編碼器-解碼器架構
課程概述
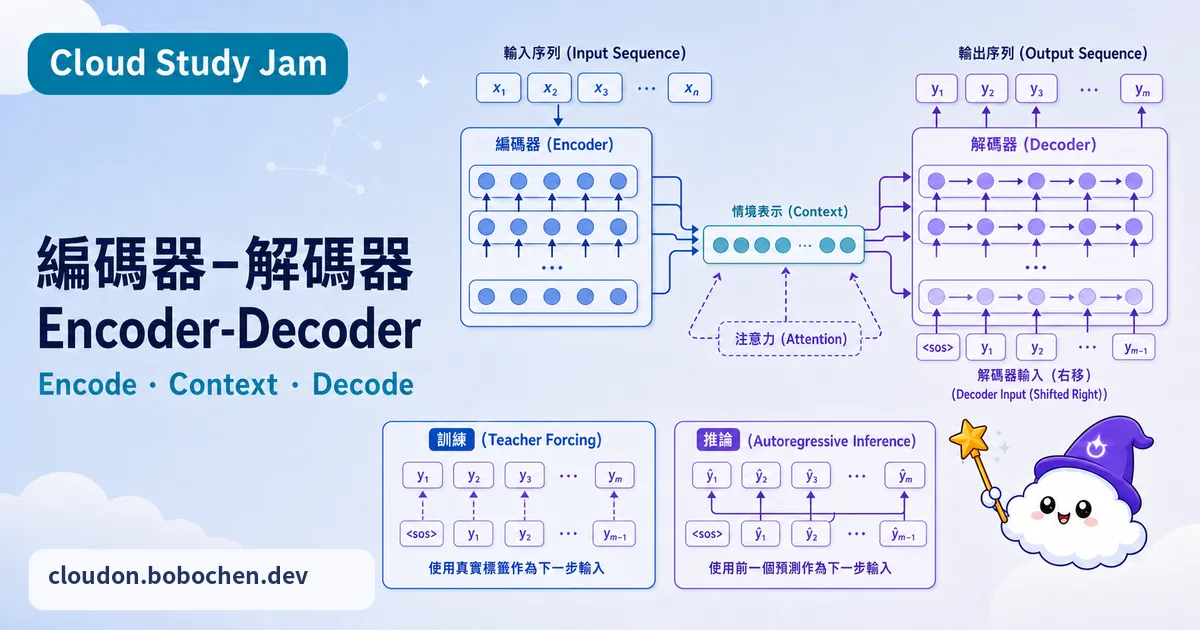
Encoder-Decoder 是深度學習裡處理「序列到序列」(Sequence-to-Sequence, Seq2Seq)任務的經典架構。從機器翻譯到文字摘要,很多 NLP 任務說穿了都是把一個序列轉成另一個序列。這堂課會談談這個架構的設計理念、各組件怎麼運作,以及它怎麼跟 Attention 機制結合,最後變成 Transformer。
你將學到
- 描述 Encoder-Decoder 架構的整體資料流向
- 解釋 Encoder 如何將輸入序列壓縮為上下文表徵
- 理解 Decoder 如何利用上下文表徵逐步生成輸出序列
- 比較 RNN-based 與 Transformer-based 的 Encoder-Decoder 差異
核心概念
Seq2Seq 問題的本質
很多 NLP 任務都能看成序列到序列的轉換:機器翻譯(中文序列轉英文序列)、文字摘要(長序列轉短序列)、問答(問題序列轉答案序列)、程式碼生成(自然語言序列轉程式碼序列)。這些任務有個共同點:輸入跟輸出的長度不一定一樣,而且輸出的每個元素,都可能跟輸入的任何位置有關。
Encoder 的角色
Encoder 負責「理解」輸入序列。它一個一個處理輸入的每個 Token,把整個序列的語義資訊壓縮成一組向量表徵(Context Vectors)。早期的 RNN-based 架構是把所有資訊都塞進最後一個隱藏狀態;Transformer 架構則是為每個輸入 Token 各自產生一個上下文化的表徵,保留了更豐富的位置與語義資訊。
Decoder 的角色
Decoder 負責「生成」輸出序列。它用自迴歸(Autoregressive)的方式運作:每一步都會根據 Encoder 的上下文表徵,加上之前已經生成的 Token,預測下一個 Token。這個過程一直跑,直到生成特殊的結束標記(End-of-Sequence Token)為止。而 Decoder 裡的 Cross-Attention 層,就是連接 Encoder 跟 Decoder 的關鍵橋樑。
Teacher Forcing 訓練技巧
訓練階段,Decoder 的輸入吃的是「正確答案」,而不是模型自己的預測。舉個例子,翻譯任務裡就算模型第三個字猜錯了,第四個字的輸入還是會用正確的第三個字。這個技巧叫做 Teacher Forcing,好處是能加速訓練收斂,但壞處是可能造成訓練跟推論的行為差距(Exposure Bias)。
從 RNN 到 Transformer 的演進
