向量搜尋與嵌入技術
課程概述
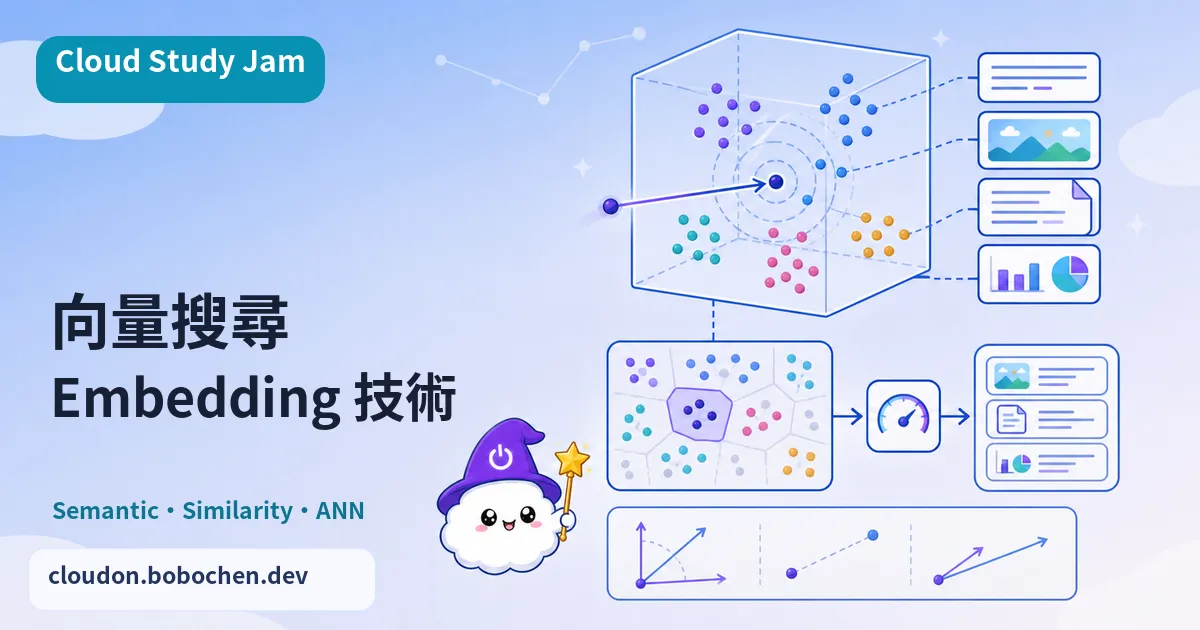
智慧搜尋、推薦系統、RAG 架構,底層都靠向量搜尋(Vector Search)和嵌入技術(Embeddings)撐著。這堂課從 Embedding 的概念講起,先搞懂傳統關鍵字搜尋為什麼不夠用,再學怎麼用 Vertex AI 的 Embeddings API 跟 Vector Search 做出語義搜尋系統。
你將學到
- 解釋 Embedding 的數學直覺:高維空間中的語義距離
- 比較文字 Embedding、圖片 Embedding 與多模態 Embedding 的差異
- 使用 Vertex AI Embeddings API 將文字轉換為向量
- 建構基於 Vertex AI Vector Search 的近似最近鄰搜尋系統
核心概念
為什麼需要 Embedding?
傳統搜尋靠的是關鍵字精確匹配,所以你搜「如何退款」,根本找不到一篇寫「申請退費流程」的文件。Embedding 則是把文字轉成高維度向量,讓語義相近的內容在向量空間裡距離也相近。這樣一來搜尋系統就知道「退款」跟「退費」講的是同一件事,召回率和準確度都明顯往上拉。
Embedding 的維度與模型
不同的 Embedding 模型,產出的向量維度也不一樣。Google 的 gemini-embedding-001 模型預設產出 3072 維向量,並支援 Matryoshka 表示學習(MRL),可縮減為 1536 或 768 維;multimodalembedding 則能處理文字跟圖片的跨模態嵌入。維度越高,理論上越能捕捉細緻的語義差異,但相對也吃更多儲存空間和運算資源。實務上 768 維對大多數場景已經夠用了。
向量相似度的計算
要衡量兩個向量有多像,常用的方法有幾種。餘弦相似度(Cosine Similarity) 看的是向量方向夠不夠一致,範圍 -1 到 1,也是最常用的一種。歐幾里得距離(L2 Distance) 量的是兩個向量在空間裡的直線距離。內積(Dot Product) 則是方向和大小一起看。要選哪一種,看你用的 Embedding 模型和應用場景而定。
Vertex AI Vector Search 架構
Vertex AI Vector Search 是全代管的向量搜尋服務,底層用的是 Google 內部的 ScaNN(Scalable Nearest Neighbors)演算法。它撐得住數十億級別的向量索引,查詢延遲只有毫秒級。幾個要記的核心概念:Index(索引,存放向量資料)、Endpoint(端點,負責處理查詢請求)、還有 Approximate Nearest Neighbor(ANN,近似最近鄰,犧牲一點點精確度,換來效能大幅提升)。
實作重點
- 使用 Vertex AI Embeddings API,將一組中文句子轉換為向量並計算彼此的相似度
- 建立一個小型的 Vector Search Index,載入自己的文件資料
- 比較精確搜尋(Brute-force)與近似搜尋(ANN)在速度與準確度上的差異
- 了解 Embedding 的更新策略:當資料變動頻繁時,如何高效更新向量索引
Lab 導讀
Lab 連結:Vector Search and Embeddings — Google Cloud Skills Boost
這個 Lab 有實作環節,你會用 Vertex AI Embeddings API 產生向量,再建立 Vector Search 索引來跑語義搜尋。建議先把 Embedding 的概念搞懂再動手,操作時要留意 Index 建立得等一段時間。測驗重點放在 Embedding 維度怎麼選、向量相似度怎麼算,以及 ANN 跟精確搜尋之間怎麼取捨。
延伸學習
- Gemini 多模態 RAG 文件檢索 — Vector Search 在 RAG 架構中的核心應用
- GenAI 基礎概念解鎖 — 回顧 Embedding 的基礎概念
- RAG 架構 — 登雲學院 GenAI Leader 課程的 RAG 專題
相關文章
您可能也會對這些文章感興趣
向量搜尋與嵌入技術
深入學習 Embedding 與 Vector Search 的原理與實作,掌握 Vertex AI Vector Search 在語義搜尋與 RAG 中的核心角色
GenAI 的 MLOps 實踐
學習如何將 MLOps 最佳實踐應用於生成式 AI 的生命週期管理,涵蓋模型版本控制、持續評估、A/B 測試與生產監控
負責任 AI:可解釋性與透明度
學習讓 AI 模型決策過程可被理解的技術方法,掌握 Google Cloud Explainable AI 與 LIT 工具的實作
