圖片生成技術導論
課程概述
圖片生成大概是生成式 AI 裡最吸睛的應用了,畢竟結果直接用眼睛就看得到。這堂課帶你看看圖片生成技術一路怎麼演進,仔細認識目前的主流架構 Diffusion Model,還有 Google 的 Imagen 模型怎麼在 Vertex AI 上提供企業級的圖片生成能力。
你將學到
- 追溯圖片生成技術的演進:從 GAN 到 VAE 再到 Diffusion Model
- 解釋 Diffusion Model 的正向擴散與逆向去噪過程
- 理解文字到圖片(Text-to-Image)的技術架構
- 掌握 Google Imagen 在 Vertex AI 上的使用方式與限制
核心概念
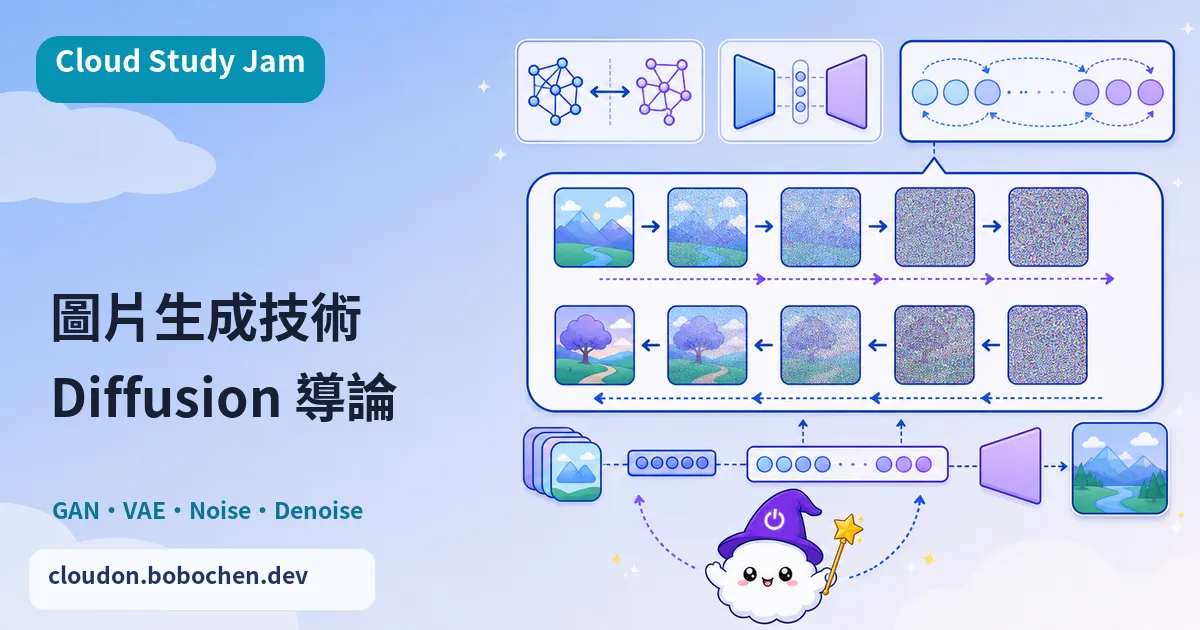
圖片生成的三代技術
圖片生成技術主要走過三個世代。第一代是 GAN(生成對抗網路),靠生成器跟判別器互相對抗來訓練、產生圖片,問題是訓練不穩定,又容易出現模式崩潰。第二代是 VAE(變分自編碼器),把圖片編碼到潛在空間再解碼回來,訓練是穩了,但生成品質就有限。第三代就是 Diffusion Model(擴散模型),也是現在的主流架構,生成品質明顯把前兩代甩在後面。
Diffusion Model 的運作原理
Diffusion Model 的核心概念,意外地簡單。正向過程(Forward Process)就是一步步在圖片上加高斯噪聲,加到整張變成純隨機噪聲為止。逆向過程(Reverse Process)則是訓練一個神經網路,學會每一步「去掉一點噪聲」,從純噪聲一路還原出清晰的圖片。再加上文字條件(Text Conditioning),模型就能照著文字描述產生對應的圖片。
Text-to-Image 的技術架構
一個典型的文字到圖片系統,主要有三個組件:文字編碼器(像 CLIP 或 T5)負責把文字描述轉成語義向量;Diffusion Model 在潛在空間裡照著文字條件去噪、生成;解碼器(Decoder)再把潛在空間的表徵轉回像素空間的高解析度圖片。這三者配合得好不好,直接決定了生成的圖片跟文字描述對不對得上。
Google Imagen 的特色
Imagen 是 Google 的旗艦圖片生成模型,在 Vertex AI 上提供服務。跟其他模型比,Imagen 在文字-圖片對齊、照片寫實度,還有複雜場景的構圖上都表現得很好。它同時支援圖片生成(Text-to-Image)、圖片編輯(Inpainting / Outpainting)、風格轉換,還有超解析度放大這些功能。企業版本則內建安全篩選,擋掉不當內容。
時效提醒:Google 正逐步把主力圖片生成能力移往 Gemini 原生的圖片模型(Gemini Flash Image 系列,俗稱「Nano Banana」),Imagen 4 系列模型最快 2026 年 8 月中下架,官方建議新專案直接改用 Gemini 圖片模型。不過本文寫作當下 Imagen 4 仍可正常呼叫,這裡談的 Diffusion Model 原理對兩者都通用,不受影響。
實作重點
- 在 Vertex AI Studio 中使用 Imagen 模型進行文字到圖片的生成實驗
- 嘗試不同風格的 Prompt(寫實照片、插畫、3D 渲染),觀察模型的風格適應能力
- 測試 Negative Prompt(排除不想要的元素)對生成結果的影響
- 了解 Imagen 的使用限制:人物與臉孔生成由 personGeneration 安全設定控管(可允許成人臉孔,或以 dont_allow 完全停用)、內建版權保護機制
Lab 導讀
Lab 連結:Introduction to Image Generation — Google Cloud Skills Boost
這個 Lab 以技術原理講解為主,搭配視覺化的演示來說明 Diffusion Model 怎麼運作。測驗重點包括 GAN、VAE、Diffusion Model 三者的比較,還有 Forward / Reverse Process 的概念。建議特別搞懂一件事:Diffusion Model 為什麼在品質上贏過 GAN?關鍵就在於它訓練過程比較穩,多樣性也更好。
延伸學習
- 向量搜尋與嵌入技術 — Embedding 在圖片搜尋中的應用
- 圖片說明生成模型 — 從生成圖片到理解圖片的反向任務
- Gemini 多模態 RAG 文件檢索 — 多模態模型的進階應用
相關文章
您可能也會對這些文章感興趣
圖片生成技術導論
認識圖片生成的核心技術原理,從 GAN 到 Diffusion Model,理解 Google Imagen 的架構與應用場景
負責任 AI:可解釋性與透明度
學習讓 AI 模型決策過程可被理解的技術方法,掌握 Google Cloud Explainable AI 與 LIT 工具的實作
負責任 AI:隱私與安全
學習在 AI 系統中保護使用者隱私與確保安全的技術方案,涵蓋差分隱私、聯邦學習、資料遮蔽與 VPC 安全控管
