基礎 Data、ML 與 AI 任務
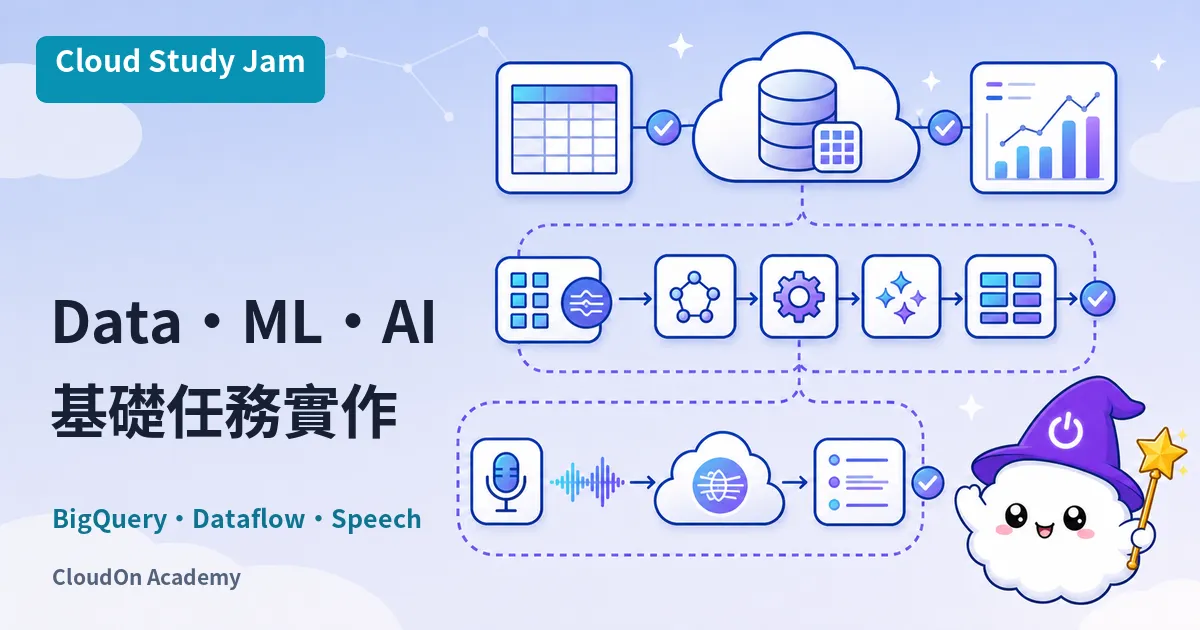
課程概述
這門課是 Google Cloud 資料與 AI 的綜合入門,一次帶你碰三個核心服務:用 BigQuery 做大規模資料分析、用 Dataflow 做資料處理管線、用 Speech-to-Text API 把語音轉成文字。跑完這門課,你對 Google Cloud 整套資料與 AI 生態系會有個全面的概念,後面要接進階課程也比較不會卡。
你將學到
- 在 BigQuery 中執行 SQL 查詢並分析公開資料集
- 使用 Dataflow 建立批次與串流資料處理管線
- 呼叫 Cloud Speech-to-Text API 進行語音辨識
- 理解 Google Cloud 資料生命週期的各階段
- 選擇正確的服務來匹配不同的資料處理需求
核心概念
Google Cloud 資料生命週期
Google Cloud 的資料處理,走的是一條很清楚的生命週期:
- 擷取(Ingest) — Pub/Sub、Cloud Storage、Transfer Service
- 儲存(Store) — Cloud Storage、BigQuery、Cloud SQL、Bigtable
- 處理(Process) — Dataflow、Dataproc、Cloud Functions
- 分析(Analyze) — BigQuery、Looker、Connected Sheets
- ML/AI — Vertex AI、AutoML、預訓練 API
BigQuery 基礎
BigQuery 是無伺服器架構,你不用管叢集、也不用自己調容量。它用的是列式儲存(Columnar Storage)格式,跑分析型查詢特別快:
- 公開資料集 — BigQuery 提供數百個免費公開資料集,包含氣象、GitHub 活動、維基百科等
- Standard SQL — BigQuery 支援 ANSI SQL:2011 標準,熟悉 SQL 的人可以直接上手
- 巢狀與重複欄位 — BigQuery 支援 STRUCT 和 ARRAY 類型,適合半結構化資料
Dataflow 與 Apache Beam
Dataflow 是 Google Cloud 的全代管資料處理服務,基於 Apache Beam SDK:
- 批次模式 — 處理有界(Bounded)資料集,例如每日 ETL
- 串流模式 — 處理無界(Unbounded)資料流,例如即時事件處理
- 自動擴縮 — Dataflow 會根據資料量自動調整 worker 數量
Cloud Speech-to-Text API
Speech-to-Text API 將語音轉換為文字,支援超過 125 種語言:
- 同步辨識 — 短音訊(< 1 分鐘)即時回傳結果
- 非同步辨識 — 長音訊(最長 480 分鐘)背景處理
- 串流辨識 — 即時語音辨識,適合即時字幕場景
實作重點
- BigQuery 查詢前先用
SELECT * FROM dataset.table LIMIT 10預覽資料結構 - Dataflow 的 Job 需要指定暫存位置(
--temp_location gs://bucket/temp) - Speech-to-Text 支援多種音訊格式:FLAC、WAV、MP3、OGG
- 常見錯誤:Dataflow Job 因 IAM 權限不足而失敗,需確認服務帳戶有
dataflow.worker角色 - 成本控制技巧:BigQuery 查詢前先使用 dry run 估算掃描量(
--dry_runflag)
Skill Badge 指引
Lab 連結:Perform Foundational Data, ML, and AI Tasks in Google Cloud — 完成此 lab 可獲得 Skill Badge
延伸學習
- BigQuery 搭配 Connected Sheets 分析 — 用 Sheets 探索 BigQuery 資料
- BigQuery ML 建模實戰 — 直接在 BigQuery 中建立 ML 模型
- 使用 Google Cloud ML API — 再多認識幾個預訓練 ML API
Study Jam:數據與 AI 基礎 — 4/12 完成
查看系列全覽 →
相關文章
您可能也會對這些文章感興趣
Study JamGCPBigQuery
基礎 Data、ML 與 AI 任務
綜合實作 BigQuery 資料分析、Dataflow 資料處理與 Cloud Speech-to-Text API,建立完整的資料與 AI 基礎能力
時事
1min

Study JamGCPBigQuery
Gemini 提升 BigQuery 生產力
掌握 Gemini 在 BigQuery 中的全方位生產力技巧,包含 SQL 自動生成、查詢優化建議、資料治理輔助與協作功能
時事
2min
Study JamGCPBigQuery ML
BigQuery ML 推論實戰
深入學習 BigQuery ML 的進階推論技巧,包含遠端模型呼叫、模型匯入、批次預測與特徵工程的最佳實踐
時事
2min
