建構 GenAI 應用
課程概述
把 GenAI 塞進實際應用,光會呼叫 API 還不夠,架構怎麼設計、安全怎麼顧、錯誤怎麼處理、效能怎麼調,這些都得想清楚。這門課走實戰路線,帶你在 Google Cloud 上做出一個完整的 GenAI 應用,從後端 API 服務一路到前端介面,把從原型到上線的整個流程跑過一遍。
你將學到
- 設計 GenAI 應用的參考架構:前端、後端、模型層的分層
- 使用 Google Gen AI SDK(
google-genai)建構 GenAI 後端服務 - 在 Cloud Run 上部署可自動擴展的 GenAI API 服務
- 處理 API 限流、錯誤重試與超時等生產環境問題
- 實作基本的輸入驗證與輸出安全篩選
核心概念
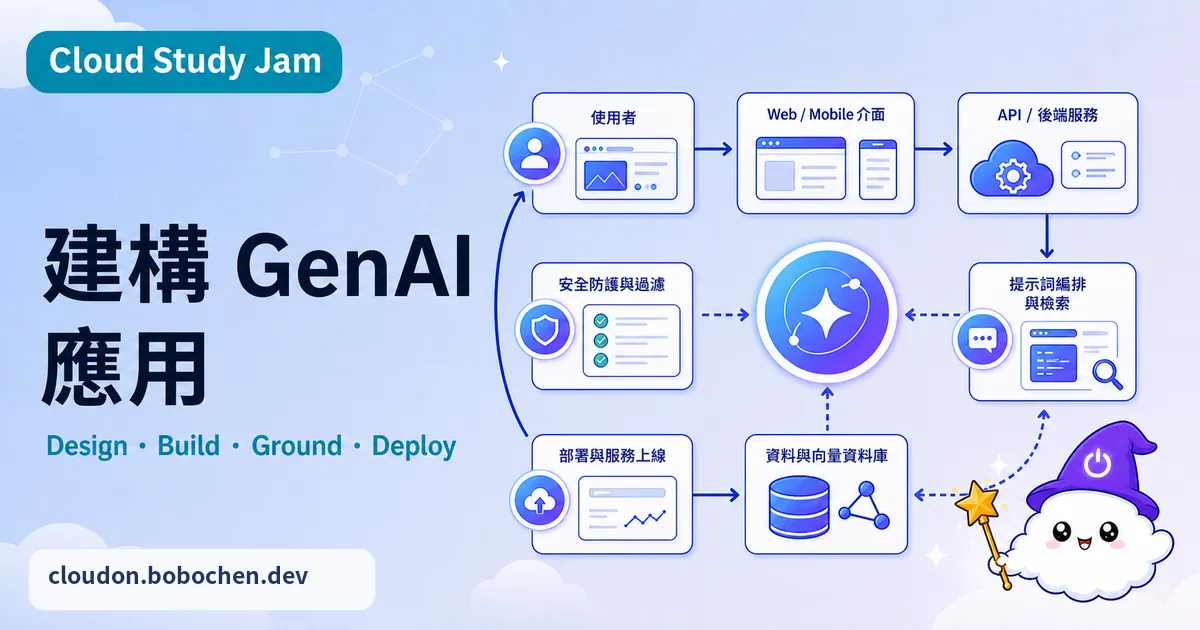
GenAI 應用的三層架構
典型的 GenAI 應用分成三層。前端層:使用者介面,負責收輸入、秀回應、顧互動體驗(串流顯示、Markdown 渲染那些)。後端層:API 服務,負責 Prompt 建構、模型呼叫、結果後處理,還有跟其他服務的整合。模型層:基礎模型服務(Vertex AI),負責真正的推論運算。這樣分層,各層才能各自演進、各自擴展,互不干擾。
Prompt 管理策略
上了生產環境,Prompt 千萬別寫死在程式碼裡。建議把 Prompt 模板拉出來獨立管理,這樣才能做版本控制跟 A/B 測試。常見做法是把模板放在 Cloud Storage 或 Firestore,後端每次請求時動態載入最新版本。好處是,團隊想調 Prompt 不用重新部署。
Cloud Run 部署架構
部署 GenAI API 服務,Cloud Run 很適合。它支援基於請求的自動擴展(包括縮放到零),內建 HTTPS 終端,最小/最大實例數也能自己設。GenAI 應用建議把請求超時拉長一點(60-300 秒),因為 LLM 回應有時候會慢。另外搭配 Cloud Run 的並行處理能力,單一實例就能同時扛多個 API 請求。
生產環境的必備機制
要把 GenAI 應用推上生產環境,這幾件事得先想好:API 限流——別讓單一使用者或突發流量把模型配額吃光;重試策略——用指數退避(Exponential Backoff)來處理暫時性錯誤;內容安全——輸入要驗證,輸出要做安全篩選;可觀察性——把每次請求的 Prompt、回應、延遲跟 Token 使用量記下來,方便偵錯跟追成本。
實作重點
- 用 Python Flask 或 FastAPI 建構一個呼叫 Gemini API 的後端服務
- 將服務容器化並部署到 Cloud Run,設定自動擴展與請求超時
- 實作串流回應的 SSE(Server-Sent Events)端點,提升使用者體驗
- 加入輸入長度限制、內容安全篩選與 API Key 驗證等基本安全機制
- 使用 Cloud Logging 記錄每次 API 呼叫的關鍵指標
Lab 導讀
Lab 連結:Create Generative AI Apps on Google Cloud — Google Cloud Skills Boost
這個 Lab 重點全在動手寫程式,你會做出一個端到端的 GenAI 應用,再部署到 Cloud Run。做的時候多留意 Cloud Run 的部署配置、環境變數怎麼設,還有 API 的錯誤處理邏輯。Lab 跑完後,建議自己動手改改功能或加幾個端點,對架構的理解會更扎實。
延伸學習
- GenAI 驅動網站現代化 — GenAI 在前端應用中的整合模式
- Gemini + Streamlit 開發 GenAI App — 快速原型的替代方案
- Gemini 開發者指南 — 回顧 Gemini API 的核心功能
相關文章
您可能也會對這些文章感興趣
建構 GenAI 應用
在 Google Cloud 上從零建構生成式 AI 應用,涵蓋架構設計、API 整合、後端部署與前端互動的完整流程
Gemini + Streamlit 開發 GenAI App
使用 Streamlit 框架快速建構 Gemini 驅動的 GenAI 應用原型,從本地開發到 Cloud Run 部署的完整工作流
Gemini 開發者指南
學習使用 Gemini API 開發應用程式,涵蓋 SDK 設定、多模態輸入、串流回應與 Function Calling 等核心開發技巧
