選到服務,只完成一半
知道容器可以跑在 GKE 或 Cloud Run,還不代表系統能承受正式流量。真正影響穩定度和成本的,往往是後面的配置:資源 request、擴縮訊號、更新時段、並行數、磁碟效能,以及工作被中斷時怎麼恢復。
這一課不提供一組「通用最佳值」。我們會練習一個更實用的流程:先寫出工作負載特性,再設定,再用資料驗證。
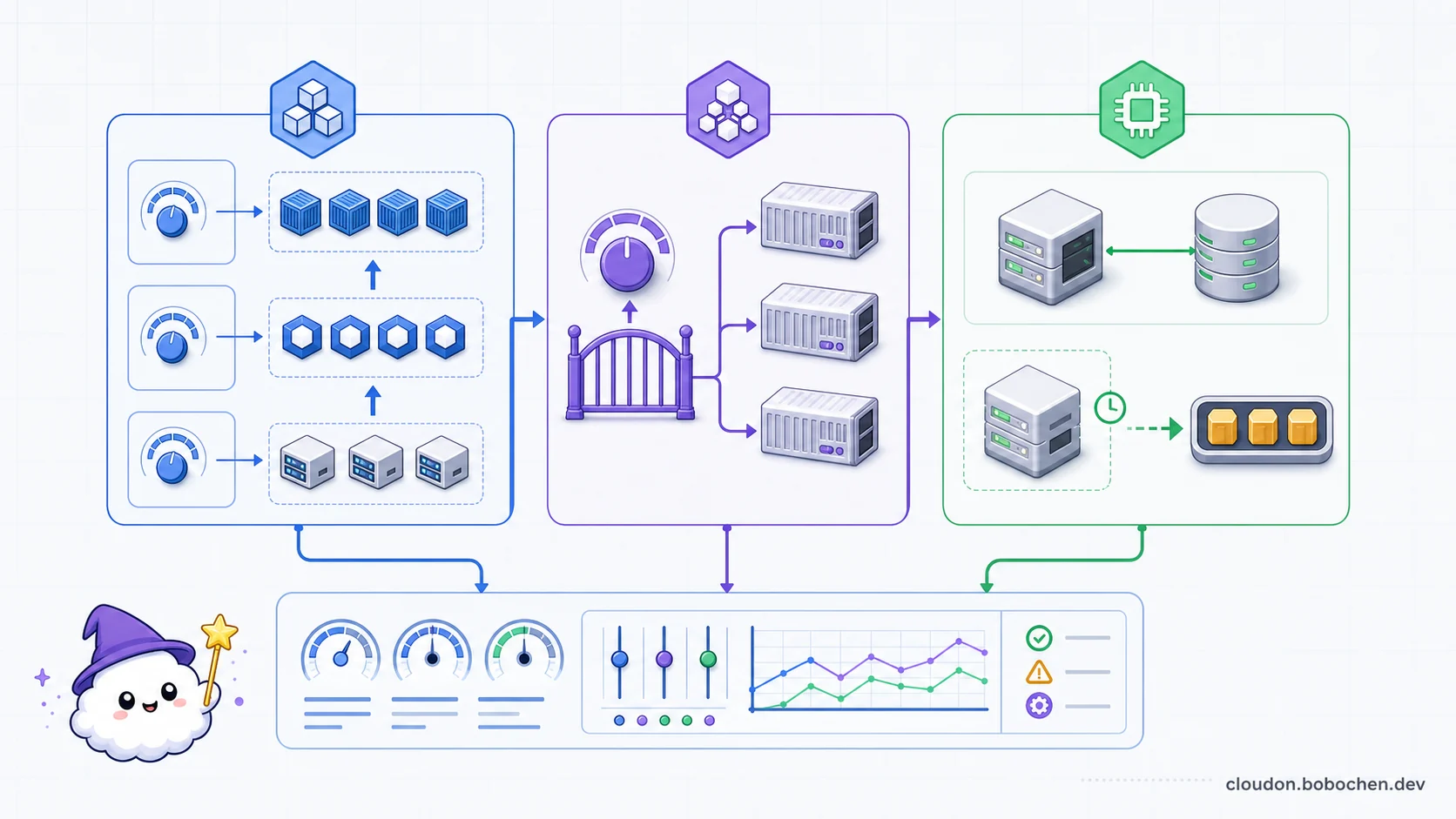
圖解:GKE 要同時處理 workload、Pod 與 node 擴縮;代管容器要用壓測決定並行數;可中斷工作則必須能把任務安全放回佇列。選到產品後,這些設定才決定實際行為。
GKE:先決定誰負責節點
Autopilot 與 Standard
兩種模式都能跑正式工作負載,差別在責任邊界:
- Autopilot:Google 管理節點、擴縮和多數基礎設定,團隊把重心放在 Pod 規格、政策和應用。Google 建議多數工作負載先從 Autopilot 評估。
- Standard:團隊直接管理 node pools、機器類型、節點映像和更多底層設定,適合需要特殊節點配置、細緻拓撲或特定營運控制的情境。
Standard 現在也能透過 ComputeClasses 使用部分 Autopilot 管理能力,所以選擇不必被簡化成「全代管或全自管」。先列出必須掌控的節點能力,再檢查哪種模式支援。
擴縮其實有三層
GKE 常見的擴縮器處理不同問題:
- Horizontal Pod Autoscaler(HPA):依 CPU、記憶體或自訂/外部指標調整 Pod 數量。
- Vertical Pod Autoscaler(VPA):根據歷史和目前用量建議或調整 Pod 的 CPU/memory requests。
- Cluster Autoscaler:當 Pod 因節點資源不足而無法排程時增減節點;在 Standard 也可搭配 node auto-provisioning 建立合適的 node pool。
這三層不能各自設定完就算了。HPA 若以 CPU utilization 為訊號,VPA 同時改 CPU request 會改變利用率分母,兩者可能互相影響。可以先讓 VPA 使用 recommendation mode,或讓 HPA 改用不受 request 變動影響的業務指標,再用壓測觀察。
一個健康的擴縮設計至少要驗證:
- Pod request 是否接近實際需求,而不是全部填很大以求安心。
- HPA 指標是否早於使用者延遲惡化。
- 新 node 從建立到 Pod ready 需要多久。
- scale down 是否會中斷長工作、違反 PodDisruptionBudget 或耗盡連線。
- 下游資料庫和 API 是否承受得住上游擴張。
Release channel 是更新節奏,不是品質排名
GKE 目前提供四個 release channels:
- Rapid:較早取得新版 Kubernetes 和 GKE 功能,適合相容性驗證與能快速應變的環境。
- Regular:預設 channel,在新功能與成熟度間取平衡,適合多數工作負載。
- Stable:版本進入較晚,適合希望多留驗證時間的環境。
- Extended:提供更長的 minor version 支援期,適合升級窗口很少,但仍願意承擔延長支援條件與費用的系統。
所有 channel 都會更新。Stable 不是永遠不升級,Extended 也不是可以不處理 deprecated API。正式做法是先掃描 API 相容性、設定 maintenance window/exclusion、在非生產叢集驗證,再觀察升級後的 SLO。未加入 release channel 的選項已被標示為 deprecated,現有設計也應規劃遷移。詳情可看 GKE release channels。
