可觀測性不是把資料都收進來
一個服務通常會有 metrics、logs 和 traces,但資料很多不代表問題好查。真正要回答的是:
- 使用者現在能不能完成登入、搜尋、付款等關鍵流程?
- 哪一群使用者、哪個版本或哪個 region 受到影響?
- 問題發生在 application、dependency、configuration 還是最近的 change?
- On-call 收到通知後,有沒有明確動作可以做?
Metrics 適合看趨勢與聚合狀態,logs 補上離散事件與 context,traces 顯示一個 request 穿過哪些服務。Profiles、events、deployment metadata 和 business data 也常是重要證據。與其背「三大支柱」,更實用的做法是從 user journey 反推需要哪些 telemetry。
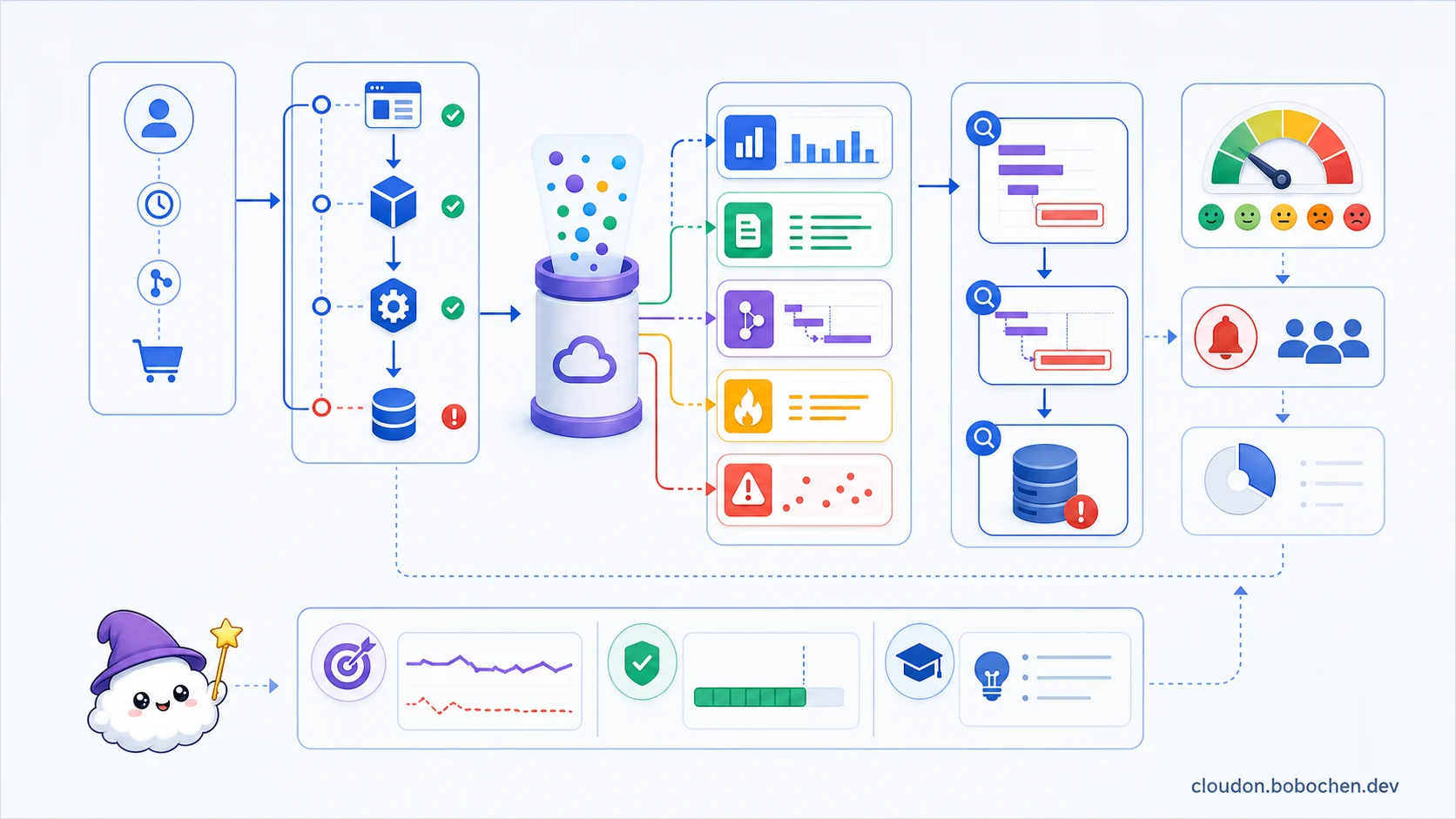
圖解:從使用者無法完成的旅程出發,用共同關聯資訊串起 metrics、logs、traces、profiles 與 errors,逐層縮小到真正瓶頸;SLI、SLO 與 error budget 再決定何時需要告警與人工行動。
先設計共同語言,再選收集方式
跨服務調查最常卡住的不是缺工具,而是每個團隊用不同欄位。至少統一:
- Service、version、environment、region/zone。
- Trace ID、span ID、request ID 或 business correlation ID。
- Operation、response class、dependency 和 deployment/release ID。
- Tenant 或 customer tier 等必要維度,但不要直接記錄個資或 secret。
Label/attribute 的 value 若近乎無限,例如 user ID、完整 URL 或 timestamp,會造成高 cardinality、查詢困難與成本上升。User-specific detail 可留在受控的 structured log,再用 trace 或 request ID 關聯,不要全部塞進 metric label。
OpenTelemetry 是預設起點
Google Cloud 建議使用 vendor-neutral instrumentation framework。Application metrics 和 traces 可優先用 OpenTelemetry;Prometheus client 適合既有 Prometheus metrics。Telemetry 可直接或經 OpenTelemetry Collector/Google-Built OpenTelemetry Collector 送到 Google Cloud。
Collector 方便統一 batch、filter、redaction、sampling 和 export,但它本身也會故障。要監控 queue、dropped telemetry、export error 和 resource usage,並確認網路中斷時的 buffer 行為。
不要假設部署到 Cloud Run 或 GKE 後,跨服務 trace 就會自動完整。Runtime 或 framework 可能提供部分 telemetry,但 application 仍要建立 span、傳遞 trace context,並確保 async job、Pub/Sub message 和 outbound client 沒有把 context 弄丟。
Cloud Monitoring:先看使用者症狀,再往下鑽
Dashboard 應該支援一個調查流程,而不是把所有圖塞在同一頁:
- User-facing SLI:成功率、latency、freshness 或 correctness。
- Traffic 與 saturation:request rate、queue age、connection、CPU/memory。
- Dependency:database、third-party、quota 和 network error。
