先核對你報的是哪一種考試
截至本課更新日,Professional Cloud Architect 有 standard 與 renewal 兩種考試。第一次取得認證,或認證已過期,要考 standard;符合續證資格的 active certificate holder 才能選 renewal。
| 項目 | Standard | Renewal |
|---|---|---|
| 時間 | 2 小時 | 1 小時 |
| 題數 | 50–60 題 | 25 題 |
| 題型 | Multiple choice/multiple select | Multiple choice/multiple select |
| 費用 | USD 200,另加適用稅金 | USD 100,另加適用稅金 |
| 案例 | 每場 2 份,約占 20–30% | 每場 1 份,約占 90–100% |
| 內容 | 完整 standard exam guide | 以 GenAI solution case 為主的 renewal guide |
| 語言 | 英文、日文 | 英文、日文 |
兩種都可選 online-proctored 或 testing center,認證效期為兩年。Standard 沒有 prerequisite;Google 建議具有三年以上業界經驗,其中一年以上設計與管理 Google Cloud solution。
Google 沒有在官方頁面公布及格百分比。不要用網路流傳的 70% 或 75% 反推「可以錯幾題」,也不要把 practice exam score 當成正式考試換算表。
考試規格、語言、費用與 policy 都可能更新。報名前再看一次官方 certification page、exam guide、testing requirement 和 terms,而不是只看本課截圖或舊心得。
目前 standard exam guide 的範圍
官方 guide 目前分成六個 section:
| Section | 約略比重 | 核心能力 |
|---|---|---|
| Designing and planning | 25% | Business/technical requirement、WAF、network/storage/compute、migration、future improvement |
| Managing and provisioning | 18% | Network topology、storage、compute、Vertex AI workflow 與 prebuilt AI capability |
| Security and compliance | 19% | IAM、hierarchy、data/software supply chain/AI security、law/audit |
| Analyzing and optimizing | 15% | SDLC、troubleshooting、testing、DR、stakeholder、cost、business continuity |
| Managing implementation | 11% | Deployment、API management、migration tooling、CLI/SDK/IaC |
| Operations excellence | 12% | Observability、release、support、quality、reliability testing |
百分比適合安排複習,不適合在考場猜題。某一道 scenario 往往同時跨 security、reliability 和 cost;真正要判斷的是題目要求的 action。
一題先讀三種訊息
1. 動詞
題目要你做的是 assess、design、migrate、reduce、diagnose、secure,還是 choose first?
「降低未來維運」與「先恢復正在中斷的服務」即使背景一樣,答案也不會一樣。先確認行動,才不會選到一個長期很漂亮、但沒有處理眼前問題的方案。
2. 硬約束
特別留意:
must、required、cannot、existing、no plan to。- RTO/RPO、latency、protocol、data location、consistency。
minimize operational overhead、minimize cost、deadline、team skill。- 題目要求選幾項,以及是否要依順序。
「Minimize cost while meeting an RTO」要先滿足 RTO,再比成本;不能挑最便宜但無法復原的選項。
3. 成功條件
這個答案要讓什麼變好?是 user latency、deployment frequency、audit evidence、replica recovery,還是 model quality?若選項只新增工具,卻沒提供可量測的 improvement path,通常不是最直接的答案。
比較選項時問四個問題
對每個候選答案快速檢查:
- 它有沒有滿足所有 hard constraint?
- 它是否依賴題目沒提供的假設?
- 它新增多少 operation、migration 或 security burden?
- 有沒有更直接、較少步驟且容易驗證的選項?
