圖片說明生成模型
課程概述
圖片說明生成(Image Captioning)是一個很有意思的跨模態任務:讓 AI「看懂」圖片,再用自然語言把裡面的內容講出來。它同時用到電腦視覺和自然語言處理,想搞懂多模態 AI 怎麼運作,從這裡入門最合適。這堂課就帶你看看它的技術演進,以及 Google Cloud 上有哪些相關工具。
你將學到
- 描述 Image Captioning 的技術架構演進:從 CNN + RNN 到 Vision Transformer
- 理解視覺 Encoder 如何從圖片中提取特徵
- 解釋語言 Decoder 如何根據視覺特徵生成描述文字
- 了解 Google Cloud Vision API 與 Gemini 在圖片理解上的不同能力
核心概念
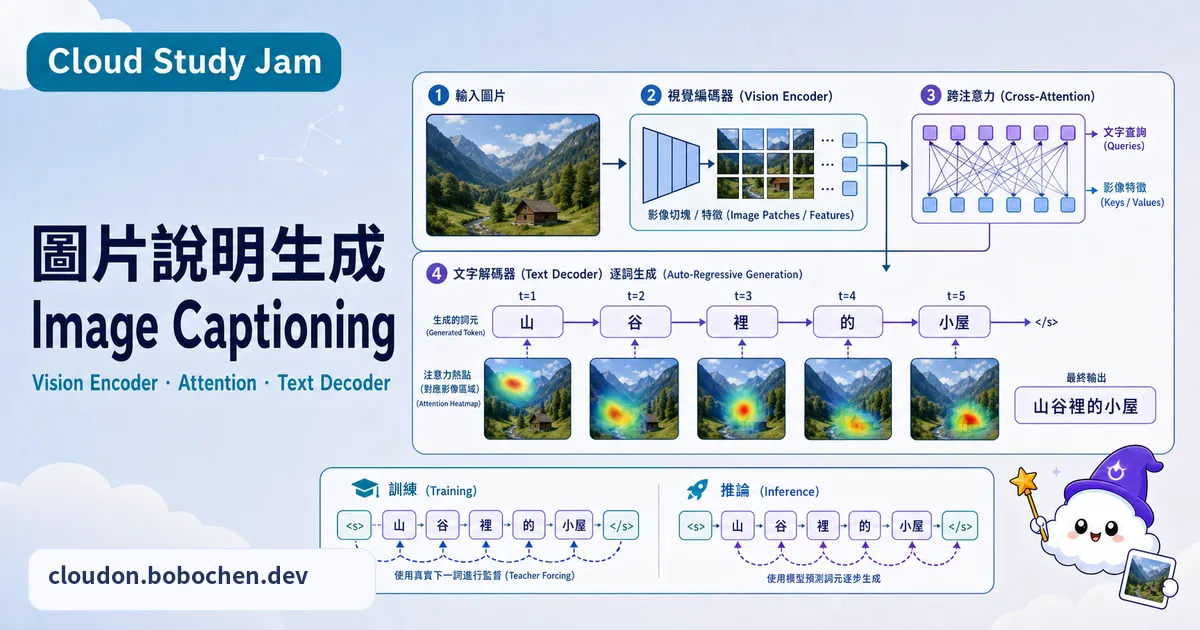
Image Captioning 的架構演進
Image Captioning 一路走來大致有三代架構。第一代用 CNN(像 ResNet)當視覺 Encoder 提取圖片特徵,搭配 LSTM 當語言 Decoder 生成描述。第二代加入 Attention 機制,讓 Decoder 每生成一個字詞時,能聚焦到圖片裡相關的區域。第三代改用 Vision Transformer(ViT)當 Encoder,完全用 Attention 機制取代 CNN,效能上有明顯的突破。
視覺 Encoder 的角色
視覺 Encoder 將圖片轉換為一組特徵向量。在 CNN-based 架構中,這些特徵來自卷積層的輸出,每個特徵對應圖片的一個區域。在 ViT-based 架構中,圖片先被切割為固定大小的 Patch(例如 16x16 像素),每個 Patch 被視為一個「視覺 Token」,透過 Transformer Encoder 處理後產生上下文化的特徵表徵。
Cross-Modal Attention
在 Image Captioning 裡,Cross-Attention 就是連接視覺和語言這兩個模態的橋樑。語言 Decoder 的 Query 來自已經生成的文字序列,Key 和 Value 則來自視覺 Encoder 的圖片特徵。這樣一來,模型在生成「狗」這個字時,就能把注意力集中到圖片中狗的區域,做到精準的圖文對應。
Gemini 的多模態理解
Google 的 Gemini 模型原生就支援多模態輸入,圖片理解能力比傳統的 Image Captioning 模型強上一大截。它不只能描述圖片裡的物件和場景,還能看懂圖表的資料趨勢、分析架構圖的邏輯結構、辨識文件裡的表格資訊。所以大多數圖片理解的場景,直接呼叫 Gemini API 通常是最省事的做法。
評估指標
Image Captioning 的常見評估指標包括:BLEU——比較生成文字與參考文字的 n-gram 重疊度;METEOR——考慮同義詞和語序的改進指標;CIDEr——專門針對圖片描述設計,考量描述的獨特性與資訊量。這些自動化指標跟人類評分之間還是有落差,所以正式上線時,建議再搭配人工評估。
實作重點
- 使用 Vision API 的 Label Detection 和 Object Detection 分析圖片內容
- 使用 Gemini API 進行開放式的圖片問答(「這張圖中有幾個人?他們在做什麼?」)
- 比較 Vision API(結構化標籤)與 Gemini(自然語言描述)在相同圖片上的輸出
- 嘗試在 TensorFlow 中用 Keras 建構一個簡單的 CNN + LSTM Image Captioning 模型
Lab 導讀
Lab 連結:Create Image Captioning Models — Google Cloud Skills Boost
這個 Lab 以技術原理講解為主,帶你看 Image Captioning 從 CNN+RNN 到 Transformer 的演進。測驗重點有幾個:視覺 Encoder 和語言 Decoder 各自的角色、Attention 在跨模態任務裡的作用,還有不同評估指標的特點。建議搭配前面的 Attention 和 Encoder-Decoder 課程一起複習。
延伸學習
- 編碼器-解碼器架構 — Encoder-Decoder 的完整架構說明
- 圖片生成技術導論 — 從圖片理解到圖片生成的反向任務
- Gemini 多模態 RAG 文件檢索 — 多模態理解的實際應用
相關文章
您可能也會對這些文章感興趣
圖片說明生成模型
學習圖片說明生成(Image Captioning)的技術原理,理解視覺 Encoder 與語言 Decoder 如何協作,從圖片自動產出描述文字
Transformer 與 BERT 模型
完整解析 Transformer 架構的所有組件,並深入了解 BERT 如何以雙向編碼器革新自然語言理解任務
注意力機制
深入理解 Attention Mechanism 的數學原理與實作方式,認識 Self-Attention 如何成為 Transformer 的核心創新
