「系統很慢」還不是可調校的問題
先把抱怨翻成可量測的目標:哪一個 user journey、哪個 percentile、在哪個負載和地區,超過多少 latency?
例如:
台灣登入使用者在每秒 2,000 次結帳請求時,建立訂單 API 的 p99 server latency 應低於 800 ms,錯誤率低於 0.5%。
接著把 800 ms 拆成 latency budget:edge/load balancer、application、database、third-party 和 queue 各能用多少。用 trace 找 critical path、用 profiler 找 CPU hot path、用 metrics 看 saturation、用 logs 補事件 context。CPU 80% 不是通用故障門檻;某些 workload 在 90% 仍穩定,另一些在 40% 已因 single-thread 或 connection pool 卡住。
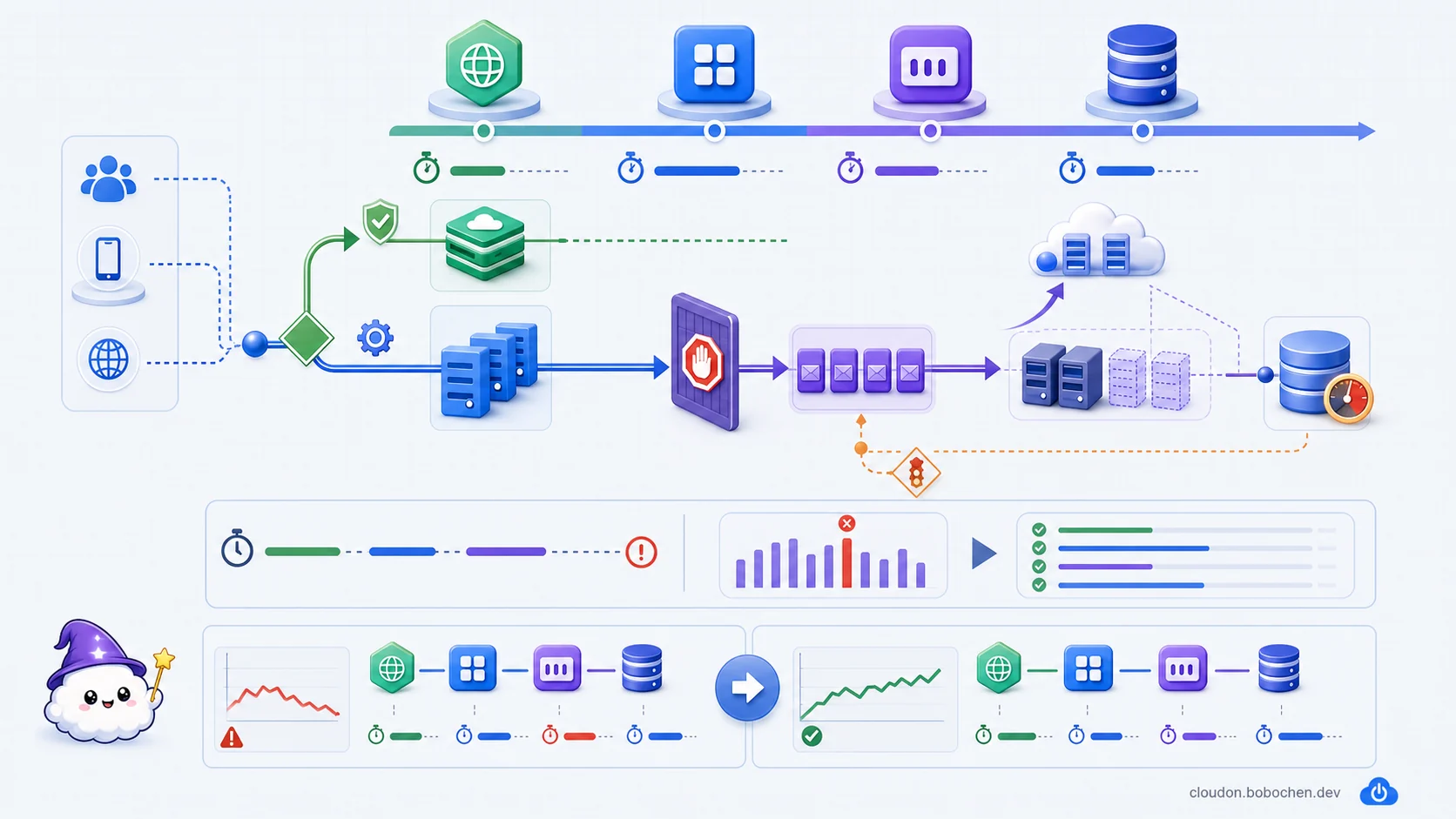
圖解:先把 latency budget 分配到各段,再讓可共用內容走快取、動態工作走應用路徑;流量暴增時先用 backpressure 控制進入下游的速度,之後才談擴展與瓶頸調校。
先建立 baseline,再做單一變更
效能實驗至少記錄:
- Traffic shape、request size、cache warm/cold、read/write ratio。
- p50、p95、p99 latency 和 timeout/error rate。
- CPU、memory、GC、thread、connection、queue depth、disk/network saturation。
- Downstream quota、rate limit 與 third-party latency。
- 每次實驗的版本、configuration 和成本。
一次只改一個主要變因,否則變快了也不知道原因。壓測還要有 soak、spike 和 failure test;短短五分鐘的平均 RPS 看不出 memory leak、autoscaling lag 和 retry storm。
Cloud CDN:快取前先定義資料是否能共用
Cloud CDN 能在 edge 回應 cacheable content,降低 user latency 和 origin load。三種主要 cache modes 是:
CACHE_ALL_STATIC:自動快取常見 static content,也尊重有效 origin cache directives。USE_ORIGIN_HEADERS:只有 origin 提供有效 cache headers 才快取。FORCE_CACHE_ALL:忽略 origin 的private/no-store等指令快取成功回應。
FORCE_CACHE_ALL 可能把個人化 HTML、API response 或 user-identifiable data 快取給其他人,不能只因 hit ratio 低就開啟。即使使用 signed URL,內容仍可能被 edge 快取;signed URL 控制存取時間,不代表內容不可共用。
Cache key 決定安全與命中率
Cache key 若包含所有 query、header 和 cookie,hit ratio 可能很低;排除太多,又可能把不同使用者的內容混在一起。設計前列出哪些 request attributes 真正改變 response,並測試:
- Authenticated 與 anonymous response 是否分開。
- Language、device、compression 和 experiment variant 是否影響內容。
Cache-Control、Vary、negative caching 和 serve-stale 行為。- TTL 到期與 invalidation 時,origin 能否承受 cache stampede。
Cache invalidation 是例外工具。常見做法是 versioned asset URL 搭配長 TTL,動態內容使用短 TTL 或 origin-controlled directives。
Memorystore:先選資料語意,再選 engine
Memorystore 目前包含 Valkey、Redis Cluster、Redis,以及已 deprecated 的 Memcached。新設計不應再把 Memcached 當預設候選。
選擇時看:
- Client/command compatibility 和需要的 data structures。
- 單一 instance 或 sharded cluster。
- Replica、zone distribution、failover 和 SLA 要求。
- Memory capacity、hot keys、eviction、persistence 與 recovery。
