同一個容器可以跑在 Compute Engine、GKE 或 Cloud Run。技術上都能跑,不代表三個答案一樣好。
真正的差別是:團隊需要多少控制權,又願意承擔多少日常管理工作?
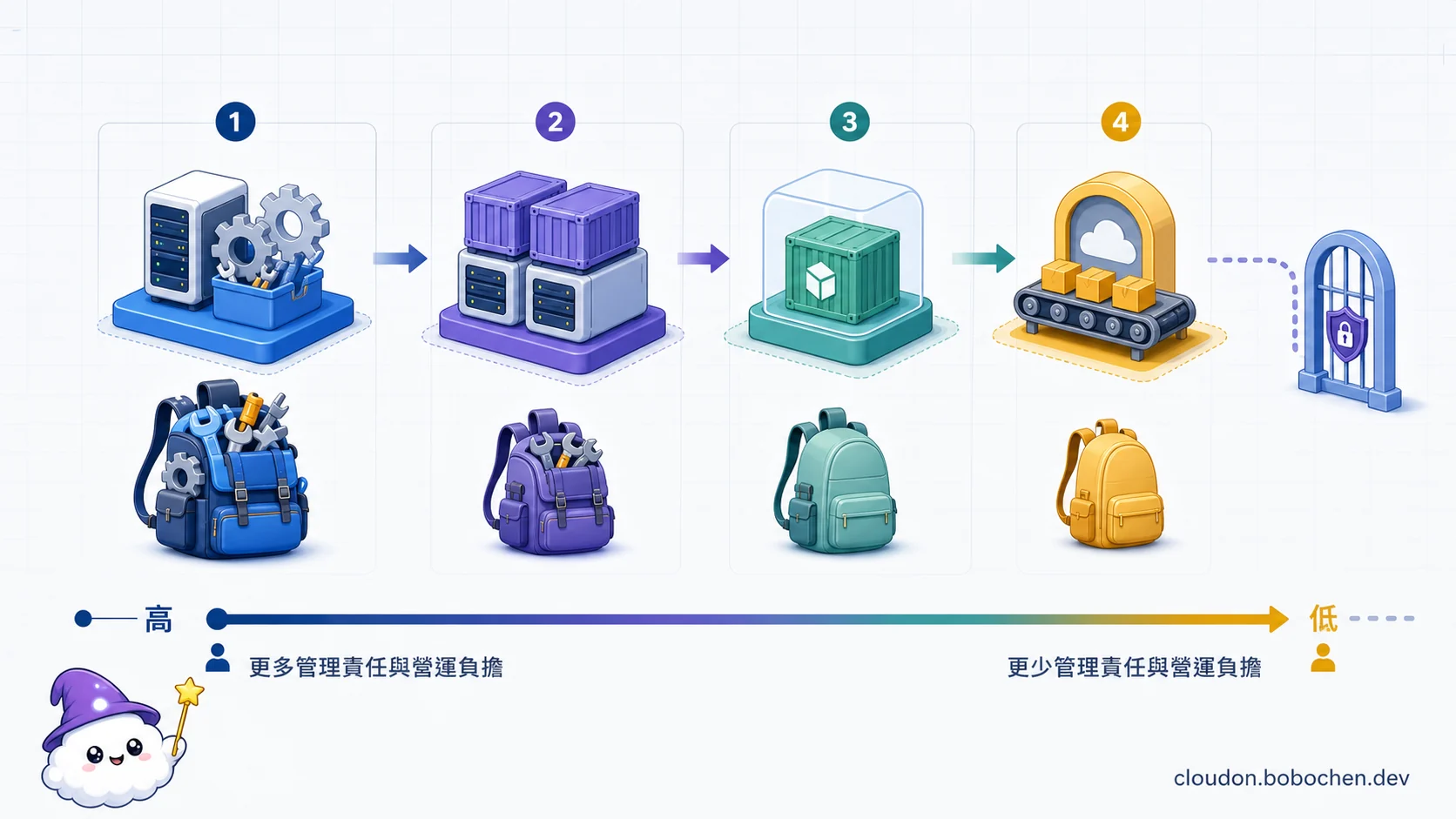
圖解:越靠近虛擬機,團隊握有的控制權越多,但作業系統、節點與更新責任也越重;越靠近代管平台,營運負擔下降,前提是需求沒有碰到平台邊界。
先看責任邊界
| 服務 | 團隊主要管理 | Google 主要管理 | 常見使用理由 |
|---|---|---|---|
| Compute Engine | VM、OS、修補、應用與拓撲 | 實體基礎設施 | 需要 OS、核心、特殊網路或既有 VM 相容性 |
| GKE | Kubernetes 工作負載與平台政策;Standard 還要管節點 | 控制平面;Autopilot 進一步管理節點 | 需要 Kubernetes API、生態系與複雜編排 |
| Cloud Run | 容器或原始碼、服務設定與應用 | 執行環境、實例生命週期與擴縮 | 想跑服務或工作,又不想管理叢集 |
| Cloud Run functions | 函式原始碼、進入點與觸發條件 | 建置、Cloud Run 執行環境與擴縮 | 單一用途的 HTTP 或 CloudEvent 處理 |
| Batch | Job 規格、映像與資源需求 | 批次排程與底層資源生命週期 | 非同步批次,不想自行維護排程叢集 |
| VMware Engine | VMware 內的 VM 與操作模式 | 專用 VMware SDDC 基礎設施 | 先保留 VMware 相容性與工具鏈 |
抽象層越高,通常越少基礎設施工作;但可調整的底層細節也會變少。這不是「越代管越好」,而是看需求是否真的需要那些控制權。
Compute Engine:需求碰到 VM 或 OS 邊界時
Compute Engine 適合:
- 商用套裝軟體只支援特定 OS
- 需要核心模組、特殊驅動或完整系統管理權限
- 現有 VM 要先 Rehost
- 授權綁定核心、主機或硬體隔離
- 網路設備、資料庫或舊式應用不適合容器化
架構師不只要選機器類型,還要設計:
- 單台 VM、Managed Instance Group,還是其他拓撲
- 跨可用區的故障承受能力
- 映像、修補與設定管理
- 啟動時間與自動擴縮
- 備份、狀態資料和復原
- 穩定容量、突發容量與 Spot VM 的比例
機器系列更新很快。與其背下每個型號,不如先依工作負載分成一般用途、運算密集、記憶體密集、儲存密集或加速器工作負載,再用壓力測試確認 vCPU、記憶體、網路和磁碟瓶頸。
Spot VM 不是單純的便宜 VM
Spot VM 可能被隨時終止,也沒有可用性保證。適合的工作必須能:
- 重試而不產生重複副作用
- 保存 Checkpoint 或切成較小工作單位
- 在容量不足時改用其他資源
- 容許完成時間波動
若工作中斷會讓資料損壞或錯過不可延後的截止時間,折扣再大也不是好選擇。
GKE:真的需要 Kubernetes 時再選
GKE 的價值在於 Kubernetes 的宣告式 API、排程和生態系,而不只是「可以跑容器」。
比較有理由使用 GKE 的情況包括:
- 團隊已有 Kubernetes 平台與操作經驗
- 工作負載需要自訂控制器、DaemonSet 或特定排程能力