- Change:deployment、configuration、feature flag 和 incident annotation。
Latency 不要只看 average。p50 能描述典型體驗,p95/p99 才容易看見 tail;但低流量時 percentile 也可能不穩定,必須同時看 sample count。
PromQL 與 MQL 的現況
新查詢應優先使用 PromQL 或 interactive query builder。Cloud Monitoring 的 PromQL 能查 Google Cloud system metrics、custom metrics 和 Managed Service for Prometheus 資料,但與 upstream Prometheus 在部分 rate、histogram 與 type handling 上有差異,搬移 query 後要驗證結果。
MQL 沒有關閉,既有 chart、dashboard 和 alert policy 仍可運作,也能透過 Monitoring API 建立。不過自 2025 年 7 月 22 日起,Google Cloud 已停止 MQL query 的 customer support,Console 也不能再用 MQL 新建這些資產。新教材與新系統不應把 MQL 當預設;既有 MQL 則要盤點用途、測試 PromQL replacement,再分批遷移。
Cloud Logging:保留能解釋事件的資料
Structured logging 比把文字串在一起好查。除了 severity 和 message,應包含 service、version、operation、error class 與 correlation field;但 payment token、credential、session cookie 和未遮罩個資不該進 log。
Log Router 可以依 filter 將 log 送往 Logging bucket、BigQuery、Cloud Storage 或 Pub/Sub。設計時分清目的:
- Logging bucket:operation search 與即時調查。
- BigQuery:需要 SQL、跨資料集關聯或長期分析。
- Cloud Storage:依 retention/archive 流程保存。
- Pub/Sub:串流到 SIEM 或其他 consumer;consumer 要處理 retry 與重複訊息。
第 14 課提過,_Required bucket 有固定保留規則,_Default 和 user-defined bucket 則有自己的 retention 設定。Exclusion filter 可降低低價值 log 的 ingest,但被排除後就無法回頭調查。先用 usage、incident history 與合規需求決定採樣和保留,不要直接丟掉所有 success log。
Log-based metric 適合把既有 log event 轉成可告警的 time series;如果這本來就是核心 SLI,通常應由 application 直接產生 metric,避免 log format 一改就讓監控失真。
Trace、profile 與 error 各自回答不同問題
Cloud Trace
Trace 能把 request 拆成 spans,顯示各 dependency 花費的時間。要讓它可用,必須:
- 在 ingress 建立或接收 trace context,跨 process/queue 繼續傳遞。
- Span name 穩定,不把 ID 放入名稱造成高 cardinality。
- 記錄有診斷價值且不敏感的 attributes。
- 在 application log 寫入正確的 trace/span reference。
- 用 sampling 控制成本,但保留足以調查錯誤與長尾的樣本。
Head sampling 在 request 一開始決定,簡單但看不到最後結果;tail sampling 能依完整 trace 決定是否保留,但需要 Collector 與額外資源。無論哪一種,都要用實際 traffic 驗證:低流量錯誤是否採得到?高流量時 exporter 會不會丟資料?
