負責任 AI:公平性與偏差
課程概述
AI 公平性不是一個抽象的倫理議題。它有具體的技術定義、可量化的指標,也有可以實作的工具。這堂課從開發者的角度切入,先搞懂 AI 偏差是怎麼產生、怎麼一路傳下去的,再學會用 Google Cloud 的公平性工具來檢測和緩解,讓系統在上線前就先確認過對不同群體都公平。
你將學到
- 定義 AI 公平性的多種數學定義及其潛在衝突
- 識別偏差在 ML 管線中的五個注入點
- 使用 What-If Tool 進行互動式的偏差分析
- 運用 Fairness Indicators 產出公平性量化報告
- 設計偏差緩解策略:前處理、訓練中、後處理
核心概念
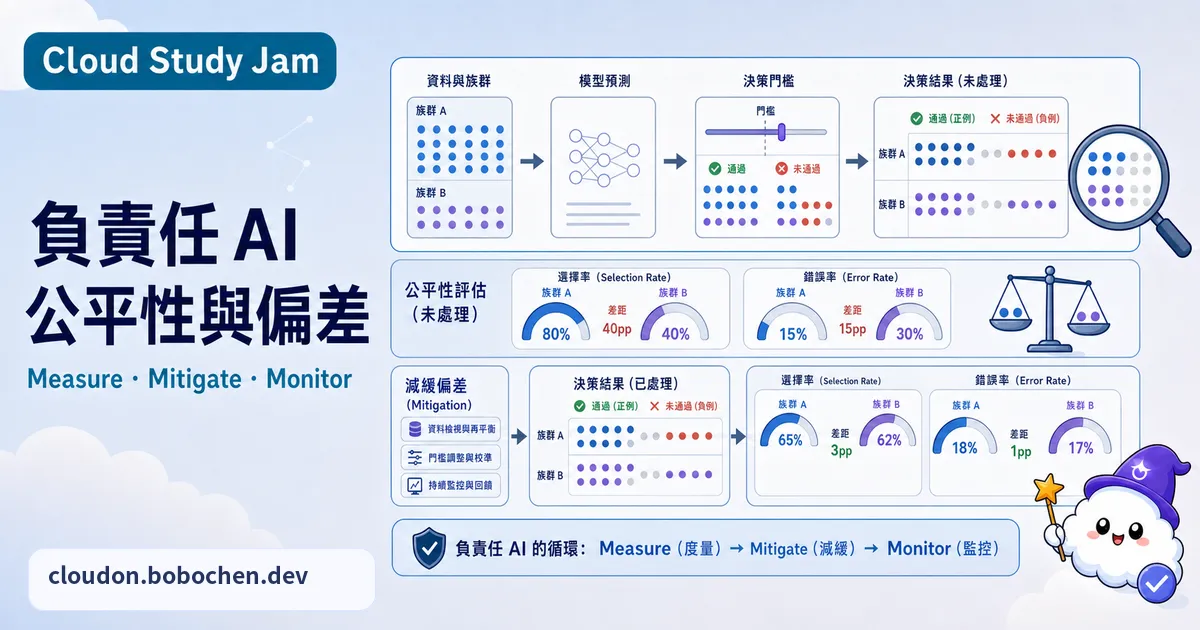
公平性的多元定義
AI 公平性沒有單一的正確答案,常見的數學定義有幾種:統計均等(Statistical Parity),各群體拿到正面預測的比例要一樣。機會均等(Equal Opportunity),各群體裡真正符合條件的人,被正確識別出來的比例要一樣。預測均等(Predictive Parity),各群體裡被預測為正面的案例,實際真的是正面的比例要一樣。麻煩的是,這幾個定義常常互相打架,滿足了一種,可能就違反另一種。所以開發者得看實際應用場景,挑一個最合適的來用。
偏差的五個注入點
偏差可能在 ML 管線的任何一個環節溜進來:(1)資料採集 — 採樣不均衡,導致某些群體被低估或高估。(2)資料標註 — 標註者的個人偏好影響到標籤品質。(3)特徵工程 — 用了帶歧視性的代理變數(例如郵遞區號間接反映種族)。(4)模型訓練 — 最佳化目標一個不小心就放大了既有的偏差。(5)部署環境 — 模型在不同使用情境下表現有落差。
What-If Tool(WIT)
What-If Tool 是 Google 做的互動式偏差分析工具,可以在 Vertex AI Workbench 或 TensorBoard 裡用。它能做幾件事:資料點視覺化,在多維空間裡看訓練資料的分佈長怎樣。反事實分析,改動單一特徵,看預測結果跟著怎麼變。切片分析,比較不同子群體的模型表現。還有閾值調整,看分類閾值一動,公平性指標會受到什麼影響。
Fairness Indicators
Fairness Indicators 是 TensorFlow 生態系裡的公平性評估程式庫。它會自動算出各種公平性指標,再用視覺化報表把不同群體之間的差異攤開來看。把它接進 TFMA(TensorFlow Model Analysis)管線,就能當成 CI/CD 流程裡的自動化公平性檢查步驟。
實作重點
- 在 Vertex AI Workbench 中載入一個分類模型,使用 What-If Tool 進行偏差分析
- 針對敏感屬性(如性別、年齡)計算 Statistical Parity 與 Equal Opportunity 指標
- 使用反事實分析,找出哪些特徵對預測結果的影響最大
- 嘗試三種偏差緩解策略:重新採樣(前處理)、正規化約束(訓練中)、閾值調整(後處理)
- 對生成式 AI 的輸出進行公平性審計:相同問題但改變性別/種族相關的描述,比較回答差異
Lab 導讀
Lab 連結:Responsible AI for Developers: Fairness & Bias — Google Cloud Skills Boost
這個 Lab 理論和實作都有,你會用 What-If Tool 和 Fairness Indicators 去分析一個真實資料集的公平性問題。操作時特別留意不同公平性定義之間的衝突,Lab 裡會讓你親眼看到「改善了一項指標,反而把另一項弄差」的狀況。這也是測驗的重點考點之一。
延伸學習
- 負責任 AI:可解釋性與透明度 — 讓偏差的來源可被理解
- 負責任 AI:隱私與安全 — 公平性之外的另一個 Responsible AI 面向
- Google Cloud AI 負責任原則實踐 — 回顧 Responsible AI 的整體框架
相關文章
您可能也會對這些文章感興趣
負責任 AI:公平性與偏差
深入學習 AI 系統中公平性與偏差問題的技術解方,掌握 Google Cloud 的 What-If Tool 與 Fairness Indicators 實作
負責任 AI:可解釋性與透明度
學習讓 AI 模型決策過程可被理解的技術方法,掌握 Google Cloud Explainable AI 與 LIT 工具的實作
負責任 AI:隱私與安全
學習在 AI 系統中保護使用者隱私與確保安全的技術方案,涵蓋差分隱私、聯邦學習、資料遮蔽與 VPC 安全控管