早期的 Encoder-Decoder 架構用 RNN 或 LSTM 當基礎單元,會卡在兩個問題上:長距離依賴衰減,還有沒辦法平行化。Transformer 架構乾脆整個用 Attention 機制取代了循環結構:Encoder 用 Self-Attention 處理輸入序列,Decoder 用 Masked Self-Attention 處理已經生成的序列,兩邊再靠 Cross-Attention 連起來。這樣不只解決了長距離依賴的問題,還能完全平行運算。
實作重點
- 畫出完整的 Encoder-Decoder 資料流圖,標註 Self-Attention 與 Cross-Attention 的位置
- 用 TensorFlow 建構一個簡單的 Seq2Seq 翻譯模型,體驗訓練與推論的完整流程
- 比較有無 Attention 機制的 Encoder-Decoder 在長序列翻譯上的表現差異
- 嘗試 Beam Search 與 Greedy Decoding 兩種解碼策略的效果差異
Lab 導讀
Lab 連結:Encoder-Decoder Architecture — Google Cloud Skills Boost
這個 Lab 主要是理論講解配架構圖,把 Encoder-Decoder 的各組件功能講清楚。測驗重點有這幾個:Encoder 跟 Decoder 各自負責什麼、Cross-Attention 的作用、Teacher Forcing 的優缺點,還有 Transformer 架構比 RNN 強在哪。建議搭配 Attention 機制那一課一起看,會更好懂。
延伸學習
- 注意力機制 — Attention 的詳細原理
- Transformer 與 BERT 模型 — 完整的 Transformer 實作
- 圖片說明生成模型 — Encoder-Decoder 在視覺任務中的應用
相關文章
您可能也會對這些文章感興趣
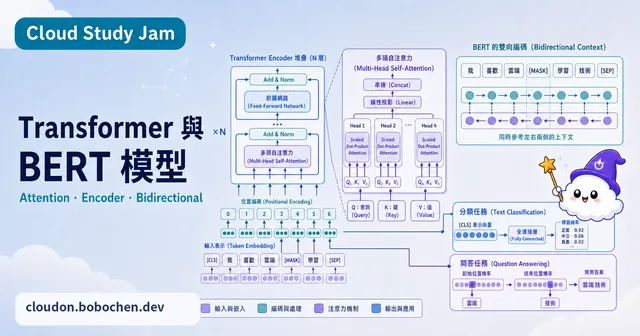
Transformer 與 BERT 模型
完整解析 Transformer 架構的所有組件,並深入了解 BERT 如何以雙向編碼器革新自然語言理解任務
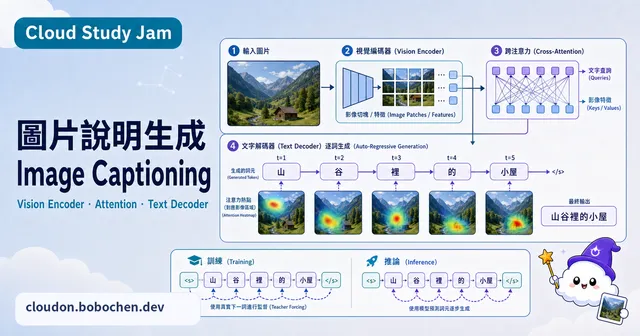
圖片說明生成模型
學習圖片說明生成(Image Captioning)的技術原理,理解視覺 Encoder 與語言 Decoder 如何協作,從圖片自動產出描述文字
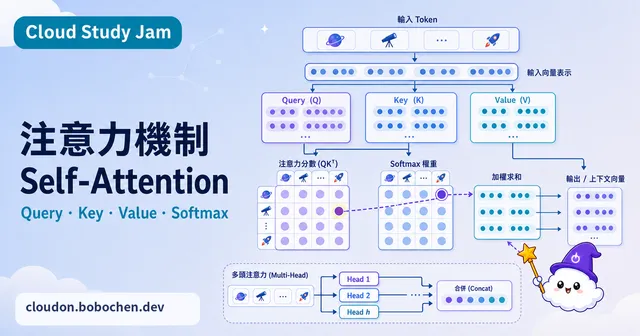
注意力機制
深入理解 Attention Mechanism 的數學原理與實作方式,認識 Self-Attention 如何成為 Transformer 的核心創新