Cloud Profiler
Profiler 用來找程式碼層級的 CPU、heap 或 wall-time hot path。它適合回答「時間花在哪個 function」,不能取代 request trace。支援的 language、profile type 和 environment 會變動,導入前應查當期文件並先量測 agent overhead。
Error Reporting
Error Reporting 會分析支援格式的 error log/exception,將相似事件分組,方便看新出現、重現與受影響版本。Grouping 是調查入口,不是完整 incident signal;同一個 root cause 可能形成多個 group,反過來相似 stack trace 也未必有相同 business impact。通知方式也要依目前支援的 Monitoring/notification integration 設定,不要假設任一第三方 channel 都能直接使用。
從 user journey 定義 SLI/SLO
三個名詞先分清楚:
- SLI:實際量測的服務品質,例如成功 request 比例。
- SLO:在一段期間內希望 SLI 達到的內部目標。
- SLA:對外承諾與未達標後果,通常牽涉商務或法律條款。
先找真正會影響使用者的 journey,再定義 good event 和 valid event。以結帳為例:
availability SLI = 成功完成且非使用者輸入錯誤的結帳 / 有效結帳嘗試
latency SLI = 在 800 ms 內成功完成的結帳 / 成功結帳Availability 和 latency 可以建立成兩個 SLO,讓 failure mode 更清楚;也可以定義「成功且夠快」的單一 good event,但要確認團隊理解分母與診斷方式。不要直接用 load balancer 的所有 2xx 當成功,因為 application 可能回 200 卻沒有完成交易;也不要把明顯的 client validation error 全算成服務故障。
SLO 不是愈高愈專業。目標要根據 user expectation、dependency、cost 和可實現的 operation model 設定。100% 有時確實是必要的 business aspiration,但通常不能靠單一 production metric 保證;架構師應說明限制、failure semantics 和補償流程,而不是背一句「100% 一定錯」。
Error budget 把可靠性變成決策資料
若 30 天 SLO 是 99.9%,error budget 是該期間 valid events 的 0.1%,不是固定幾分鐘停機。Traffic 不均、partial failure 或 latency violation 都會影響消耗方式。
Burn rate 表示目前消耗 budget 的速度。Rate 為 1 代表照這個速度走,剛好在 SLO window 結束時用完。Fast-burn 和 slow-burn alert 可兼顧快速大故障與緩慢退化;Google SRE Workbook 的 multi-window/multi-burn-rate 參數可以作為起點,但必須依 traffic、on-call 能力和 false-positive data 調整。
Error budget policy 要先約定:
- 哪些 release 或 experiment 在 budget 健康時可以進行。
- Budget 快速消耗或已耗盡時,哪些 change 需要暫停。
- Security fix、regulatory change 和 emergency repair 如何例外處理。
- 誰能做決策、何時 review,以及恢復正常發佈的條件。
這不是由監控系統自動宣布「全公司停止發版」,而是產品與工程共同同意的風險政策。
告警只應在人需要採取行動時打斷人
每一個 page 都要能回答:使用者影響是什麼、為什麼現在需要人、第一個安全動作是什麼?