Node image 與 node pool
Container-Optimized OS 是常見預設;Ubuntu node image 則適合確實需要其套件或作業系統行為的情境。不要只因為「可能要裝東西」就換映像。先確認 daemon、kernel module、GPU driver、security baseline 與支援限制。
使用 Standard 時,可以按工作負載拆 node pools,例如一般服務、記憶體密集、GPU 和 Spot。拆分的代價是更多容量碎片、升級與配額管理,因此每一個 pool 都應有明確理由。
Cloud Run:並行數要用壓測決定
Cloud Run 一個 instance 可以同時處理多個 request。把 maximum concurrency 調高,可能提高資源利用率;也可能讓單一 instance 的 CPU、memory、connection pool 或 event loop 過載。調低則能隔離請求,但可能增加 instance 數、冷啟動和成本。
設定流程可以這樣做:
- 先確認應用本身的 worker/thread/async 模型能處理多少並行工作。
- 設定 CPU、memory 和應用層 concurrency 上限。
- 用接近真實 request size 與下游延遲的流量壓測。
- 觀察 p95/p99 latency、error rate、CPU、memory、instance count 和資料庫連線。
- 再調整 Cloud Run maximum concurrency,而且不要超過應用本身能穩定處理的範圍。
Cloud Run 的預設與上限可能隨平台演進;架構設計應記錄測得的安全值,而不是把預設值當成效能承諾。最新範圍請查 Cloud Run concurrency。
Request-based 與 instance-based billing
目前 Cloud Run services 有兩種 billing settings:
- Request-based billing:預設模式,主要在處理 request、啟動與關閉時配置 CPU 並計費。
- Instance-based billing:instance 整個生命週期都有 CPU,也按整段生命週期計費,適合需要短時間背景處理或穩定高流量的服務。
這是 billing 和 CPU allocation 的選擇,不是「WebSocket 一律用 instance-based」的規則。WebSocket request 存續期間本來就在處理 request;真正要釐清的是回應結束後是否還要可靠地做背景工作。需要重試、排程或長時間非同步處理時,通常應把工作交給 Cloud Tasks、Pub/Sub、Cloud Run jobs 或其他適合的服務,不要依賴某個 service instance 一直活著。
此外還要一起設定:
- Minimum instances:降低冷啟動,但會增加待命成本。
- Maximum instances:保護預算和下游系統,但設太低會讓請求排隊或失敗。
- Timeout:應和用戶端、load balancer、工作重試策略一致。
- CPU/memory:用 profile 與壓測決定,不用 request 數猜。
Cloud Run jobs 執行有限工作並使用 instance-based billing;有 HTTP request lifecycle 的服務才用 Cloud Run service。先選執行模型,再談參數。
VM 儲存:先問耐久性和存取模式
不要從 IOPS 表格開始選磁碟。先回答四題:
- 資料必須在 VM 或 host 消失後保留嗎?
