先說清楚要防哪一種故障
「系統要高可用」還不是可以實作的需求。Instance crash、zone outage、region outage、資料誤刪、credential 洩漏、錯誤部署和上游中斷,需要的防線並不相同。
高可用(HA)通常讓服務在預期的 component 或 zone failure 下繼續運作;災難復原(DR)則處理超出主要 failure boundary 的事件,讓服務和資料回到可接受狀態。兩者會重疊,但不必硬分成「HA 一定自動、DR 一定手動」。實際切換方式要看產品能力、風險與授權流程。
先做 dependency map,列出每個 user journey 依賴的:
- Compute、database、object storage、queue 和 cache。
- DNS、load balancer、certificate、secret、KMS key 和 identity provider。
- Quota、artifact registry、CI/CD 與 control plane。
- Third-party payment、email、物流等外部服務。
只把 application 複製到第二個 region,database、secret 或 quota 還在單一 region,並不算完成 DR。
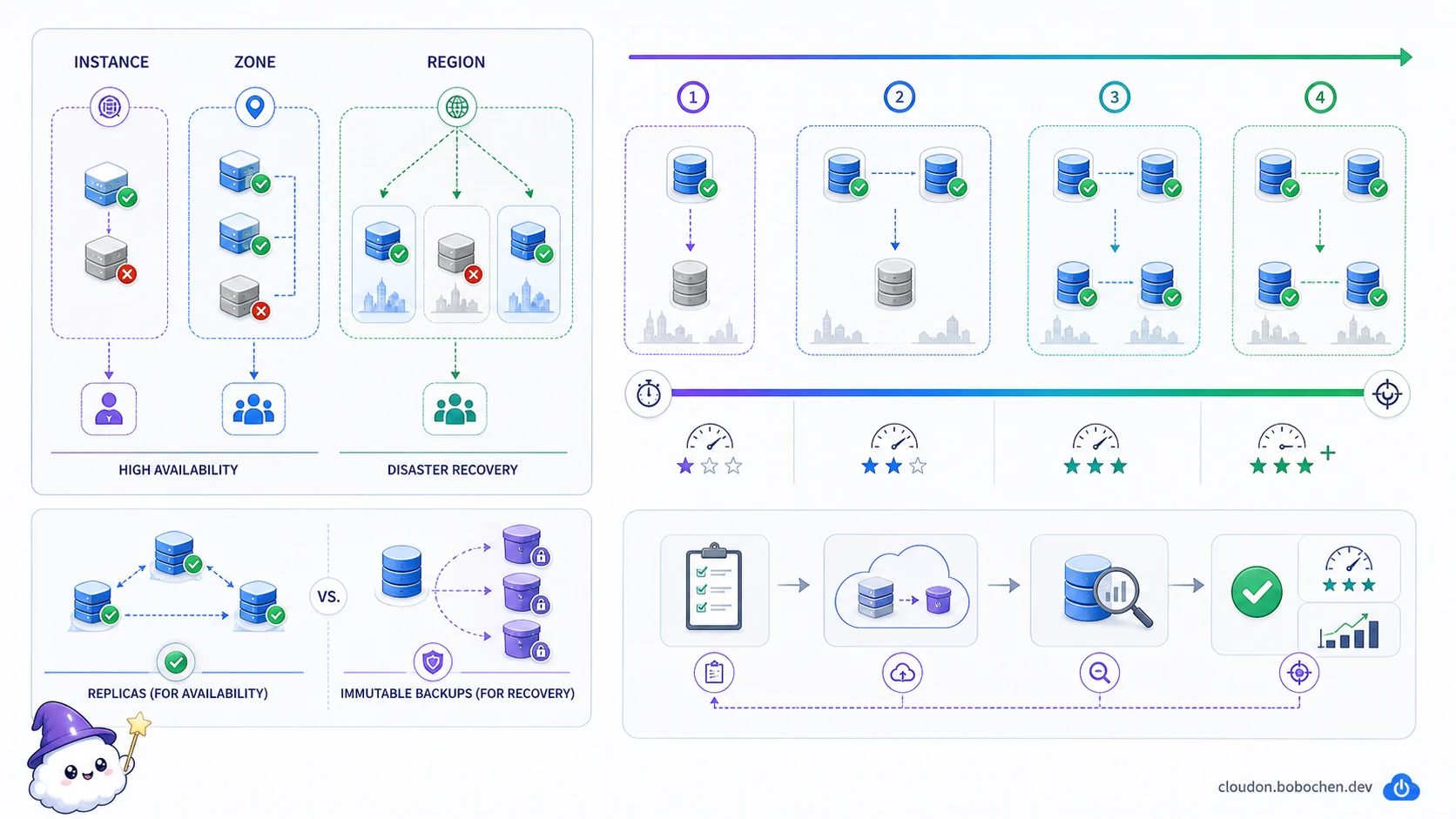
圖解:Zone 內的 HA 與跨 Region 的 DR 防的是不同故障邊界;就緒程度越高,復原通常越快但成本與複雜度也越高。Replica 支援可用性,immutable backup 才能處理誤刪或破壞後的復原。
RTO/RPO 要對一個業務流程定義
- RTO(Recovery Time Objective):中斷後,多久內必須把流程恢復到約定服務水準。
- RPO(Recovery Point Objective):恢復後,允許回到多早以前的資料狀態,也就是可容忍的資料遺失範圍。
例如「付款授權 RTO 15 分鐘、RPO 0;商品推薦 RTO 8 小時、RPO 24 小時」比「整套系統 RTO 15 分鐘」更有用。還要補上:
- Minimum service level:復原初期要能處理全部流量,還是只保留核心功能?