- Page:正在發生或即將發生重大 user impact,需要立即處理。
- Ticket:尚不緊急,但若不處理會累積風險或耗盡 budget。
- Dashboard:用來探索與 capacity planning,不必每個異常都通知。
優先對 symptom 和 SLO burn 告警;CPU、disk、replica lag 等 cause metrics 用於診斷,只有在它本身需要立即動作時才 page。Notification channel、ack、escalation 和 ownership 要定期測試,runbook 連結也要能從 alert 直接取得。
低流量服務要特別小心:一筆失敗就可能呈現極高 burn rate。可以合併相似服務、使用 synthetic traffic,或調整 window/SLO,但不要為了安靜而忽略真實高價值交易。
Incident response 與 postmortem
重大事故需要清楚角色:Incident Commander 負責協調與決策,operations lead 執行調查和緩解,communications lead 對內外更新。角色名稱可以調整,但避免所有人同時改 production,卻沒人記錄 timeline。
先止血,再完整找 root cause。恢復後的 blameless postmortem 應記錄:
- 使用者影響與實際 SLO/SLA 結果。
- Detection、response、mitigation 和 recovery timeline。
- 哪些技術與組織條件讓故障發生或擴大。
- 哪些防線有效、哪些假設錯誤。
- 有 owner、priority 和 due date 的 action items。
「提醒工程師更小心」通常不是有力的改善。較好的項目是補 contract test、限制 blast radius、改進 rollout verification 或自動檢查危險設定。Toil 也不必硬套固定比例;持續量測重複手工作業、incident interruption 和 automation ROI,再決定先消除哪一項。
情境練習:部署後結帳變慢
新版本上線後,結帳 p95 從 300 ms 上升到 1.2 秒,但 CPU 沒有明顯變化。
- SLO burn alert 顯示 latency journey 受影響,先確認 region、version 和 customer tier 分布。
- Deployment annotation 顯示問題與新 release 同時開始,on-call 依 runbook 暫停 promotion。
- 從 exemplars 或高延遲 trace 進入 request path,發現 inventory span 變慢。
- 關聯 structured log 後,看到新版本每件商品都各查一次 database;Profiler 也顯示 ORM mapping 消耗增加。
- 團隊先回滾 compatible application revision,確認 latency 和 burn rate 恢復,再修正為 batch query。
- 事後補上 production-like query-count test、canary latency gate,並檢查 trace sampling 是否能穩定捕捉長尾。
這條路徑的重點不是「Monitoring → Logging → Trace」一定照順序,而是每一份 telemetry 都能用共同 attributes 快速交叉驗證。
本課檢查清單
- 從 user journey 和要回答的 operation question 反推 telemetry,不追求全收。
- OpenTelemetry/Prometheus 是 instrumentation 起點;Collector 自己也要被監控。
- 新 Monitoring query 優先使用 PromQL;MQL 可繼續執行,但已不是建議的新建路徑。
- 統一 service、version、region、release 和 correlation attributes,並控制 cardinality 與敏感資料。
- SLI 要定義 good/valid event;SLO 與 SLA 不是同一份承諾。
- 用 error budget 和 burn rate 管理風險,參數要按 traffic 與 on-call data 調整。
- Page 必須對應即時行動;cause metrics 多半用來診斷,不必全部叫醒人。
- Postmortem 的 action item 要改進系統防線,並追蹤到完成。
延伸閱讀
- Instrumentation and observability
- PromQL for Cloud Monitoring
- MQL deprecation details
- Google SRE Workbook: Alerting on SLOs
下一步
下一課會把可靠性目標延伸到 zone、region、資料毀損與人為操作等失敗模式,設計能實際演練的 HA/DR 計畫。