- 多個服務需要一致的 Kubernetes 部署與政策
- 需要複雜的混合工作負載、加速器或平台擴充
- 組織已把 Kubernetes API 當成標準平台介面
如果只是幾個無狀態 API,而且團隊不想維護叢集,Cloud Run 通常值得先評估。
Autopilot 和 Standard
官方目前建議優先考慮 Autopilot,再確認限制是否符合需求。
| 考量 | Autopilot | Standard |
|---|---|---|
| 節點生命週期 | Google 管理 | 團隊管理節點池與更多設定 |
| 計費視角 | 依工作負載資源與適用費率 | 依節點及相關資源 |
| 預設安全與設定 | 較多預先配置 | 有更多自行設定空間 |
| 適用時機 | 想使用 Kubernetes,但減少節點管理 | 需要 Autopilot 不提供的底層控制 |
實際支援功能會持續更新。不能因為幾年前 Autopilot 不支援某項能力,就直接假設現在仍不支援;設計時要查當前的功能比較。
工作負載身分
GKE 工作負載存取 Google Cloud API 時,應優先使用 Workload Identity Federation for GKE,避免把長效服務帳戶金鑰放進 Secret 或容器映像。
Autopilot 會啟用這項能力;Standard 需要確認叢集和節點池設定。啟用身分機制不會自動授權,仍要替工作負載授予最小必要 IAM 權限。
Cloud Run:容器服務、工作與函式的代管平台
Cloud Run 可以執行:
- 接收 HTTP、gRPC 或 WebSocket 流量的服務
- 有開始與結束的 Cloud Run Jobs
- 以原始碼部署的函式
- 事件驅動處理,搭配 Eventarc 等服務
它常適合無狀態或把狀態放在外部資料服務的應用。容器內的本機檔案與記憶體不應被當成耐久狀態,也不能假設下一個請求一定回到同一個實例。
架構設計要確認:
- 請求、工作或背景處理模型
- 最大與最小實例
- Concurrency 與每個實例的資源
- 啟動延遲和下游連線數
- VPC 輸入、輸出與私有服務存取
- 逾時、重試、冪等性和任務取消
- 請求式或實例式計費是否符合負載
Cloud Run 可以縮到零,但有最小實例、特定計費設定或其他持續資源時仍會產生費用。「沒有流量就一定免費」不是可靠的架構假設。
Cloud Run functions:用函式程式模型部署到 Cloud Run
目前最新的 Cloud Run functions 會以 Cloud Run 服務執行。開發者使用 Functions Framework 定義一個 HTTP 或 CloudEvent 進入點,再由平台從原始碼建置和部署。
它和一般 Cloud Run 服務的差別比較接近開發模型:
- 函式:單一用途處理器、固定進入點、事件整合直接。
- 服務:完整 Web 應用、路由、中介層、自訂伺服器與容器控制較多。
Cloud Run 服務也能從原始碼部署,所以「不想寫 Dockerfile」已經不是選函式的充分理由。要看的是團隊要維護一個函式處理器,還是一個完整服務。
舊的 Cloud Functions v2 API 仍有相容路徑。看到舊教學時,先確認它使用 gcloud functions 還是目前建議的 Cloud Run 管理方式。
Batch:有終點的運算工作
