工作坊要交付的不是一張漂亮架構圖
這次練習要產出四樣東西:
- 可驗證的 requirement/constraint matrix。
- 至少兩個候選方案與 trade-off。
- 一份寫清楚理由、假設和後果的 ADR。
- Migration 與 production validation plan。
考試不會要求你真的提交這些文件,但這套思路能幫你看出選項少說了什麼。Architecture diagram 只能顯示元件,無法代替一致性、failure、security 和 operation semantics。
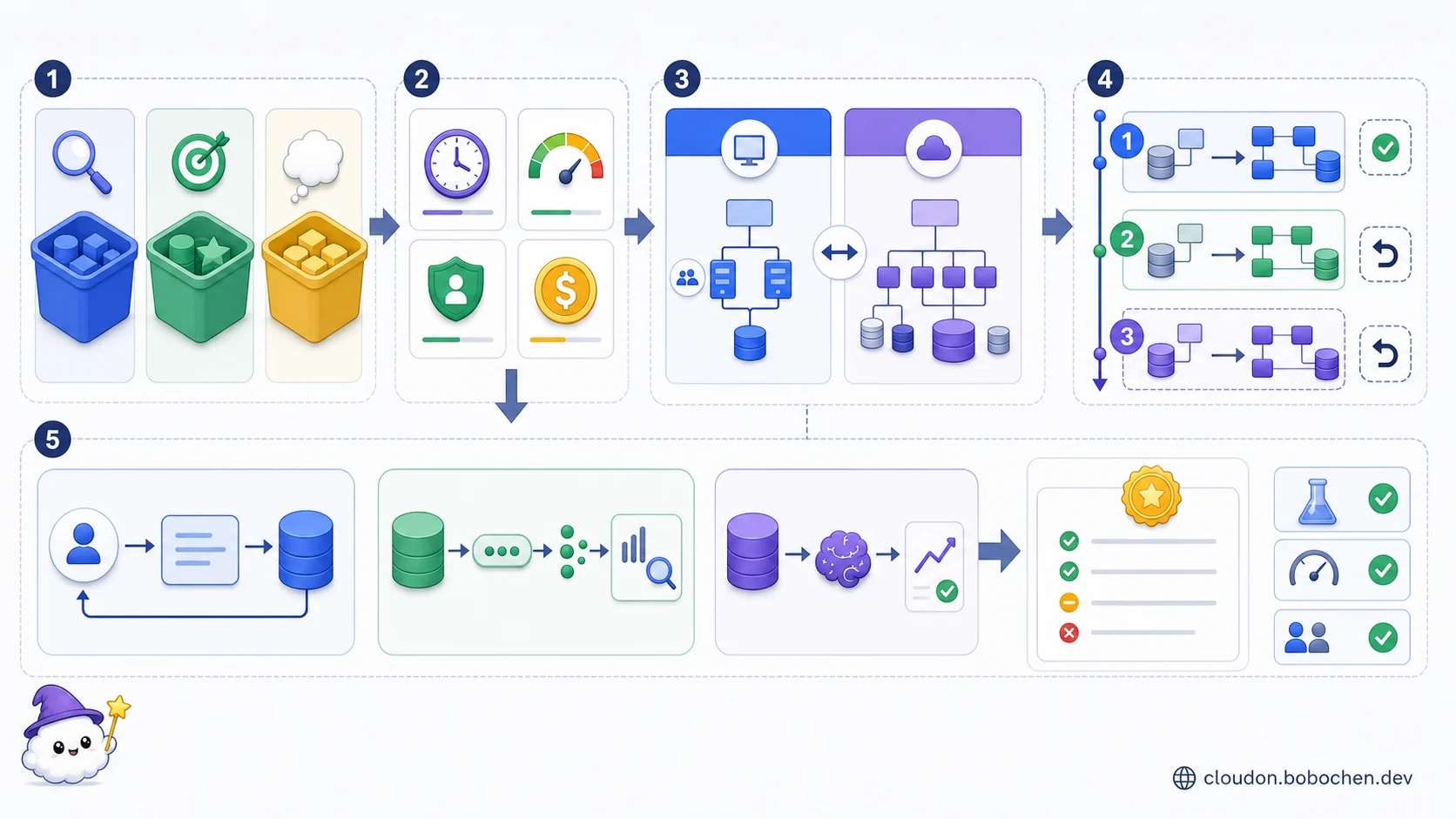
圖解:先分開事實、目標與假設,建立可測試條件,再比較現在能落地與未來可擴展的方案;遷移分階段且可回退,資料與 AI 路徑則各自用驗證結果支撐 ADR。
模擬案例:CloudMart
CloudMart 是總部位於台灣的 online retailer,目前服務台灣與部分東南亞客戶,計畫在 18 個月內進入更多亞太市場,之後評估歐洲。
現況
- Java monolith 跑在地端 VMware,部分 HTTP service 已能 containerize。
- 單一 MySQL 8.0,約 2 TB,order、inventory 和 catalog 共用 schema。
- Product image 放在 NAS,分析資料每天夜間 ETL。
- 每月人工發布一次,回滾需由 DBA 與 application team 協調。
- 團隊熟悉 Java、SQL 和 Docker,只有少數人維護過 Kubernetes。
- 促銷尖峰約為平日 10 倍,最近一次因 database connection 耗盡而停止結帳。
管理層提出的目標
- 台灣與東南亞使用者「都要很快」。
- 促銷期間不能再停止結帳。
- Inventory 不可超賣。
- 半年後開始提供個人化推薦。
- 未來進入歐洲時要符合 privacy 與 data-residency 要求。
- 不希望一次重寫整套系統,也不能中斷現有營運。
注意,這些句子還不能直接選服務。「很快」沒有 percentile;「不可超賣」沒說 reservation workflow;歐洲的實際資料落地義務也尚未由 legal 確認。
第一步:把事實、目標、假設分開
| 類型 | 本案例內容 | 下一個動作 |
|---|---|---|
| Fact | MySQL 2 TB、monolith、10 倍尖峰、團隊 K8s 經驗少 | 可量測與盤點 |
| Outcome | 不停止結帳、不超賣、改善 recommendation | 定義 KPI/SLI |
| Constraint | 不能一次重寫、不能中斷營運 | 規劃 migration wave |
| Unknown | 「很快」、歐洲 residency、可接受 RPO/RTO | 找 owner 確認 |
| Assumption | 新 service 可先以 API 包住 monolith | 用 spike/PoC 驗證 |
考試題通常會把 unknown 補成明確條件。在真實工作中,架構師不能擅自把它們變成需求。
先問這些問題
- 哪個 user journey 最重要:browse、add to cart、checkout 還是 order tracking?
- Latency 是 client-observed 還是 server-side,在哪個 region、哪個 percentile?
- Inventory 是看到的數量不能過時,還是確認訂單時不能超賣?Reservation 可保留多久?
- Payment 已成功但 order commit timeout 時,如何 reconciliation?
- 可接受多少 downtime 和 data loss?各流程是否不同?
- 哪些資料屬於個資?Legal 要求是儲存地、處理地,還是跨境 transfer control?
- Peak traffic 的 request mix、duration、payload 與 database write ratio 是多少?
- VMware lease、license、network bandwidth 和 migration deadline 有沒有硬限制?
第二步:把需求寫成可測試條件
假設 stakeholder 確認後,得到以下 initial target:
| Journey/能力 | Initial target | 驗證方式 |
|---|---|---|
| Checkout availability | 30 天成功率 SLO 99.95%,排除明確 user input error | Synthetic checkout + production SLI |