- 一個 VM 用,還是多個 VM/Pod 要同時掛載?
- 應用需要 block、shared file,還是 object semantics?
- 需要多少 IOPS、throughput、latency,以及哪一項最先成為瓶頸?
Hyperdisk 與 Persistent Disk
兩者都是 durable network block storage。若 machine series 支援,而且工作負載需要把容量和效能分開調整,可優先評估 Hyperdisk。Persistent Disk 的相容範圍廣,也常用於 boot disk 和一般資料磁碟,但效能通常會和容量、machine limits 一起受限。
不要用一個固定 IOPS 數字選型。實際上限會受 disk type、provisioned performance、容量、machine type、vCPU 和掛載方式影響。先從 Choose a disk type 找候選,再以實際 block size、read/write ratio 和 queue depth 做 benchmark。
Local SSD
Local SSD 直接連到 host,適合需要低 latency、高 IOPS,而且資料可重建的暫存空間,例如 shuffle、cache 或 scratch data。它不是 durable storage,也不能像 network disk 一樣依賴 snapshot 保護資料。應用必須能在 VM 或 disk 不可用時重建內容。
Filestore 與 Cloud Storage
- Filestore 提供受管理的 NFS file service,適合多個 client 共用檔案與既有 NFS 應用。
- Cloud Storage 是 object storage。Cloud Storage FUSE 可以把 bucket 掛成檔案介面,但它不會因此變成完整 POSIX file system;rename、metadata、locking、latency 和 consistency assumptions 都要依文件和應用測試。
如果應用真正需要的是 object API,就直接使用 Cloud Storage client library,通常比假裝成傳統磁碟更清楚。
Spot VM:把中斷當成正常事件
Spot VM 成本較低,但可能隨時被回收、也不保證一定有容量,並且不在 Compute Engine SLA 內。適合的工作通常有這些特徵:
- 可以切成小份、重試或從 checkpoint 恢復。
- 中斷一台不會破壞整批資料的一致性。
- Queue 或 scheduler 能把未完成工作重新分派。
- 容量不足時可以等待,或退回 standard VM。
不要把 shutdown notice 當成一定足夠的存檔時間。notice 行為和可設定時間會演進,應用仍要定期 checkpoint。對線上服務,可在不同 node pools 或 MIG 中混用 standard 與 Spot capacity,讓最低服務容量不依賴 Spot。
Sole-tenant nodes 則是隔離 host 的另一種需求,常見於特定授權、法規或硬體隔離條件。是否必須使用 sole-tenant,要看軟體授權條款和控制要求,不是所有 BYOL 都自動成立。
實作練習:替圖片處理平台做配置
假設 API 跑在 Cloud Run,背景轉檔跑 GKE,原始檔放 Cloud Storage,暫存資料需要高 I/O。可以這樣驗證:
- Cloud Run API 用壓測找出穩定 concurrency,並設 maximum instances 保護資料庫。
- 把轉檔工作寫入 queue,不在 API response 後偷偷繼續跑。
- GKE HPA 依 queue depth 擴 Pod;Cluster Autoscaler 再依 pending Pod 增節點。
- 可重試 worker 使用 Spot node pool,並保留一小部分 standard capacity。
- 原始檔和輸出留在 Cloud Storage;Local SSD 只存可重建的轉檔暫存。
- 模擬 Spot 中斷、node upgrade、queue 暴增和資料庫降速,觀察是否仍符合 SLO。
這比「哪種磁碟最快、哪種並行數最省」更接近真實架構工作。
本課檢查清單
- GKE 模式的差別是責任與控制範圍,不是簡單的入門版/專業版。
- HPA、VPA 和 Cluster Autoscaler 要一起設計訊號、時間尺度與下游容量。
- Rapid、Regular、Stable、Extended 都會更新,release channel 不能取代相容性測試。
- Cloud Run concurrency、minimum/maximum instances 和 billing setting 應用壓測選擇。
- Hyperdisk、Persistent Disk、Local SSD、Filestore 和 Cloud Storage 的資料語意不同。
- Spot VM 必須可中斷、可重試、可補容量;低價不是採用的唯一理由。
延伸閱讀
下一步
下一課會把同一套「需求、選擇、驗證」方法帶到 AI/ML,分清楚預測模型、生成式 AI、RAG、agent 與訓練基礎設施各自在解什麼問題。
