AI 題目先別急著選模型
客戶說「想用 AI」,通常還不是一個能設計的需求。先把問題改寫成可衡量的任務:
- 是預測流失、辨識圖片,還是回答員工問題?
- 錯一次的代價是多推一件商品,還是做出錯誤醫療建議?
- 回答需要根據企業文件、即時網路資料,還是模型本身的通用知識?
- 結果要在數百毫秒內回來,還是每天批次跑完即可?
- 哪些資料可以進模型、必須在哪個區域處理、可以保存多久?
- 上線後用什麼指標判斷它仍然有用?
這些答案會決定你需要傳統 ML、生成式 AI、搜尋、規則引擎,或其實不需要 AI。
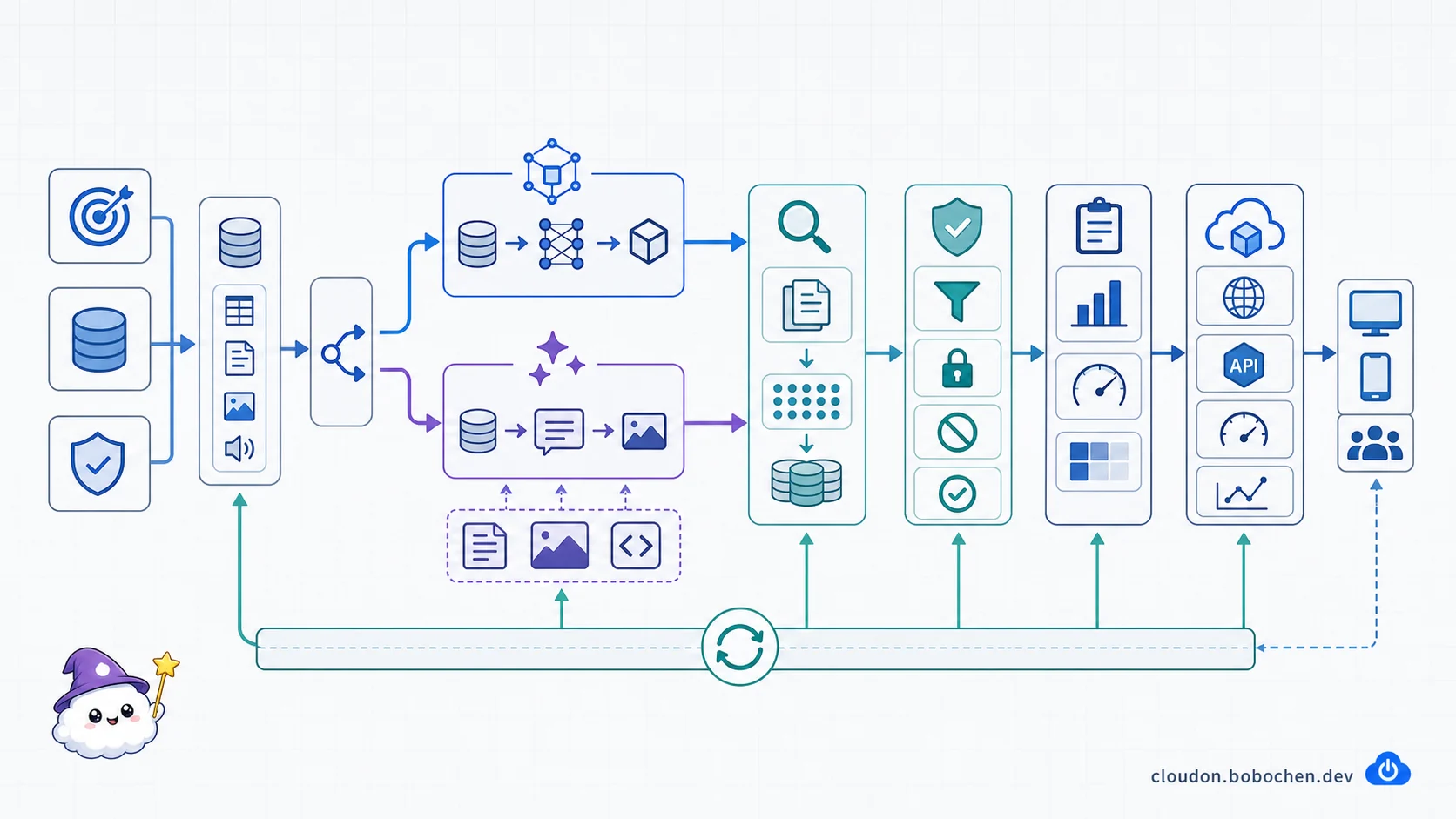
圖解:模型只是其中一站。完整 AI 架構還要處理可信資料與 grounding、安全控制、品質與成本評估、上線監控,以及把真實使用結果回饋到下一輪改進。
先分成兩條工作流
預測式 ML
分類、迴歸、預測和異常偵測,通常可以用這條生命週期來看:
- 準備、驗證與版本化資料。
- 選 AutoML、BigQuery ML 或 custom training。
- 用和業務代價一致的指標評估模型。
- 將可接受的版本登錄到 Model Registry。
- 做 online endpoint 或 batch prediction。
- 監控服務品質、資料偏移和模型表現,再決定重訓或回滾。
Vertex AI 仍是 Google Cloud 的 ML 平台,提供 training、experiments、Model Registry、endpoints、pipelines 等能力。不要把考綱中出現的新產品群名稱解讀成「所有 Vertex AI 元件都已改名」。產品名稱更新很快,架構責任反而比較穩定。
生成式 AI
生成式應用的工作流不同:
- 定義任務、失敗類型和人工評估標準。
- 建立代表真實問題的 evaluation set。
- 選模型、prompt、grounding 和 tools。
- 設計身分、資料權限、內容安全與拒答/轉人工流程。
- 評估品質、groundedness、安全、latency 和成本。
- 上線後保留 prompt/model version、trace、feedback 與異常監控。
只看一次 demo 的回答很漂亮,還不能證明系統可以上線。
AutoML、BigQuery ML 與 custom training
AutoML
AutoML 適合有標註資料、希望減少模型程式開發,而且問題落在支援資料類型的團隊。它會幫忙處理不少 training pipeline,但資料品質、label 定義、評估切分和部署決策仍由團隊負責。
BigQuery ML
資料主要在 BigQuery、團隊熟悉 SQL 時,可以先用 BigQuery ML 建立分類、迴歸、時間序列或其他支援模型。好處是少搬資料、驗證速度快。是否再登錄到 Vertex AI 或做線上 serving,要看模型類型與 latency 需求。