Managed service 常能降低 undifferentiated operation work,但不是「愈 serverless 愈正確」。Cloud Run、GKE、Compute Engine 各自支援不同 lifecycle 與 control;CMEK、multi-cloud、service mesh、Spanner 也都要有需求才能合理。
同理,看到舊產品名稱不能直接判錯。題目可能考 migration from legacy、仍受支援的使用情境,或只是使用舊 branding。先判斷產品當期 lifecycle 與題目 action,再排除。
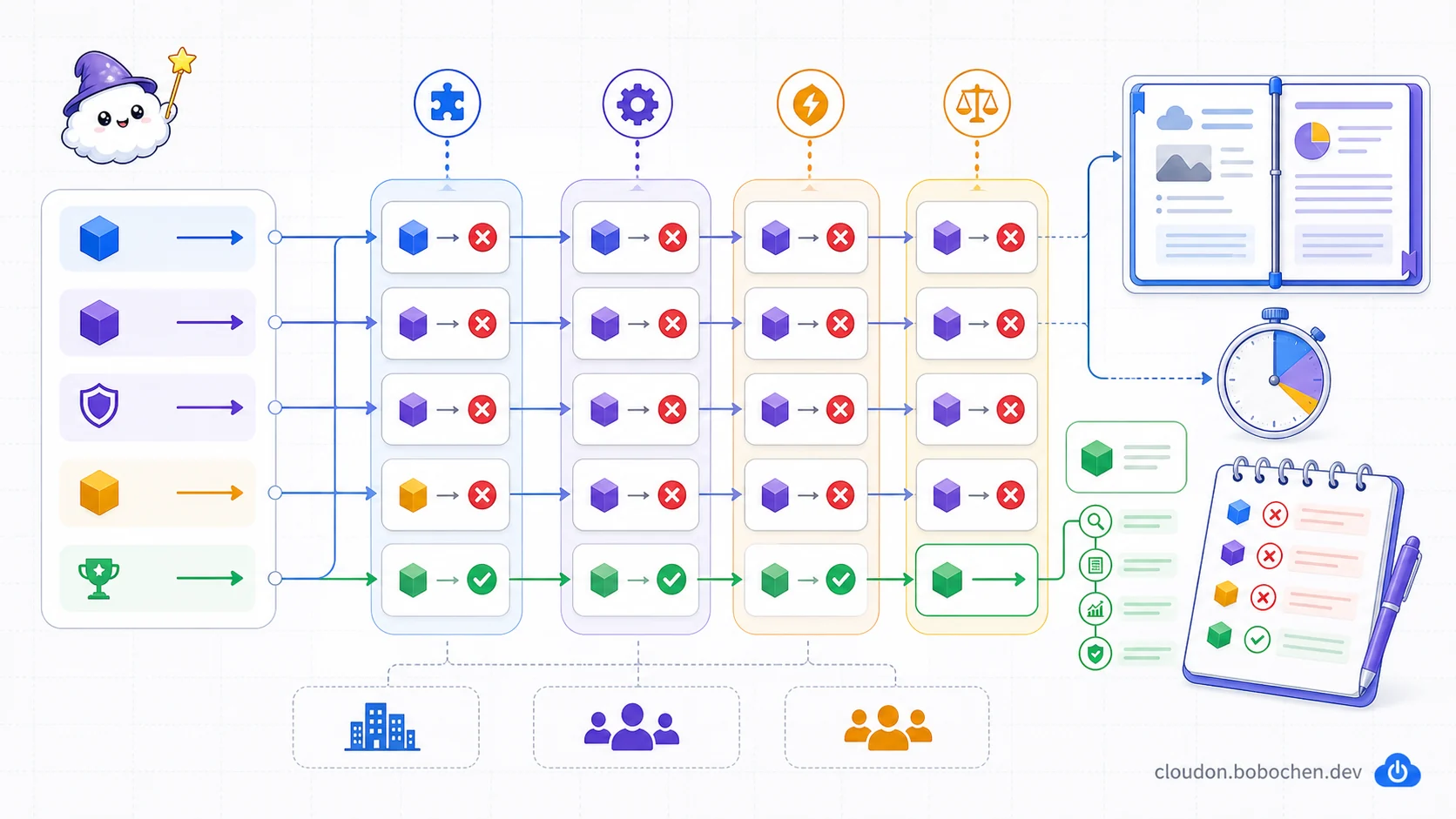
圖解:先抽出 action、hard constraint 與 success condition,再逐一檢查選項是否滿足需求、偷帶假設、增加管理負擔或存在更直接方案;錯題筆記要留下排除理由,而不只記答案字母。
FIRST 題沒有固定口訣
正常 modernization 通常先 discovery/assessment,再 plan、pilot、migrate;但 production credential 已外洩時,first action 可能是 disable/contain;服務正在大量重複扣款時,可能先停止有害 write path。
判斷順序:
- 現在是否有正在擴大的安全、資料或使用者傷害?有就先 containment。
- 是否缺少做決策的必要 evidence?缺少就先 assessment/measurement。
- 是否已有 approved design,只差執行?不要又回頭做無關 discovery。
- 這個動作是否可逆、blast radius 是否合理?
