企業資料庫 AI Agent

課程概述
企業裡最值錢的資料,通常都躺在關聯式資料庫裡:銷售數據、客戶資訊、庫存記錄、營運指標。但想從這些資料挖出洞察,過去得靠會寫 SQL 的資料分析師才行。AI Agent 搭配 NL2SQL(自然語言轉 SQL)技術之後,非技術人員也能用日常講話的方式直接查資料庫,存取資料的門檻一下子低了很多。
你將學到
- 理解 NL2SQL 的運作原理與技術限制
- 使用 Vertex AI 建構能查詢 Cloud SQL 與 AlloyDB 的 Agent
- 設計安全的資料庫存取架構,防止 SQL 注入與越權查詢
- 掌握 Schema 描述最佳實踐,提升查詢準確率
- 學習 AlloyDB AI 的向量搜尋整合方式
核心概念
NL2SQL 的運作流程
NL2SQL 的核心流程分為四個階段:
- Schema 理解 — LLM 讀取資料庫的表結構、欄位名稱與關聯
- 意圖解析 — 分析使用者的自然語言問題,辨識查詢目標
- SQL 生成 — 根據 Schema 與意圖,生成合適的 SQL 語句
- 結果詮釋 — 將查詢結果轉化為使用者易懂的自然語言回答
為什麼 Schema 描述很關鍵?
LLM 生成 SQL 的品質,直接看它對資料庫結構懂多少。光靠欄位名稱不夠,像 cust_id 可能是「客戶編號」,也可能是「客製化 ID」,根本分不出來。一份好的 Schema 描述應該包含:
- 每張表的業務用途說明
- 每個欄位的中文意義與取值範圍
- 表與表之間的關聯關係(外鍵)
- 常用查詢的範例(few-shot)
Cloud SQL vs AlloyDB 的選擇
| 面向 | Cloud SQL | AlloyDB |
|---|---|---|
| 定位 | 通用型關聯式資料庫 | 高效能 PostgreSQL 相容資料庫 |
| AI 整合 | 透過外部呼叫 Vertex AI API | 內建 AI 函式,支援向量搜尋 |
| 向量搜尋 | 需搭配 pgvector 擴充 | 原生支援,效能最佳化 |
| 適用場景 | 一般 OLTP + NL2SQL | 高效能 OLTP + 語意搜尋 + AI 工作流 |
AlloyDB AI 的向量能力
AlloyDB 內建的 AI 功能,讓你直接在資料庫裡跑 embedding 和向量搜尋。也就是說,Agent 不只能做精確的 SQL 查詢,還能做語意相似度搜尋,例如「找出跟這筆客訴類似的歷史案例」。
安全架構設計
讓 AI Agent 碰資料庫,安全控制一定要做足:
- 唯讀帳號 — Agent 使用的資料庫帳號只授予 SELECT 權限
- 查詢白名單 — 限制 Agent 只能存取特定的表和視圖
- SQL 驗證層 — 在執行前檢查生成的 SQL 是否包含危險語法(DROP、DELETE、UPDATE)
- 結果限制 — 設定 LIMIT 上限,防止全表掃描拖垮效能
實作重點
- 建立 Agent 的 Tool 時,將 Schema 描述作為 Tool 的 context 傳入
- 使用 Cloud SQL Auth Proxy 連線,避免在程式碼中硬寫資料庫密碼
- AlloyDB 的
google_ml.embedding()函式可直接在 SQL 中產生 embedding 向量 - 測試 NL2SQL 時,從簡單的單表查詢開始,逐步增加到多表 JOIN
- 常見問題:LLM 對 DATE 函式的方言差異掌握不佳(MySQL vs PostgreSQL),需在 Schema 描述中提示
Lab 導讀
Lab 連結:Build AI Agents with Enterprise Databases — Google Cloud Skills Boost
這個 Lab 會帶你做出一個能查企業銷售資料庫的 AI Agent。過程中你會設定 Cloud SQL 實例、載入範例資料、寫 Schema 描述、定義資料庫查詢 Tool,最後讓使用者能直接用「上個月哪個產品銷售額最高?」這種自然語言問句,問出資料洞察。
延伸學習
- Cloud SQL for PostgreSQL 管理實作 — Cloud SQL 的基礎管理操作
- Agent Development Kit 智能代理開發 — ADK 基礎,建構 Tool 的核心知識
- Vertex AI MLOps 模型評估 — 評估 NL2SQL 的準確率與品質
相關文章
您可能也會對這些文章感興趣

企業資料庫 AI Agent
學習建構能直接與企業資料庫互動的 AI Agent,掌握 NL2SQL 技術與 Cloud SQL、AlloyDB 的整合實作
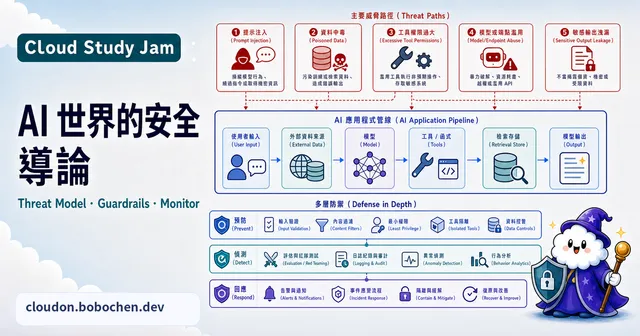
AI 世界的安全導論
全面認識 AI 系統面臨的安全威脅與防禦策略,涵蓋模型安全、資料保護、對抗性攻擊與 GCP 安全工具的實作整合
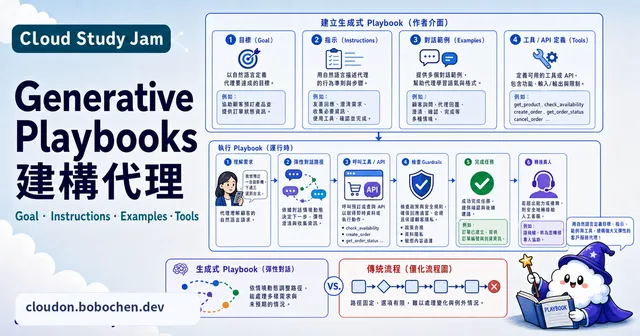
Generative Playbooks 建構代理
學習使用 Dialogflow CX 的 Generative Playbooks 功能,以自然語言定義對話流程與工具整合,快速建構智能客服代理