- Consistency requirement:可否暫時只讀、延遲寫入或事後 reconciliation?
- Maximum tolerable downtime:超過多久會造成不可接受的法規、財務或營運影響?
- Dependency objective:第三方服務的承諾是否比你的目標更寬鬆?
RPO 0 不等於題目一出現就選某個產品。要問「哪一種資料」不能遺失,以及 commit acknowledgement 的邊界在哪裡。Database transaction 可以跨區同步,尚未送出的 client request、cache、message consumer 的外部 side effect 和人工流程仍要另外處理。
Availability 數字要看產品、版本與配置
不要用「zonal 一律 99.9%、regional 一律 99.99%」推導架構。SLA 是產品與配置的承諾,不是 geography 自動附帶的數字。同樣叫 regional,Cloud SQL HA、regional GKE、Cloud Storage 和 Spanner 的 failure semantics 也不同。
正確流程是:
- 找到當期產品 SLA 與 architecture 文件。
- 確認 edition、region、replica、capacity 和 maintenance 等適用條件。
- 把所有關鍵 dependency 串起來估算 end-to-end availability。
- 用實際 failover 和 load test 驗證,而不是只看單項 SLA。
多一份 replica 也不保證有 capacity 接手。平常若兩個 zone 都已接近滿載,少一個 zone 時 autoscaler 可能拿不到 quota 或剩餘節點無法承擔流量。
四種 DR 策略是規劃語彙,不是固定時程表
| 策略 | 平時狀態 | 主要取捨 |
|---|---|---|
| Backup and restore | 只保留可還原的資料與 IaC | 成本低,但 provisioning、restore 與驗證會拉長 RTO |
| Pilot light | 核心資料或少量必要元件持續運作 | 比純備份快,仍要啟動其他 dependency |
| Warm standby | 第二站保留完整但較小 capacity | 切換較快,要持續 patch、同步與測試 |
| Multi-site | 多站同時服務或隨時能承接流量 | RTO 較短,但資料一致性、routing 與成本較複雜 |
名稱本身不能保證 RTO/RPO。Warm standby 能否在 15 分鐘內恢復,要看 database promotion、capacity scale-up、traffic switch、cache warm-up 和人工核准的實測結果。
Compute 與流量層的 failure boundary
Compute Engine 與 GKE
Regional managed instance group 可跨 zones 分布 VM,配合 health check、autohealing 和 load balancing 處理 instance/zone failure。Autoscaling 要保留 failover headroom 和 quota,並避免 state 留在 local disk。
Regional GKE cluster 讓 control plane 跨多個 zones,node pool 也要按需要分布。Topology spread、anti-affinity 和 PodDisruptionBudget 能改善 placement 與 planned disruption,但 PDB 不會增加 capacity,也不保護 region、cluster 或 dependency failure。跨 region 需要額外 cluster、artifact/configuration distribution 和 traffic/data plan;Fleet 提供跨 cluster 管理能力,不等於自動完成 failover。
Cloud Run
Cloud Run service 是 regional resource,區域內由平台處理 zone redundancy。若要防 region outage,必須在多個 regions 部署,並使用 global external Application Load Balancer 或 cross-region internal Application Load Balancer 連接 regional serverless NEGs。
僅把多個 NEG 掛到 load balancer,不一定會在 application error 時自動切換。可依當期功能使用 Cloud Run service health 建立 automated failover/failback,或設計 outlier detection/manual failover;無論哪種都要測試健康訊號、false positive、state 和 capacity。
使用 global anycast IP 時,正常切換通常不必修改 DNS。把 Cloud DNS 當成自動 application health failover 工具,常會忽略 record TTL、resolver cache 和 health-check 支援範圍。
資料層:replica、backup 與 archive 用途不同
Replica 能縮短故障後的資料恢復時間,但錯誤 delete、corruption 或 compromised credential 也可能被快速複寫。Backup 保留 point-in-time recovery copy,卻不一定能立即承接流量。Archive 著重長期保存,也未必能直接 restore 成 production service。