背「FIRST 永遠先評估」會在 incident 題失分;背「先修再說」則會在 migration planning 題失分。
案例題怎麼使用 split screen
考前先讀四份官方案例,但不必背每個句子。建立第 22 課的五格筆記即可。考試看到案例題時:
- 先讀 question 和 options,知道要回案例找什麼。
- 在 split screen 找對應 requirement/existing constraint。
- 不要把其他模擬題替案例補的背景帶進來。
- 同一案例換一題時重新確認 action,不能沿用上一題的答案方向。
例如 Cymbal 的 human-in-the-loop 是官方 technical requirement;「三國門市與 Oracle」則不是。只讓官方文字與這一題提供的額外資訊參與決策。
時間管理要先用模擬測驗校準
120 分鐘、50–60 題代表平均約兩分鐘上下,但每題難度不同。不要硬規定每題 90 秒或固定切成 80/30/10 分鐘;先做一次完整、計時的官方 sample/高品質 practice set,觀察:
- 一般題與案例題各自的 median time。
- 哪種題型最常重讀或改答案。
- 有多少題是知識不足,有多少是漏看 constraint。
- 最後需要多少時間檢查未作答與 multiple-select 數量。
考場可採兩輪:第一輪完成有把握的題,卡住時留下標記;第二輪只回到有明確疑點的題。不要因焦慮把每題全部重答。若介面顯示指定選項數量,離開前確認已選足;不確定時也不要空白。
原創模擬題 1:先處理正在發生的風險
一個 production service account key 被誤傳到公開 repository,audit log 顯示已出現未知來源的使用。公司已有 incident response plan。你首先該做什麼?
- A. 先完成整個 organization 的 IAM assessment
- B. 依 incident plan 停用 exposed credential、contain access,並保存調查證據
- C. 建立新的 custom role,等下次 release 一起部署
- D. 將所有 project 搬進 VPC Service Controls perimeter
答案:B。 已有 active compromise evidence,先 containment。A 是後續改善,C 延誤風險,D 也不會撤銷被竊 credential,且 VPC Service Controls 只保護支援服務的特定 data boundary。
原創模擬題 2:Migration 的第一個決策資料
公司要在六個月內把 200 台 VM 搬到 Google Cloud,希望保留 application 行為,現在卻不知道 dependency、utilization 與 license。哪個步驟最合理?
- A. 立即把所有 VM 改寫成 Cloud Run service
- B. 使用 discovery/assessment 蒐集 dependency、performance、compatibility 與 cost data,再分 wave
- C. 為所有 VM 購買三年期 CUD
- D. 先建立 multi-region GKE cluster
答案:B。 這裡沒有 active incident,而是缺少 migration plan 的必要 evidence。A、C、D 都在 workload disposition 尚未決定前承諾 target 或 spend。
原創模擬題 3:Cymbal 的生成內容流程
Cymbal 要從 supplier text/image 產生 product attribute。官方案例要求 associate 在 production catalog 更新前能 approve、reject 或 edit。哪個設計最符合需求?