- Private connectivity、region 和 maintenance behavior。
Cache 要被視為可遺失或可重建,除非你明確選擇並驗證它作為 primary data store 的 durability semantics。即使有 replica,failover 也可能中斷 connection 或遺失尚未複寫的最新 write,client 必須 timeout、retry 並重新連線。
Cache-aside 的兩個難題
- Stale data:database 更新後,cache 何時 invalidate/refresh?
- Stampede:熱門 key 到期時,大量 request 是否一起打到 database?
可以用 TTL jitter、request coalescing、single-flight、serve stale 或 background refresh 緩解。任何 cache optimization 都要同時量 hit ratio、staleness 和 origin load。
Pub/Sub、Cloud Tasks、Scheduler 解的問題不同
Pub/Sub:發布事件給一個或多個 consumer
適合 producer 不需要知道所有 consumers 的 event distribution。Standard delivery 要假設 message 可能 redeliver,因此 consumer side effect 要 idempotent。
Exactly-once delivery 只支援 pull/StreamingPull subscriptions,並且 guarantee 受單一 cloud region 的 subscriber connection 條件限制。它能避免成功 ack 後重複 delivery,但 consumer crash、transaction boundary 和外部 side effect 仍需要自己的 idempotency/outbox 設計。
Ordering key 只保證相同 key 的順序,會降低可平行程度;dead-letter topic 也需要正確 IAM 與 retry 設定。不要為了「看起來更可靠」把所有訊息塞同一 ordering key。
Cloud Tasks:把一個 command 派送給指定 endpoint
Cloud Tasks 適合需要 queue-level dispatch rate、concurrency、schedule time 和精確 retry policy 的工作,例如控制第三方 API 或舊系統接收速度。Task ID 能在一定期間協助去重建立,但 execution 仍可能重試,handler 要 idempotent。
Cloud Scheduler:在時間點觸發
Scheduler 用 cron 呼叫 HTTP、Pub/Sub 或 App Engine target。Delivery 至少一次,因此「每日結算」不能假設只會執行一次;job 要用 business date/run ID 防重,並把長工作交給 job、workflow 或 queue。
簡單判斷方式:
- 多個 subscriber 對「已發生事件」反應:Pub/Sub。
- 要控制一個 endpoint 處理 command 的速度與重試:Cloud Tasks。
- 要在某個時間啟動流程:Cloud Scheduler。
Backpressure 比自動擴展更早救系統
上游能快速擴展,下游 database 通常不能無限增加 connection。系統需要 backpressure:
- API 設 admission control、quota 和清楚的 overload response。
- Queue 設 dispatch rate/subscriber flow control。
- Retry 使用 exponential backoff、jitter 和上限,避免 synchronized retry storm。
- Circuit breaker 在 downstream 故障時快速失敗或降級。
- Autoscaler 除了 CPU,也可看 concurrency、queue depth 或業務指標。
- Maximum instances/workers 保護 downstream capacity。
Queue 只會把尖峰延後,不會消除工作。Capacity planning 要比較 arrival rate 與 sustainable processing rate,估算 backlog 清空時間和 message retention。
Database:先修 query 和 connection
- 用 Query Insights/execution plan 找 slow query、lock 和 full scan。
- 建 index、partition/cluster,並確認 write amplification 和 maintenance cost。