資料保護至少決定:
- Backup frequency、PITR window、retention 和 storage location。
- Application-consistent 或 crash-consistent 的需求。
- Encryption key 與 restore identity 是否在災難時可用。
- 誰能建立、刪除和 restore backup,是否要 separation of duties。
- Restore 到哪個 project/region,以及 network、DNS、secret 如何重建。
- 如何驗證 row count、business invariant 和 downstream reconciliation。
Cloud SQL
Cloud SQL regional HA 在同一 region 的兩個 zones 提供 primary/standby。符合條件的故障由服務自動切換,維持相同 IP,並保護 zone failure;不要對所有 database version/edition 承諾固定切換秒數。
Region failure 需要另一層設計。Cross-region read replica 使用 asynchronous replication,因此 lag 會隨 workload 與網路狀況改變。傳統 promotion 是有意識的手動/API 操作;Cloud SQL Enterprise Plus 的 advanced DR 可指定 DR replica 並提供額外 failover/switchover 流程,但仍要確認 engine、edition 與當期限制。
切換前後要處理:
- 量測 replica lag,判斷可能遺失哪些已 commit transaction。
- 防止舊 primary 恢復後繼續接受 write,避免 split-brain。
- 確認 promoted instance 的 machine size、HA、flag、user 和 network 足以承載 production。
- 更新 client routing/connection,並排空 stale connection pool。
- 重建 replication topology,規劃 failback 與資料 reconciliation。
Spanner
Spanner regional、dual-region 與 multi-region configuration 的 replica topology、edition、latency 和 SLA 不同。Dual-region 和 multi-region 能提供跨區的 strong/external consistency 與高可用能力;目前 dual-region 文件明確說明在支援的 region outage/network partition 情境下提供 zero RPO,但仍有 quorum mode、manual failover/failback 和 application placement 等操作考量。
選 Spanner 前要確認 relational model、transaction semantics、write latency、edition、region availability 與成本合適。即使 database RPO 是 0,application 也要部署在至少兩個 failure domains,message、object 和 external side effect 仍要各自設計。
Backup and DR 與不可變備份
Backup and DR Service 可集中管理 policy、monitoring 和 recovery。透過 Google Cloud Console 建立的 backup plan 目前支援 Compute Engine VM/disk、Cloud SQL、AlloyDB 等資源;其他 database 或 VMware workload 可能走 appliance management console。GKE 不在目前 Console backup plan 的支援清單中,cluster resource 和 persistent workload 要使用適合的 Kubernetes/application backup 策略,不能因為產品名稱有 DR 就假設全部支援。
Backup vault 是 Google-managed regional resource,提供 identity isolation、immutability 和 enforced retention。依 workload 與位置,可使用 regional、cross-regional 或 multi-regional vault;支援組合不同,例如 Cloud SQL backup plan 與 vault location 有特定相容限制。
設定 enforced retention 前要同時考慮:
- 期間內即使管理者也不能提早刪除,錯誤備份和大量資料仍會產生成本。
- Lock 生效後不能縮短 minimum retention,只能增加。
- Cloud SQL transaction log 等資料未必都存放在 vault 內,要讀各 workload 限制。
- CMEK、project isolation 和 restore permission 要在演練中驗證。
Immutable 不等於已驗證可還原。定期 restore 到隔離環境、執行 integrity/malware scan 和 application validation,才知道備份能否滿足 RTO/RPO。
Failover runbook 要處理的不只「切過去」
一份可執行的 runbook 至少包含:
- Declare:誰判定 region 已不可用?需要哪些 evidence 和 approval?
