負責任 AI:可解釋性與透明度
課程概述
「AI 為什麼做出這個決定?」使用者、監管者、開發者都會問這句話。AI 系統如果是個黑箱,大家就很難信任它的決策。這堂課會介紹幾種讓 AI 模型「看得懂」的技術,從特徵重要性到注意力視覺化,幫你在 Google Cloud 上做出有透明度的 AI 應用。
你將學到
- 區分可解釋性(Interpretability)與可說明性(Explainability)的差異
- 掌握三大類解釋技術:特徵歸因、範例式解釋、反事實解釋
- 使用 Vertex AI Explainable AI 產出模型預測的解釋
- 運用 LIT(Learning Interpretability Tool,前身為 Language Interpretability Tool)分析模型行為
核心概念
可解釋性 vs 可說明性
可解釋性(Interpretability)是指模型本身夠簡單,人可以直接看懂它的決策邏輯,像決策樹、線性回歸都是這類。可說明性(Explainability)則是另一回事:當模型複雜到沒辦法直接看懂時,改用事後分析的技術去解釋單筆預測為什麼會這樣。深度學習、LLM 這種複雜模型,我們追求的通常就是可說明性。
三大類解釋技術
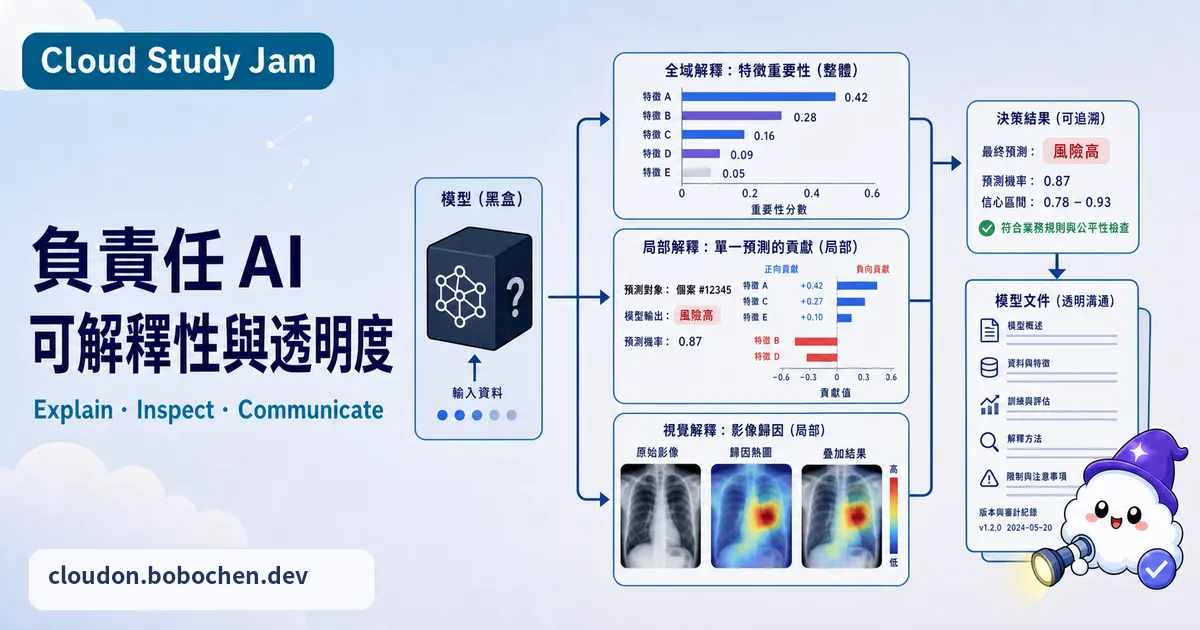
(1)特徵歸因(Feature Attribution):量化每個輸入特徵對預測結果貢獻了多少。SHAP(Shapley Additive Explanations)的基礎是賽局理論,算的是每個特徵的「邊際貢獻」;Integrated Gradients 則是沿著輸入空間的路徑去積分梯度。這兩種方法回答的都是同一個問題:「哪些輸入因素最影響這個預測?」
(2)範例式解釋(Example-based Explanation):從訓練資料裡找出最相似的案例來解釋預測。例如「這筆交易被判定為詐騙,是因為它跟以下三筆已確認的詐騙交易特徵很像」。對非技術的使用者來說,這種解釋最好懂。
(3)反事實解釋(Counterfactual Explanation):找出「最小的輸入改動」就能翻轉預測結果。例如「如果申請人的年收入增加 20%,這筆貸款就會被核准」。這類解釋給的是可以實際照做的建議,但要小心別把可能被人鑽漏洞的策略也一起暴露出去。
Vertex AI Explainable AI
Vertex AI 內建的 Explainable AI,可以在部署模型時自動產出特徵歸因解釋,表格資料模型和圖片分類模型都支援。你在把模型部署到 Endpoint 時,指定要用哪種解釋方法(Sampled Shapley、Integrated Gradients 或 XRAI),之後平台每次回傳預測,就會順便帶上歸因分析的結果。
LIT(Learning Interpretability Tool,前身為 Language Interpretability Tool)
LIT 是 Google 開源的模型分析工具,用互動式介面讓你探索模型的行為。它一開始只做 NLP,不過 2022 年改名成 Learning Interpretability Tool 之後,就擴展到表格、圖片等多種模型類型,不再只限語言模型了。核心功能有這幾項:注意力權重視覺化、Embedding 空間投影、預測信心度分析,還有對抗性範例測試(改一下輸入,看模型反應穩不穩)。拿來分析 BERT 這類編碼器模型特別好用。
實作重點
- 在 Vertex AI 上部署一個帶 Explainable AI 的分類模型,觀察特徵歸因結果
- 比較 Sampled Shapley 與 Integrated Gradients 兩種方法的解釋差異
- 用 LIT 載入一個文字分類模型,視覺化 Attention 權重並分析模型關注的文字區域
- 對 LLM 的回答進行「解釋性審計」:要求模型說明推理過程,評估其自我解釋的品質
Lab 導讀
Lab 連結:Responsible AI for Developers: Interpretability & Transparency — Google Cloud Skills Boost
這個 Lab 會帶你實際操作 Vertex AI Explainable AI 和 LIT 工具。動手時,重點是搞懂不同解釋技術各自適合什麼場景,因為測驗很愛考「這個情境下該用哪種解釋方法?」。另外特別留意解釋結果的侷限:特徵歸因只會告訴你「什麼重要」,不一定能告訴你「為什麼重要」。
延伸學習
- 負責任 AI:公平性與偏差 — 可解釋性如何輔助偏差診斷
- 負責任 AI:隱私與安全 — Responsible AI 的隱私面向
- Google Cloud AI 負責任原則實踐 — 回顧整體框架
相關文章
您可能也會對這些文章感興趣
負責任 AI:可解釋性與透明度
學習讓 AI 模型決策過程可被理解的技術方法,掌握 Google Cloud Explainable AI 與 LIT 工具的實作

Google Cloud AI 負責任原則實踐
學習如何在 Google Cloud 平台上將 Responsible AI 原則落實到 AI 開發工作流中,涵蓋工具、流程與組織層面的實踐方法
負責任 AI:隱私與安全
學習在 AI 系統中保護使用者隱私與確保安全的技術方案,涵蓋差分隱私、聯邦學習、資料遮蔽與 VPC 安全控管