| Checkout latency | 台灣/新加坡使用者在 peak load 下 p95 < 800 ms | Region-based load test + RUM |
| Inventory integrity | Confirmed order 不得讓 on-hand quantity 低於 0 | Concurrent reservation test + invariant query |
| Region outage | Checkout 60 分鐘內恢復,observed data loss 不超過已核准範圍 | DR game day |
| Release | Canary 失敗不影響超過 5% production traffic | Progressive delivery test |
| Recommendation | 比現行熱門商品 baseline 提升指定 offline/online KPI | Holdout experiment |
這些數字只是本工作坊假設,不是通用建議。真正價值是每個目標都有 measurement。
第三步:不要把 target architecture 當第一個 migration step
CloudMart 需要兩條時間線:先移除 data-center/capacity risk,再逐步調整 application boundary。
Phase 0:盤點與建立 baseline
- 用 dependency discovery、traffic capture、query analysis 和 cost model 了解現況。
- 先補 application/database telemetry,量 peak、connection、slow query、failure 和 batch window。
- 建立 landing zone、identity、network、logging、budget 和 policy guardrail。
- 驗證 migration throughput、database compatibility、rollback 與 cutover window。
Phase 1:先搬可搬的,不承諾全面微服務化
若 monolith 能以 container 執行,候選 compute 包括:
- Cloud Run:適合 HTTP-driven、stateless、能配合 request/instance lifecycle 的 workload,團隊 operation 負擔較低。
- GKE Autopilot/Standard:適合明確需要 Kubernetes API、sidecar、daemon、特殊 networking、長時間 worker 或較多 workload control 的情況。
- Compute Engine MIG:若 application 對 VM、OS、filesystem 或 legacy agent 有相依,可能是期限內風險較低的 rehost step。
不能只因「核心交易很重要」就選 GKE,也不能只因「Cloud Run 是 serverless」就忽略 long-running process、local state、connection 和 scaling behavior。先用 application assessment 排除不相容項。
Phase 2:逐步建立 service boundary
從變更頻率高、domain boundary 清楚且能獨立驗證的能力開始,例如 product catalog read 或 notification。用 facade/routing 將新 request 導向新 service,其餘仍回 monolith。
Order 與 inventory 共用 transaction,通常不是第一個隨意拆開的地方。拆分前要先定義 reservation、idempotency、event ordering、outbox 和 reconciliation,否則只是把 database transaction 變成 distributed inconsistency。
第四步:資料庫要比較「現在能搬」與「未來要擴」
候選 A:Cloud SQL for MySQL
優點是 engine compatibility 較高,能縮短 migration;可先建立 regional HA、PITR/backup、connection management 和 cross-region DR plan。限制是單一 primary 的 write scale 與 cross-region asynchronous replication,無法直接滿足任何想像中的全球 multi-writer requirement。
候選 B:Spanner