- Fence:如何停止或隔離舊 primary,避免兩邊同時寫入?
- Recover data:promotion、restore 或 replay 的順序為何?接受多少 lag?
- Scale:standby 的 compute、database connection、quota 和 license 是否足夠?
- Switch traffic:使用 load balancer、service health、DNS 或 client configuration 的哪一層?
- Validate:synthetic transaction、business invariant、security 和 observability 是否正常?
- Communicate:何時對客戶、管理層與監管單位更新?
- Fail back:原區恢復後如何重新同步、切回或決定不切回?
Automation 能縮短人工作業,但錯誤的自動 failover 也可能擴大事故。先確保 signal 足夠可靠、動作 idempotent、權限最小化,而且每一步能停下來檢查。
用演練取得真正的 RTO/RPO
DR 文件中的「預估 15 分鐘」不算驗證。演練要記錄:
- Detection、decision、data recovery、traffic switch 和 validation 各花多久。
- 最後一筆可驗證的 transaction 與實際資料缺口。
- Standby 在 production-like load 下的 latency、error 和 saturation。
- 哪些 IAM、quota、secret、certificate、artifact 或聯絡流程阻塞復原。
- Failback 是否安全,以及 replication topology 是否回到受保護狀態。
先在 non-production、單一 component 或少量 traffic 開始,控制 blast radius,再依風險逐步接近 production failure。演練頻率由 change rate、監管要求、criticality 和過往結果決定,不需要套用每月或每季的固定答案。重大架構、權限或 runbook 變更後,應重新測試相關路徑。
情境練習:台灣電商訂單服務
業務要求 region outage 後 30 分鐘內恢復下單;已確認可以接受少量 pending order 由客服與對帳流程補正,但 completed payment 不可重複扣款。
- 將 journey 拆成 browse、create order、authorize payment 和 notification,分別定義 RTO/RPO 與 degraded mode。
- Cloud Run 部署在台灣與日本,以 global external Application Load Balancer 連接 regional serverless NEGs;兩區都先測可承載的 failover capacity。
- Cloud SQL primary 使用 regional HA 防 zone failure,日本建立 cross-region DR replica。團隊不承諾固定 lag,而是以監控與演練取得 observed RPO。
- Payment request 使用 idempotency key;outbox/reconciliation 記錄用來處理 database 與 payment provider 間無法形成單一 transaction 的狀況。
- Region incident 時先 fence 舊 write path,再檢查 lag、執行 replica failover/promotion、更新 connection target,最後放入 synthetic order。
- Cloud SQL 另以 Backup and DR plan 寫入相容位置的 immutable vault,定期還原到隔離 project;backup 用來防 corruption/誤刪,不冒充即時 replica。
- Game day 報告記錄實際 data gap、切換時間與 capacity,若超過目標,再決定增加 automation、capacity,或改用更符合一致性需求的 database architecture。
這個方案沒有用「replication 通常只差幾秒」保證 RPO,也沒有用 DNS 更新假裝完成自動 failover。每個承諾都有 telemetry、runbook 和測試結果支撐。
本課檢查清單
- 先列 instance、zone、region、corruption、operator 和 security 等 failure modes。
- RTO/RPO 要針對 business journey 與 data class 定義,並包含 degraded service 與 consistency 要求。
- SLA 取決於服務與配置,不能用通用 zonal/regional 百分比代替。
- Replica 不是 backup;backup 也不代表已經測過 restore。
- Cloud SQL HA 保護同區 zone failure;cross-region async replica 的 RPO 取決於實際 lag。
- Cloud Run 多區需要 load balancing 與 health/failover 設計,單純多部署不會完成切換。
- Backup vault 提供 enforced retention,但 workload/location 支援與 log 保護範圍要逐項確認。
- Failover 要包含 fencing、validation、reconciliation 和 failback。
- 只有演練量到的 RTO/RPO,才能拿來檢查架構是否符合業務目標。
延伸閱讀
- Architecting disaster recovery for cloud infrastructure outages
- Cloud SQL availability
- Promote cross-region Cloud SQL replicas
- Serve Cloud Run traffic from multiple regions
- Backup vault concepts
下一步
下一課開始做 PCA case study。你會把 business requirement、technical constraint 和 operation risk 拆開,再用本課的 failure-mode 思考檢查候選架構。
