Transformer 與 BERT 模型
課程概述
Transformer 是現代所有大型語言模型的架構基礎,而 BERT 是第一個真正讓大家看到 Transformer Encoder 能做多少事的里程碑模型。這堂課會把 Transformer 的每個組件都拆開來看,從 Positional Encoding 一路講到 Feed-Forward Network,再談談 BERT 的雙向預訓練策略,是怎麼在多項 NLP 基準測試上做出突破的。
你將學到
- 描述 Transformer 的完整架構:六大核心組件
- 解釋 Positional Encoding 如何為模型提供序列位置資訊
- 理解 BERT 的 MLM 與 NSP 預訓練任務
- 區分 BERT(雙向 Encoder)與 GPT(單向 Decoder)的設計哲學
- 掌握 BERT 在下游任務中的 Fine-tuning 方法
核心概念
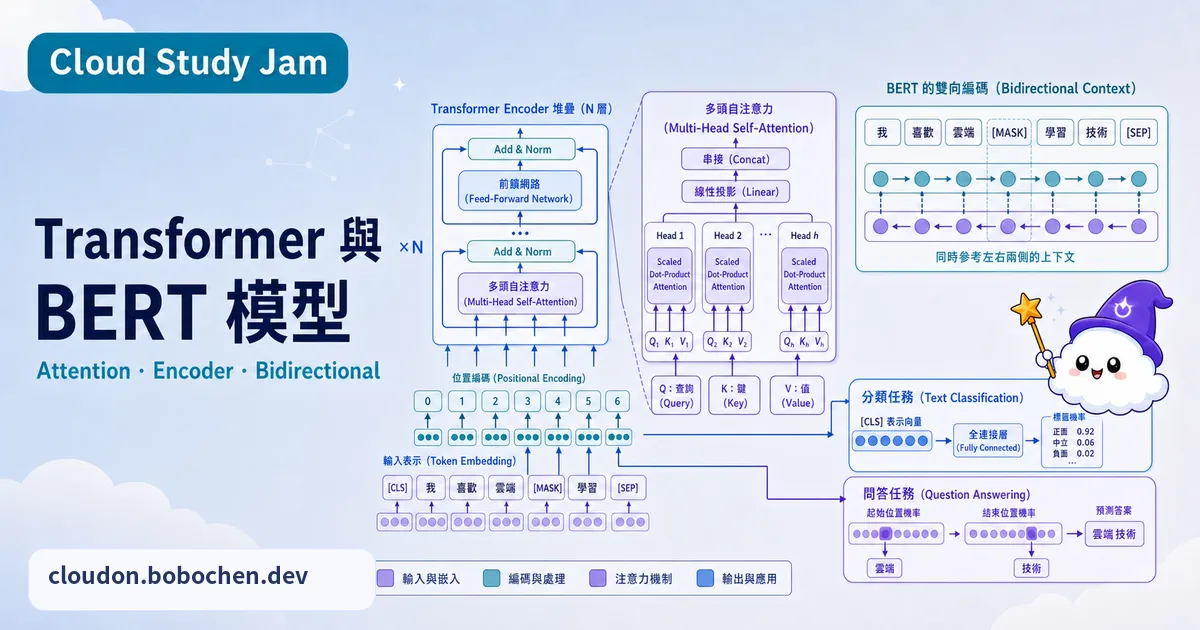
Transformer 的六大核心組件
一個完整的 Transformer 包含:(1)Input Embedding——將 Token 轉換為向量表徵。(2)Positional Encoding——注入位置資訊。(3)Multi-Head Self-Attention——捕捉序列內的依賴關係。(4)Add & Norm——殘差連接與層正規化,穩定訓練過程。(5)Feed-Forward Network——對每個位置獨立進行非線性轉換。(6)Output Linear + Softmax——將最終表徵轉換為詞彙表的機率分佈。
Positional Encoding 的必要性
Attention 機制天生沒有位置概念,它看序列其實是「無序」的。所以才需要 Positional Encoding,在 Embedding 裡加上位置編碼向量,模型才分得出「我喜歡貓」和「貓喜歡我」差在哪。原始 Transformer 論文使用固定的正弦/餘弦函式產生位置編碼;BERT、GPT-2 則使用可學習的位置嵌入(learned positional embeddings,一張可訓練的位置 embedding 表);而 LLaMA、Qwen、DeepSeek 等現代大型語言模型多改用 RoPE(Rotary Position Embedding,旋轉位置編碼)——一種無可訓練參數、直接對 query/key 向量施加旋轉以編碼相對位置的方法。
BERT 的設計哲學
BERT(Bidirectional Encoder Representations from Transformers)只使用 Transformer 的 Encoder 部分,但有一個關鍵創新:雙向上下文。傳統的語言模型只能從左到右(或從右到左)讀文字,BERT 則是同時看一個 Token 左右兩邊的上下文。所以碰到那些得看懂完整語境的任務(分類、命名實體辨識、問答),BERT 就特別吃香。
BERT 的預訓練策略
BERT 靠兩個很巧妙的預訓練任務。MLM(Masked Language Model):隨機把輸入裡 15% 的 Token 遮起來,叫模型去猜被遮掉的是什麼。這樣一逼,模型就得學會雙向的語義理解。NSP(Next Sentence Prediction):給兩個句子,判斷第二句是不是第一句的下一句。這讓模型搞懂句子跟句子之間的關係。
BERT vs GPT 的設計對比
| 維度 | BERT | GPT |
|---|---|---|
| 架構 | Transformer Encoder | Transformer Decoder |
| 上下文方向 | 雙向 | 單向(左到右) |
| 預訓練任務 | MLM + NSP | 語言建模(預測下一個 Token) |
| 擅長任務 | 理解型(分類、問答、NER) | 生成型(文字生成、對話) |
| 微調方式 | 加上任務特定的輸出頭 | Prompt Engineering 或 Fine-tuning |
實作重點
- 在 Vertex AI 上使用預訓練的 BERT 模型進行情感分析或文字分類
- 了解 BERT 的輸入格式:[CLS] + Token 序列 + [SEP],以及 Segment Embedding 的作用
- 比較 BERT-base(1.1 億參數)與 BERT-large(3.4 億參數)在下游任務上的表現差異
- 嘗試在 TensorFlow 中載入 Hugging Face 的 BERT 模型,觀察 Attention 權重的分佈
Lab 導讀
Lab 連結:Transformer Models and BERT Model — Google Cloud Skills Boost
這個 Lab 大概是深度學習架構系列裡最核心的一課。測驗會考 Transformer 的完整架構、各組件在做什麼、為什麼需要 Positional Encoding、BERT 的預訓練策略,還有 BERT 跟 GPT 的差別。建議先把 Attention 機制和 Encoder-Decoder 架構搞懂一點,再來上這一課會比較順。
延伸學習
相關文章
您可能也會對這些文章感興趣
Transformer 與 BERT 模型
完整解析 Transformer 架構的所有組件,並深入了解 BERT 如何以雙向編碼器革新自然語言理解任務
圖片說明生成模型
學習圖片說明生成(Image Captioning)的技術原理,理解視覺 Encoder 與語言 Decoder 如何協作,從圖片自動產出描述文字
注意力機制
深入理解 Attention Mechanism 的數學原理與實作方式,認識 Self-Attention 如何成為 Transformer 的核心創新