- A. Model output 通過 JSON schema 後直接更新 production catalog
- B. 將 suggestion、source、model/prompt version 與 evaluation result 寫入 review store,核准後再由受控 workflow 發布
- C. 只把生成內容存到 log,讓 associate 有需要再搜尋
- D. 提高 model temperature,產生更多候選後自動選最長的一筆
答案:B。 Structured output 只保證格式,不保證 catalog fact 正確。B 把 human-in-the-loop、audit 與 release boundary 都納入;其他選項沒有滿足 review requirement。
原創模擬題 4:Cloud SQL 的跨區 DR
Cloud SQL primary 已使用 regional HA。團隊要防 region outage,能接受經核准的短暫 data gap,並要求定期量測實際 RPO/RTO。下列哪個方案最合理?
- A. 只增加同區 read replica,假設 region outage 時仍可用
- B. 建立 cross-region DR/read replica、監控 lag,測試 promotion/failover、client routing、reconciliation 和 failback
- C. 每天匯出一次 CSV,宣稱 RPO 為零
- D. 只調低 Cloud DNS TTL,不建立另一份 database
答案:B。 Regional HA 處理同區 zone failure;cross-region asynchronous replication 的 data gap 要靠 observed lag 與演練量測。DNS 本身不會建立資料副本。
原創模擬題 5:兩個答案都能跑時
小團隊要部署 stateless HTTP container,traffic 間歇性,沒有 Kubernetes API、daemon、special networking 或 long-running worker 需求,並要降低 platform operation。你會先選哪個?
- A. Self-managed Kubernetes on Compute Engine
- B. GKE Standard
- C. Cloud Run
- D. Bare Metal Solution
答案:C。 不是因為「serverless 永遠最好」,而是題目明確描述 request-driven container、缺少 Kubernetes-specific requirement,又把 operation burden 列為目標。若題目新增 Kubernetes policy/sidecar/special scheduling 等條件,結論可能改變。
錯題怎麼記才有用
不要只寫「正解是 Cloud Run」。每一題記五欄:
| 欄位 | 範例 |
|---|---|
| Tested decision | Request-driven container platform selection |
| Missed constraint | Minimize operation;無 K8s-specific need |
| My wrong assumption | 核心服務一定要用 GKE |
| Correct principle | 依 workload contract 與 operating model 選 compute |
| Source to review | Cloud Run/GKE official overview + 課程第 3、9 課 |
一週後只看題幹重新答,能說明其他選項為何不符合才算修正。若錯因是英文句型或漏選 multiple-select,改善方法是閱讀紀律,不是再背服務表。
考前與考試日
- 在官方 registration/testing page 完成設備、身分文件、空間與報到規則檢查。
- 最後幾天以錯題 pattern、case notes 和官方 guide gap 為主,不重讀所有文章。
- 睡眠與穩定作答比臨時多背一張 product table 更重要。
- 考試內容受保密條款約束,不使用、分享或購買 dumps;這些材料也可能過時或錯誤。
- 若未通過,依當期 retake policy 安排下一次,先用 domain feedback 和錯題紀錄調整學習。
本課檢查清單
- Standard 與 renewal 的內容差異很大,先確認自己符合哪一種資格。
- 官方未公布及格百分比,不用網路傳言計算容錯題數。
- 每題先找 action、hard constraint 和 success condition,再比較產品。
- Managed service、serverless、CMEK、multi-region 都不是無條件正解。
FIRST先判斷是否有 active harm;incident 與 planning 的順序不同。- 案例只使用官方原文與當題新增資訊,不引用模擬題補寫的背景。
- 時間分配用自己的計時資料校準,保留第二輪與漏答檢查時間。
- 錯題要記錯誤假設與決策原則,不只記答案字母。
延伸閱讀
- Professional Cloud Architect certification
- Professional Cloud Architect standard exam guide
- Google Cloud certification terms
下一步
最後一課會把課程、hands-on、案例與錯題 review 排成 8–12 週可調整路線。重點不是照表打卡,而是每週用 evidence 決定下一個弱項。