Spanner 適合需要水平擴展 relational transaction、strong consistency 與符合其 configuration 的跨區可用需求。不過它不是 MySQL 的 drop-in replacement:schema、key、query、transaction 和 application access pattern 都需要評估,migration 成本可能高。
本階段的決策
根據「不能一次重寫」與 2 TB MySQL 現況,Phase 1 先以 Cloud SQL 作為低變更 migration candidate,完成 compatibility/performance/cutover PoC。這不是宣告永遠使用 Cloud SQL。
同時把 order/inventory access pattern 收集起來。若未來確認多區 write、scale 與 consistency 真的超出 Cloud SQL 能力,再為該 bounded context 評估 Spanner,並把 application rewrite、dual-run validation 和 data reconciliation 列入成本。
Inventory 不超賣可以先靠單一 authoritative transaction、reservation table、idempotency key 和正確 locking/optimistic concurrency 解決,不需要因一句「全球庫存」立即更換所有 database。
第五步:讀取路徑與寫入路徑分開設計
- Product image 遷到 Cloud Storage,依 cacheability 搭配 external Application Load Balancer/Cloud CDN;personalized response 不進 shared cache。
- Catalog read 可用 cache 降低 database load,但 inventory confirmation 仍回 authoritative service。
- Public API 經 load balancer、Cloud Armor 與適合的 identity control;backend 不開 bypass path。
- Cloud Interconnect 或 HA VPN 的選擇以 migration traffic、availability、lead time 和 cost 為依據,並建立 redundant path/route test。
- Global frontend 能降低 edge latency,不代表 regional database write 也會變成 local latency;用 latency budget 找真正 critical path。
第六步:分析管線不能靠 application dual write
Order transaction 同時寫 operational database 和 BigQuery,任一步失敗就會不一致。較安全的方向是:
- Order 先在 authoritative transaction commit。
- 以 outbox、CDC 或支援的 integration 產生可重放 event。
- Pub/Sub 解耦 consumers,consumer 做 idempotency/deduplication。
- Dataflow 或其他 processing 將資料整理後寫入 BigQuery。
- 設 data quality、late event、schema evolution 和 reconciliation 指標。
BigQuery 是 analytics system,不拿來做即時扣庫存。Recommendation feature 也不直接讀 raw production tables,先建立有 consent、lineage、feature freshness 和 access control 的 training/serving data flow。
第七步:AI 專案先做 baseline 與 evaluation
「個人化推薦」可以是 rule-based、prebuilt search/recommendation capability、BigQuery ML,或 Vertex AI 上的 custom model。選擇前確認:
- 目前有沒有足夠的 view、click、cart、purchase 和 product metadata?
- 要最佳化 click-through、conversion、revenue,還是 customer satisfaction?
- Cold-start、新商品、季節性和 bias 怎麼處理?
- Online inference latency/availability 是否在 checkout critical path?