影片轉檔、蒙地卡羅模擬、基因分析或大量非同步計算,不一定需要常駐 VM、Kubernetes 叢集或 HTTP 服務。
Batch 讓團隊描述 Job、Task、資源和重試,平台再準備 Compute Engine 資源執行。適合:
- 工作有明確開始與結束
- 可以切成平行 Task
- 需要 VM、GPU 或特定資源配置
- 想使用 Spot 等容量策略
- 不需要自行維護批次排程叢集
如果工作已經容器化、執行限制符合 Cloud Run Jobs,而且不需要 VM 級控制,Cloud Run Jobs 也可能更簡單。兩者要用執行時間、資源、排程、網路與維運需求比較。
VMware Engine:先保留相容性,不代表永遠不改
VMware Engine 適合大量既有 VMware 工作負載,需要保留 vSphere、vCenter、NSX 與既有操作模式的情況。
它可能縮短資料中心退出或第一階段遷移時間,但仍要驗證:
- 軟體與作業系統授權
- 網路延遲、IP 與相依系統
- 備份和災難復原
- 容量和最低部署規模
- 遷移後長期成本
- 哪些工作負載值得再現代化
「不用改程式」不等於「不用做遷移設計」。
一套比較耐用的選型順序
1. 先找硬性限制
- 必須保留 VMware 操作模式嗎?
- 需要管理 OS 或核心嗎?
- 必須使用 Kubernetes API 或特定控制器嗎?
- 工作是長期服務、事件處理,還是有終點的批次?
- 有沒有 GPU、TPU、驅動、授權或硬體隔離限制?
2. 從管理負擔最低的可行方案開始
若兩個方案都符合功能與 SLO,通常先評估營運負擔較低的方案,再確認成本、可觀測性與限制。這不是永遠選 Serverless,而是避免為了可能永遠不會用到的控制權,先建立一個平台團隊。
3. 用真實負載驗證
至少測:
- 啟動時間與 P95/P99 延遲
- 尖峰吞吐量與擴縮速度
- 下游資料庫連線
- 故障、逾時和重試
- 每個業務單位的成本
- 發布與回退流程
情境練習
舊式財務系統
需求:只能跑在特定 Windows Server 版本,授權與驅動尚未釐清,六個月內要退出機房。
先評估 Compute Engine 或 VMware Engine,並把授權、相依系統和測試結果列為遷移前置條件。此時直接改成容器不是已知答案。
小團隊的容器 API
需求:五個無狀態 API、流量波動大、沒有 Kubernetes 團隊。
Cloud Run 是合理起點。仍要測冷啟動、Concurrency、資料庫連線和最大實例,不能只憑「無狀態」三個字決定。
分散式訓練平台
需求:多節點 GPU 訓練、特殊網路拓撲與排程,已有平台團隊。
應同時評估 Vertex AI 訓練服務、Cluster Director、GKE 或 Compute Engine。AI 工作負載不會自動等於某一個通用運算產品,關鍵是框架支援、加速器、排程和團隊責任。
課後檢查
你應該能回答:
- 同一個容器放在 GKE 和 Cloud Run,團隊責任差在哪裡?
- 哪些需求足以讓你選 Compute Engine?
- Cloud Run functions 和一般 Cloud Run 服務現在主要差在哪裡?
- Spot VM 要求應用具備哪些能力?
- 為什麼「避免供應商鎖定」不足以直接選 GKE?
下一課會用同樣方法選資料服務:先看查詢、交易、一致性與營運需求,不用資料量大小直接猜資料庫。