- 控制 connection pool 大小;每個 autoscaled instance 都開一個大 pool,會很快耗盡 database connections。
- Cloud SQL Auth Proxy/connector 提供安全連線與 IAM integration,不負責 connection pooling。Pooling 要在 application、sidecar 或合適 pooler 處理。
- Read replica 能分擔允許 replica lag 的 read,不能拿來處理 read-after-write 或所有 transaction。
BigQuery 則要看 bytes scanned、partition pruning、shuffle、slot contention 和 concurrency。Reservation/edition 提供 capacity 管理,但 query design 仍然重要。
Gemini Cloud Assist:拿來縮小調查範圍
Gemini Cloud Assist 可以依支援功能協助理解 resource、log、metric 和建議。它適合快速整理可能原因或查詢入口,但不能取代 baseline、權限 review 和實驗。生成的 query、configuration 或調校建議都要由工程師驗證,尤其不要讓自然語言建議直接修改 production。
在架構上,應先確認它能看哪些 project data、誰能使用,以及互動如何留存和稽核。AI 助手能降低查資料時間,但最終證據仍是 telemetry 和可重現實驗。
情境練習:限時搶購
假設流量會在一分鐘內上升數十倍:
- 用 production-like load 重播登入、瀏覽、下單比例,找第一個 saturation point。
- Static assets 經 CDN,以 versioned URL 和正確 cache headers 減少 origin load;不快取購物車和個人化回應。
- Admission layer 依帳號/商品 rate limit,過載時回傳可重試但有 jitter 的 response。
- 下單 request 先產生 idempotency key;database transaction 或受控 reservation service 才是庫存 truth,不用單一 Redis decrement 當最終訂單依據。
- 若允許排隊,Cloud Tasks 依 database sustainable rate dispatch;使用者收到「排隊中」而不是假裝已下單成功。
- Notification 以 Pub/Sub event 解耦,email consumer 重試不影響訂單 commit。
- Autoscaling 設 minimum/maximum 和 downstream connection budget;活動前預熱並做 failover test。
- Dashboard 同時看 p99、error、queue age、inventory conflict、DB connection 和 CDN hit ratio。
本課檢查清單
- 先把效能需求寫成 user journey、percentile、load 和 region,再拆 latency budget。
- CPU 百分比不是通用答案;用 trace、profile 和 saturation 找真正 bottleneck。
- CDN cache key/mode 錯誤可能洩漏個人化內容,安全和 hit ratio 要一起測。
- Memorystore engine 要按 compatibility、sharding、HA、eviction 和 recovery 選。
- Pub/Sub、Cloud Tasks、Scheduler 都可能重試,consumer/handler 必須 idempotent。
- Exactly-once 有 subscription type 與 region 條件,不等於外部 side effect 自動 exactly once。
- Autoscaling 前先做 backpressure 和 downstream capacity budget。
- Cloud SQL Auth Proxy 不做 connection pooling;database scaling 先從 query 與 connection 著手。
延伸閱讀
- Cloud CDN caching overview
- Memorystore choices
- Pub/Sub exactly-once delivery
- Choose Cloud Tasks or Pub/Sub
下一步
下一課會談 API 與部署管理,從 consumer contract、auth、quota、版本相容性和 rollout verification 建立完整策略。