- Personalization 是否取得適當 consent,使用者能否 opt out?
先以熱門商品或簡單 ranking 做 baseline,再進 offline evaluation、shadow/A/B test。Vertex AI Pipelines 可編排 training workflow,Model Registry 管理 model version,endpoint/batch prediction 則依 serving need 選擇。Model Garden 是尋找 model 的入口,不是所有 custom TensorFlow workflow 的 version registry。
第八步:可靠性、安全與成本放進同一份決策
Reliability
- Checkout、database、payment 與 queue 分別定義 SLO/failure behavior。
- Autoscaling 設 maximum 與 downstream connection budget,促銷前跑 peak/soak test。
- Cloud SQL HA 處理 zone failure;region DR 用 replica/backup、runbook 和 game day 驗證 observed RTO/RPO。
- Release 用 immutable artifact、canary、synthetic checkout 和 database-compatible rollback。
Security/privacy
- Human 與 workload identity 分開,使用 least privilege 和短效 credential。
- 個資先分類;log、analytics 和 AI dataset 各有 purpose、retention 與 access policy。
- CMEK 只有在 control/regulation 需要時使用,並設 key availability、rotation 和 recovery。
- VPC Service Controls 適用於支援服務的 data exfiltration defense,不會取代 IAM、application authorization 或 internet egress control。
- 歐洲資料設計等 legal 釐清後再定案,不自行把 GDPR 解讀為所有資料必須留在歐洲。
Cost
- 用 billing export 把成本分到 environment/service/journey,並計算每筆成功訂單成本。
- 比較 migration、parallel run、egress、support、license 和 training,不只看 compute list price。
- CUD 只套在已觀察到的穩定 baseline;promo burst 保留彈性 capacity。
範例 ADR:Phase 1 database
Decision: Phase 1 將 MySQL workload 遷到 Cloud SQL for MySQL,暫不直接改為 Spanner。
Context:
- 2 TB MySQL 與 monolith 共用 schema。
- 18 個月內要擴張,但目前沒有已核准的全球 multi-writer requirement。
- 團隊不能承擔一次 application/database rewrite。
Alternatives:
- Cloud SQL: compatibility 較高,write-scale 與跨區 DR 有限制。
- Spanner: 長期 scale/consistency 能力較強,需 schema 與 application 改造。
- Self-managed MySQL on Compute Engine: control 高,operation burden 也高。
Consequences:
- 先完成 compatibility、load、DMS/cutover 和 rollback PoC。
- 設 regional HA、backup/PITR、cross-region DR 與 restore test。
- 收集 order/inventory access pattern,於 expansion gate 重新評估 Spanner。
Review trigger:
- Sustained write/storage growth超過已驗證容量。
- 核准跨區 write 與 consistency requirement。
- Observed RTO/RPO 無法滿足業務目標。好的 ADR 不假裝選擇沒有缺點,也會寫明何時重新評估。
考試中怎麼縮短這套流程
不必在腦中畫完整 CloudMart。只做四件事:
- 找動詞:題目要你 assess、migrate、design、secure 還是 troubleshoot?
- 找硬約束:existing skill、deadline、protocol、RTO/RPO、consistency、compliance。
- 每個選項問一句:它滿足哪個約束,又新增什麼沒有被要求的負擔?
- 最後檢查:是否把未提供的假設當成事實?
若題目要求「先做什麼」,正確答案可能是 assessment,也可能是立即隔離 compromised credential。順序取決於風險與題目狀態,沒有「FIRST 永遠先規劃」這種規則。
本課檢查清單
- Fact、outcome、constraint、unknown 和 assumption 要分開。
- Requirement 要有 owner、範圍、數值與驗證方法。
- Migration landing architecture 與長期 target architecture 可以不同。
- GKE、Cloud Run 和 Compute Engine 按 workload/team/control 選,不按重要性排序。
- Cloud SQL compatibility 較高;Spanner 能力不同但需要 migration/application 成本。
- Inventory integrity 先定義 transaction、reservation、idempotency 和 reconciliation。
- Analytics 用可重放 pipeline,不讓 application 對 operational/warehouse 雙寫。
- AI 先做 baseline、evaluation、privacy 和 fallback,再談 model platform。
- ADR 要記 alternative、consequence、validation 和 review trigger。
下一步
下一課會把這套決策方法帶進考場:先核對官方考試規格,再用原創題練習如何排除「技術上能做、但不符合題目」的選項。
