「資料有 5 TB,所以要用哪個資料庫?」這個問題還太早。
5 TB 可以是不能修改的影片、需要 ACID 交易的訂單、依 Row Key 查詢的時序資料,也可以是每天掃描一次的分析事件。大小相同,存取方式完全不同。
資料選型先問的不是容量,而是應用怎麼讀、怎麼寫,以及寫錯時會造成什麼後果。
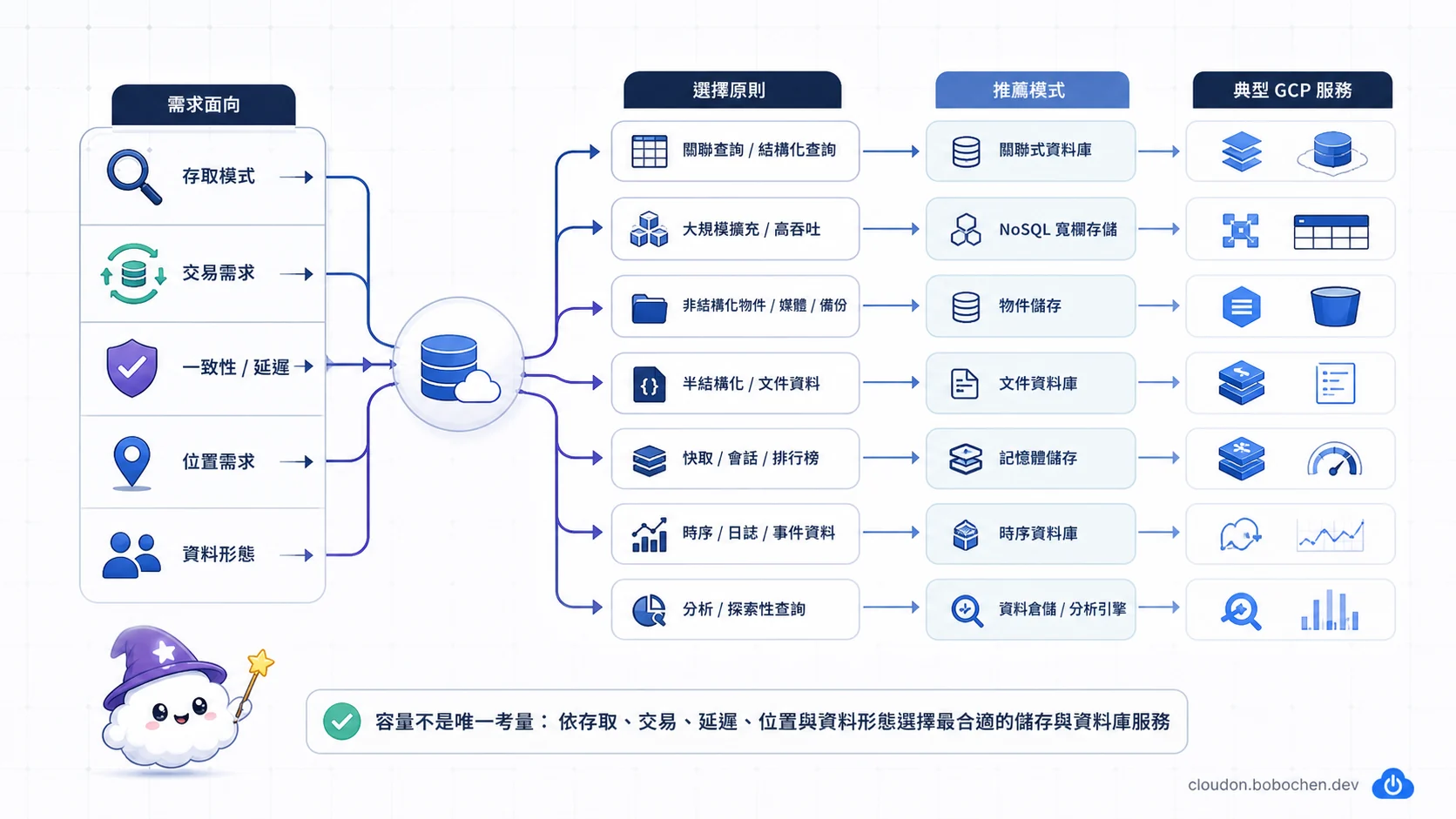
圖解:先用查詢方式、交易需求、一致性、資料位置與資料形態收斂,再比較關聯式、NoSQL、物件、檔案、快取、時序或分析型儲存;容量只是後續的規模條件。
先把需求拆成八個問題
- 資料是物件、區塊、共享檔案、文件、寬列,還是關聯式資料?
- 主要是單筆交易、Key 查詢、複雜 SQL,還是大範圍分析?
- 需要多列、多表 ACID 交易嗎?
- 寫入後多久必須讓其他讀者看見?
- 讀寫吞吐、熱點和延遲目標是什麼?