Custom training
需要自訂訓練程式、framework、distributed training 或特殊容器時,再使用 Vertex AI custom training。得到更多控制,也表示團隊要負責 dependency、reproducibility、資源配置和除錯。
選擇原則不是「無程式碼就 AutoML,有程式碼就 custom」。先看問題支援度、資料規模、精度目標、團隊能力和營運成本。
Gemini 與 Model Garden:模型只是系統的一部分
Vertex AI 的 Model Garden 提供 Google 與 partner/open models 的探索和部署入口。選模型時至少比較:
- 任務品質與支援 modality。
- Context、輸出格式、tool use 和 grounding 能力。
- Latency、throughput、quota 與費用。
- 資料處理條款、region availability 和版本生命週期。
- 團隊是否能在退役日前完成升級與回歸測試。
截至本課更新日,Gemini 型號仍持續演進,例如 gemini-3.5-flash。不要把一串 model ID 寫死在架構圖;應維護可替換的 model configuration、evaluation baseline 和升級流程,並在部署前查 Gemini model lifecycle。
高複雜推理不一定每次都要用最大模型。常見做法是先用較快、成本較低的模型處理大部分請求,再依任務風險或信心分數升級模型或轉人工。是否有效,仍要用自己的 evaluation set 驗證。
Prompt、grounding、RAG 和 tuning 怎麼分?
- Prompt:用清楚指令、範例和輸出格式改善任務行為,適合先做 baseline。
- Grounding:讓回答有可查證的外部依據,例如 Google Search 或企業搜尋資料。
- RAG:在回應前擷取相關企業內容,把文件權限、檢索和回答串起來。
- Tuning:調整模型的行為、格式或特定任務表現;不適合拿來頻繁更新事實資料。
如果客服回答需要每天更新的退貨政策,先做 RAG/grounding;如果要穩定輸出公司的分類格式,再評估 prompt、structured output 或 tuning。
Agent Search 是目前用來建立企業搜尋與 RAG 體驗的服務名稱,文件和部分 API 路徑仍可能保留較早的 Vertex AI Search/Discovery Engine 名稱。看到不同名稱時先對照產品文件,不要當成兩套完全不同的能力。
RAG 也不會自動消除幻覺。還要評估 retrieval recall、chunking、ranking、引用是否支持答案,以及沒有足夠證據時能否拒答。
什麼時候才需要 agent?
