注意力機制
課程概述
注意力機制(Attention Mechanism)是現代生成式 AI 的核心引擎。從 2017 年那篇「Attention Is All You Need」論文開始,Attention 讓序列模型的設計方式整個變了,Transformer 架構也才有可能出現。這堂課我們會把 Attention 的運作原理拆開來看,搞懂 LLM 為什麼能「讀懂」語言裡那些隔很遠的依賴關係。
你將學到
- 解釋傳統 RNN/LSTM 的序列處理限制與 Attention 的解決方案
- 描述 Scaled Dot-Product Attention 的 Query-Key-Value 機制
- 理解 Multi-Head Attention 如何捕捉多面向的語義關係
- 區分 Self-Attention 與 Cross-Attention 的應用場景
核心概念
為什麼需要 Attention?
傳統的序列模型(RNN、LSTM)會一個一個處理輸入序列裡的 Token,把所有上下文壓進一個固定大小的向量。這會帶來兩個問題:一是「資訊瓶頸」,長序列裡早期的資訊在傳遞過程中會慢慢衰減;二是「無法平行化」,只能照順序一個一個 Token 跑。Attention 機制則讓模型在處理某個 Token 時,可以直接「回頭看」輸入序列裡的所有 Token,這兩個問題就一次解掉了。
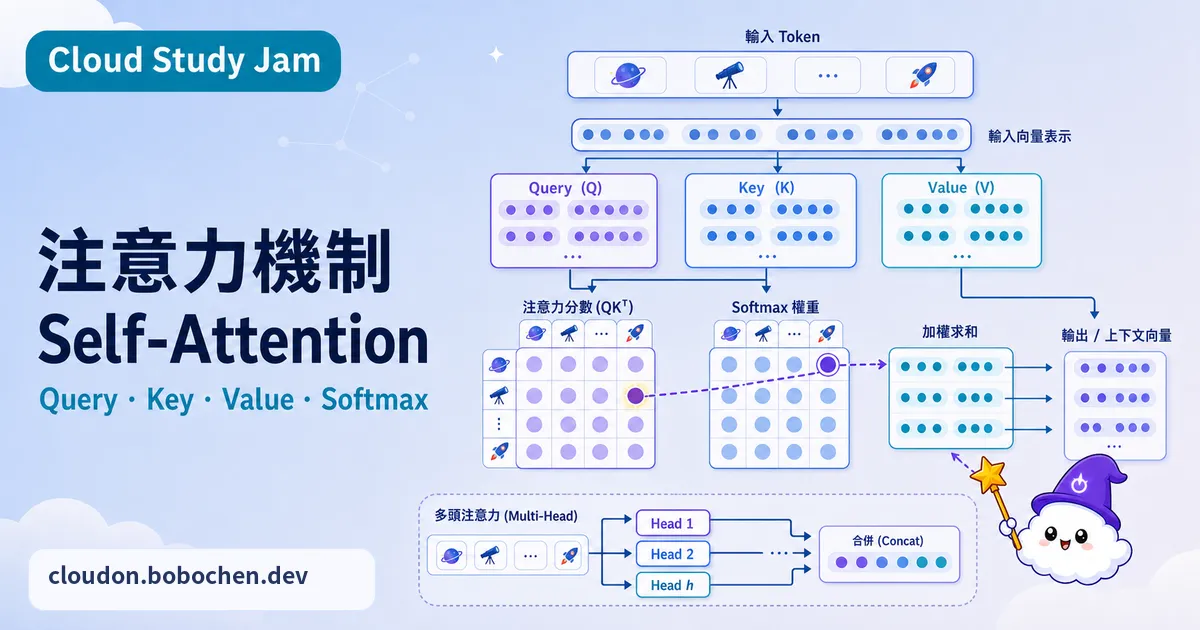
Query-Key-Value 的直覺解釋
Attention 可以拿「去圖書館找書」來類比。Query(查詢)就是你的問題:「我想找關於 Kubernetes 的書」。Key(鍵)是每本書的索引標籤。Value(值)是書的實際內容。Attention 怎麼運作呢?拿 Query 跟每個 Key 算出相關性分數,再依分數把所有 Value 做加權求和,就得到最後結果。寫成數學就是 Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V。
Scaled Dot-Product Attention
先算 Q 和 K 的內積,得到注意力分數,再除以 sqrt(d_k)(也就是 Key 維度的平方根)做縮放。這個縮放不能省,因為維度一高,內積值會變得很大,softmax 的梯度就會趨近於零。接著 softmax 把分數轉成 0-1 之間的權重(加總為 1),最後再用這些權重對 V 做加權求和。
Multi-Head Attention
單一個 Attention 只抓得到一種語義關係。Multi-Head Attention 則把 Q、K、V 分別投影到好幾個子空間,各算各的 Attention,最後再合起來。比方說 8 個 Head 就能各自學不同面向的依賴:語法關係、語義相似性、指代消解、位置相鄰等等。算完之後,把所有 Head 的輸出串接起來,再投影回原本的維度。
Self-Attention vs Cross-Attention
Self-Attention 的 Q、K、V 都來自同一個序列,也就是每個 Token 去關注同一序列裡的其他 Token,它是 Transformer Encoder 的核心組件。Cross-Attention 則不一樣,Q 來自一個序列,K 和 V 來自另一個序列。以翻譯模型來說,就是目標語言的 Token 去關注原始語言的 Token,這也是 Encoder-Decoder 架構裡連接兩端的橋樑。
實作重點
- 用 NumPy 手動實作一次 Scaled Dot-Product Attention 的計算,理解每個步驟
- 在 TensorFlow/Keras 中用
tf.keras.layers.MultiHeadAttention建構一個簡單的 Attention 層 - 視覺化 Attention 權重矩陣,觀察模型在處理不同 Token 時「關注」的位置
- 比較 Head 數量(4 vs 8 vs 16)對模型表現的影響
Lab 導讀
Lab 連結:Attention Mechanism — Google Cloud Skills Boost
這個 Lab 以理論教學為主,搭配圖示說明 Attention 怎麼運作。這也是整個課程裡數學密度最高的一段,建議先別卡在每個公式上硬要全懂,先把 QKV 的直覺抓起來就好。測驗重點有:Attention 解決了什麼問題、QKV 各自扮演什麼角色,還有 Multi-Head 的優勢在哪。
延伸學習
- 編碼器-解碼器架構 — Attention 在 Encoder-Decoder 中的應用
- Transformer 與 BERT 模型 — 完整的 Transformer 架構解析
- GenAI 基礎概念解鎖 — 回顧 Attention 的入門說明
相關文章
您可能也會對這些文章感興趣
Transformer 與 BERT 模型
完整解析 Transformer 架構的所有組件,並深入了解 BERT 如何以雙向編碼器革新自然語言理解任務
圖片說明生成模型
學習圖片說明生成(Image Captioning)的技術原理,理解視覺 Encoder 與語言 Decoder 如何協作,從圖片自動產出描述文字
注意力機制
深入理解 Attention Mechanism 的數學原理與實作方式,認識 Self-Attention 如何成為 Transformer 的核心創新
