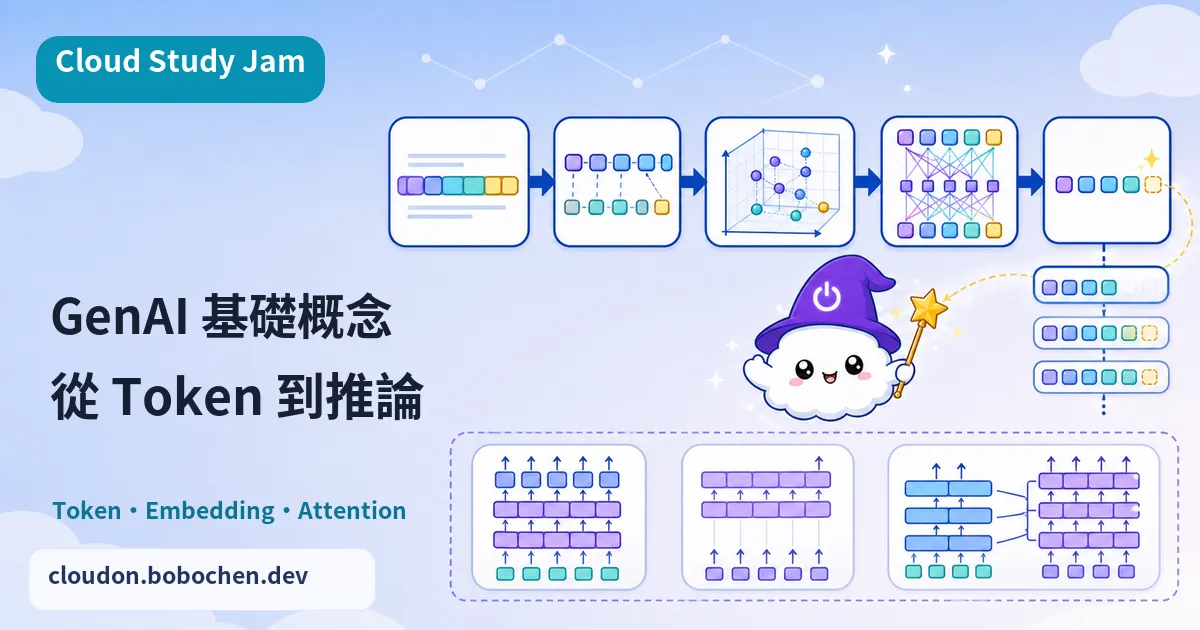
Tokenization:文字的數位化
模型沒辦法直接讀文字,得先把文字切成一個個 Token。Token 不等於「字」或「詞」,它是模型詞彙表裡的最小單位。常用的詞可能整個就是一個 Token,比較罕見的詞則會被切成好幾個。中文每個字元都比較獨立,通常一個字會吃掉 1-2 個 Token;英文常用單字則可能一個字就只佔 1 個 Token。這件事會直接影響 API 怎麼計費,以及 Context Window 用得划不划算。
Embedding:語義的數學表徵
Embedding 會把 Token 轉成高維度的數字向量,讓語義相近的概念在向量空間裡靠在一起。舉例來說,「國王」和「女王」的向量距離,會比「國王」和「蘋果」近很多。搜尋、推薦、分類這些應用都建立在 Embedding 上,它也是 RAG(檢索增強生成)架構的核心組件。
Attention 機制簡介
Attention(注意力)機制讓模型在處理每個 Token 時,能「關注」整段輸入裡所有相關的 Token,而不是只看附近的上下文。這就像你在讀一段文字時,會自動把代名詞「他」連回前面提過的人名。Self-Attention 是 Transformer 架構最關鍵的突破,讓模型能抓到跨越很長距離的語義關聯。
模型架構的三大類型
| 架構類型 | 代表模型 | 擅長任務 |
|---|---|---|
| 僅編碼器(Encoder-only) | BERT | 分類、命名實體辨識、情感分析 |
| 僅解碼器(Decoder-only) | GPT、Gemini | 文字生成、對話、程式碼生成 |
| 編碼器-解碼器(Encoder-Decoder) | T5、BART | 翻譯、摘要、問答 |
現在的生成式 AI 大多用僅解碼器架構(像 Gemini),靠 Autoregressive(自迴歸)的方式,一個 Token 接一個 Token 把輸出生出來。
實作重點
- 使用 Vertex AI 的 Tokenizer 工具,觀察不同語言的文字如何被拆解為 Token
- 透過 Embeddings API 取得文字的向量表徵,計算不同句子之間的相似度
- 注意 Context Window 的大小限制,最新的 Gemini 3.1 Pro 支援最高 100 萬 Token 的上下文
- 理解模型版本命名慣例(如 gemini-3.1-pro),選擇適合的穩定版或最新版
Lab 導讀
Lab 連結:Gen AI: Unlock Foundational Concepts — Google Cloud Skills Boost
這個 Lab 用互動式教學帶你認識 GenAI 的核心概念。建議邊做邊把每個概念的關鍵定義抄下來,因為這些術語後面的課程會一直反覆出現。測驗很常考 Token 跟字詞的關係、Embedding 的用途,還有不同模型架構各自適合什麼場景。
延伸學習
- 探索 GenAI 生態系統 — 了解 GenAI 產業的全貌
- 向量搜尋與嵌入技術 — 看看 Embedding 實際怎麼用
- 注意力機制 — Attention 的數學原理與實作
相關文章
您可能也會對這些文章感興趣