- 要部署在哪些區域,資料能否跨境?
- 備份、RPO、RTO 和保留期限是多少?
- 團隊需要多少 PostgreSQL、MySQL 或其他既有相容性?
回答完這些問題,候選服務通常會自然縮小。
物件、區塊和檔案不要混在一起
Cloud Storage:以物件為單位
Cloud Storage 適合圖片、影片、備份、匯出檔、資料湖和靜態資產。它提供 Object API,不是可以掛載後任意覆寫區塊的一般磁碟。
常用儲存類別如下:
| 類別 | 最低儲存時間 | 取回費用 | 常見思考方式 |
|---|---|---|---|
| Standard | 無 | 無 | 經常讀取或低延遲存取 |
| Nearline | 30 天 | 有 | 大約每月或更少存取 |
| Coldline | 90 天 | 有 | 大約每季或更少存取 |
| Archive | 365 天 | 有 | 長期保存、很少取回 |
「常見思考方式」不是強制頻率。要把儲存費、取回費、操作費、網路費與提前刪除費一起估算。
目前另有只用於 Rapid Bucket 的 Rapid storage class,適合特定高吞吐分析場景。它不是一般 Bucket 第五個隨意切換的歸檔層級。
Autoclass 和 Lifecycle 各有用途
- Autoclass:由 Cloud Storage 根據存取行為管理物件的儲存類別,適合難以預測的模式。
- Object Lifecycle Management:依年齡、版本或其他條件執行轉換與刪除,適合明確保留政策。
Autoclass 不是永遠最省,也有費用、功能與使用模式考量。如果其他服務會規律掃描 Bucket,存取行為可能讓自動分類不符合預期。
法規要求「保存七年」時,還要分清楚 Lifecycle、Retention Policy、Object Hold 和 Soft Delete 的作用。自動刪除規則不等於不可竄改的保留控制。
Persistent Disk 與 Hyperdisk:VM 的區塊儲存
區塊儲存適合 VM 開機磁碟、檔案系統與需要低層磁碟語意的應用。
選型要看:
- IOPS、吞吐量和容量
- 讀寫或唯讀掛載模式
- Zonal、Regional 與故障需求
- 快照、映像和備份策略
- 機器系列與區域是否支援
Hyperdisk 系列可以在適用類型中獨立配置效能與容量;Persistent Disk 仍有廣泛的相容性。產品類型和限制會更新,架構文件應記錄實際 Volume Type,而不是只寫「SSD」。
Filestore:NFS 共享檔案
Filestore 提供代管 NFS,適合需要 POSIX-like 共享檔案介面的應用,例如部分內容管理、共享工作目錄或傳統軟體。
若需求包含 SMB、多協定、特定企業檔案功能或更大規模,也應比較 Google Cloud NetApp Volumes 等選項。不要為了「多台機器要看同一份檔案」就立刻選 NFS;物件 API 或應用層資料服務可能更簡單。
關聯式資料庫:先確認相容性和擴展模型
Cloud SQL
Cloud SQL 代管 MySQL、PostgreSQL 和 SQL Server,通常適合:
- 既有應用依賴其中一種資料庫引擎
- 需要關聯式 Schema、SQL 與 ACID 交易
- 工作負載能在 Cloud SQL 的執行個體與擴展模式內運作
- 團隊想把備份、修補和 HA 基礎設施交給平台
Cloud SQL 仍需要資料庫管理:Schema、索引、慢查詢、連線池、容量、版本升級與復原演練不會自動消失。
規格上限依引擎、機器系列和區域而異,不要在架構文件寫死一個全服務通用的 vCPU 或記憶體上限。
AlloyDB for PostgreSQL
AlloyDB 是全代管、PostgreSQL 相容的資料庫,使用運算與儲存分離的架構,適合較吃重的 PostgreSQL 工作負載,例如:
- 高交易吞吐或多個讀取節點
- 在交易資料上執行分析的 HTAP
- 需要 Columnar Engine 加速分析查詢
- 使用 AlloyDB AI 做向量搜尋或模型整合
- 想保留 PostgreSQL 協定與工具
「PostgreSQL 相容」不代表遷移一定零修改。擴充套件、資料型別、旗標、權限、連線與查詢效能仍要用真實工作負載驗證。
官方效能數字來自特定測試條件,不應直接當成你的系統一定會快幾倍的承諾。先跑 PoC、負載測試和成本比較。
Spanner
Spanner 適合需要水平擴展的關聯式資料庫,並提供預設外部一致性(external consistency)的交易語意。
常見使用理由:
- 單一資料庫需要跨節點或跨區域擴展
- 需要關聯式 Schema 和強交易一致性
- 分片、複寫與重新平衡不想自行實作
- 業務規模與可靠性要求足以支持較高的架構成本