一般問答只需要檢索和生成;agent 則讓模型決定步驟並呼叫 tools,例如查訂單、建立退貨申請或安排會議。它帶來彈性,也增加新的失敗面:
- Tool permission 是否超過使用者原本權限?
- 參數是否經過 schema validation?
- 寫入或付款前是否需要確認?
- 失敗重試會不會重複下單?
- 多步驟執行是否有 trace、timeout 和成本上限?
能用固定 workflow 完成的高風險流程,不一定要交給 agent 自主規劃。可以讓模型做理解和建議,把關鍵寫入留給可預測的程式與人工核准。
安全控制要從風險出發
生成式 AI 沒有一組所有系統都必裝的「安全雙件組」。先做 threat model,再選控制:
- IAM 與 service account:限制誰能呼叫模型、讀資料和執行 tools。
- 資料權限過濾:RAG 不能因為建立索引就繞過文件原本 ACL。
- Model Armor:依支援情境檢查 prompt 和 response,例如 prompt injection 或不當內容風險。
- Sensitive Data Protection:偵測、分類或去識別化 PII 等敏感資料。
- VPC Service Controls、region 與 logging controls:依資料邊界和合規要求採用。
- 人工覆核與降級:高風險決策保留人工責任,並準備模型不可用時的流程。
Model Armor 和 Sensitive Data Protection 解的問題不同,也不是每個應用都必須同時使用。公開行銷文案、內部 HR 助手和醫療摘要的風險完全不同;控制應和資料、使用者、工具權限與錯誤代價匹配。
AI Hypercomputer:先算 workload,再挑硬體
AI Hypercomputer 是針對大型 AI/ML 與 HPC 工作負載整合運算、加速器、網路、儲存和軟體的系統。不要用一張很快過期的 GPU/TPU 規格表選型,先看:
- Training、fine-tuning 還是 inference?單機或 multi-host?
- Framework 與模型是否對特定 accelerator 有成熟支援?
- 模型、optimizer state 和 batch 需要多少 memory?
- 多節點工作時,network topology 和 storage throughput 是否成為瓶頸?
- 需要 on-demand、reservation、future reservation,還是可等待的彈性容量?
- 要用 GKE、Slurm、Cluster Director/Toolkit,還是直接管理 Compute Engine?
大型訓練常先卡在 capacity 和資料供應,不只在 accelerator 型號。正式規劃應做小規模 benchmark、估算 goodput,並提早處理配額和容量取得。可從 AI Hypercomputer overview 開始。
情境練習:客服助理真的要做什麼?
假設零售商要讓客服查政策、讀訂單並建立退貨申請。可以拆成:
- 知識回答:把版本化政策放入支援 ACL 的搜尋/RAG 資料來源,回答附引用,證據不足就拒答。
- 查訂單:透過受限 tool 讀取目前使用者有權查看的訂單,而不是把整個訂單資料庫塞進 prompt。
- 建立退貨:先由固定程式驗證期限、商品狀態和 idempotency key;最後一步請客服確認。
- 安全:依真實 prompt injection、PII 和 tool misuse 風險選擇 Model Armor、Sensitive Data Protection 與 IAM controls。
- 評估:離線測政策正確率、引用支持率與不當 tool call;線上看 escalation rate、處理時間、錯誤退貨和使用者回饋。
- 版本管理:model、prompt、retriever 和 tool schema 任何一項更動,都跑同一套 regression evaluation。
這個架構的重點不是 Agent Builder 圖示放在哪裡,而是每個錯誤都有控制和觀測點。
本課檢查清單
- 先定義任務、錯誤代價與評估方式,再選模型和平台。
- Vertex AI 仍涵蓋傳統 ML 的 training、registry、deployment 與 monitoring 工作流。
- 企業知識先評估 grounding/RAG;tuning 不用來保存每天更新的事實。
- Agent 適合需要動態規劃和工具呼叫的流程,但要限制權限、重試和高風險寫入。
- Model Armor、Sensitive Data Protection、IAM 和資料邊界應按 threat model 選用。
- AI Hypercomputer 的選型要連同 framework、memory、network、storage 和 capacity 規劃。
- 模型生命週期很短;可替換設定和 regression evaluation 是架構的一部分。
延伸閱讀
下一步
下一課會處理 IaC 與自動化。重點同樣不是背工具,而是讓每次基礎設施變更都能預覽、審核、回溯和安全執行。