Spanner 的可用性 SLA 取決於 Edition 與 Instance Configuration。特定雙區域或多區域配置可達 99.999%,Regional Configuration 不是同一個數字。
跨區域強一致寫入也有物理延遲代價。讀者離副本近不代表全球寫入都會低延遲,必須依 Leader 位置、交易模式和使用者分布測試。
NoSQL:資料模型就是架構的一部分
Firestore
Firestore 是代管文件資料庫,適合:
- Web 或行動應用的文件資料
- 即時 Listener 與離線同步
- 依文件、集合與索引查詢
- 希望依請求成長,減少資料庫基礎設施管理
它提供強一致性,但查詢能力、索引、交易限制和計費模型與關聯式資料庫不同。把複雜 Join 關係硬塞進文件,可能把複雜度推回應用程式。
Bigtable
Bigtable 是寬列式 Key-Value 資料庫,適合大規模、低延遲、高吞吐的單一 Row Key 存取,例如部分時序、遙測、個人化或金融行情工作負載。
成敗通常取決於 Row Key 設計。遞增時間戳若直接放在 Key 開頭,可能造成熱點;查詢模式必須在建表前先設計。
一致性也不能只背一個答案:
- 單一叢集讀寫提供強一致性。
- 複寫後,跨叢集同步有延遲。
- 使用 Single-cluster Routing 可以維持較強的一致性語意。
- Multi-cluster Routing 通常換取可用性與就近路由,但跨叢集讀取可能看到舊資料。
要依 App Profile 和故障切換方式判斷,不是把整個 Bigtable 標成「最終一致」。
BigQuery:分析平台,不是交易資料庫
BigQuery 適合大範圍掃描、彙總、資料倉儲與分析型 ML。它不需要團隊管理資料庫叢集,並提供 On-demand 與 Capacity-based 等計費方式。
設計時要處理:
- Partitioning 與 Clustering
- 掃描量或 Slot 容量
- 資料更新和延遲需求
- 權限、列欄層級安全與資料遮罩
- 保留、刪除和區域位置
- BI、批次與串流工作負載隔離
「TB 級查詢一定幾秒完成」不是保證。查詢寫法、資料配置、併發和容量都會影響效能。
Dataflow、Dataproc 或其他處理服務可能負責把資料轉進 BigQuery,但它們是資料處理引擎,不是資料庫的替代品。
不要用資料量直接選產品
這張表比較接近實務判斷:
| 核心需求 | 優先評估 | 仍要確認 |
|---|---|---|
| 相容 MySQL、PostgreSQL 或 SQL Server | Cloud SQL | 規模、HA、版本與擴展 |
| 高要求 PostgreSQL、HTAP 或資料庫內向量能力 | AlloyDB | 相容性、PoC、區域與成本 |
| 水平擴展關聯式交易 | Spanner | Schema、交易延遲、配置與成本 |
| 文件、即時同步、行動或 Web 後端 | Firestore | 索引、交易與讀寫費用 |
| 高吞吐 Row Key 存取 | Bigtable | Row Key、App Profile 與一致性 |
| 大範圍分析和資料倉儲 | BigQuery | Partition、容量和資料延遲 |
| 不可變物件與資料湖 | Cloud Storage | 類別、保留、權限與 Egress |
同一個系統可以使用多種資料服務,但每增加一種就多一份同步、權限、監控和復原責任。不要為了畫出「完整資料架構」而無條件增加元件。
情境練習
商品與搜尋
需求:商品有關聯資料、複雜篩選、全文搜尋與推薦。
先把「主要交易資料」、「搜尋索引」和「推薦特徵」分開。Cloud SQL 或 AlloyDB 可能負責交易資料;全文搜尋是否留在 PostgreSQL,要用查詢能力與規模驗證,也可能需要專用搜尋服務。圖片則放 Cloud Storage。
不要因為需求提到 AI,就直接把所有資料放進向量欄位。
全球帳務
需求:跨區域交易、嚴格一致性、明確 RTO/RPO。
Spanner 是候選方案,但要先畫出交易邊界、資料位置、寫入 Leader、故障模式和成本。若其實每個地區帳務獨立,較簡單的區域資料庫也可能符合需求。
裝置遙測
需求:大量寫入、依裝置和時間範圍查詢,另有長期分析。
可以比較 Bigtable 作為低延遲查詢層、BigQuery 作為分析層、Cloud Storage 作為原始或長期保存層。是否三者都需要,要由查詢和保留需求決定;Dataflow 只是可能的傳輸與轉換選項。
課後檢查
你應該能回答:
- 為什麼資料量不足以決定資料庫?
- AlloyDB 的 PostgreSQL 相容性仍要驗證哪些項目?
- Spanner 的 SLA 為什麼不能只寫一個數字?
- Bigtable 在什麼情況下強一致,什麼情況可能讀到舊資料?
- BigQuery 和 Dataflow 在資料架構中各扮演什麼角色?
下一課會把選型拉回需求分析,練習把「快、穩、便宜、合規」改寫成可量測也可驗證的條件。
