Data Store Agent 虛擬 FAQ
課程概述
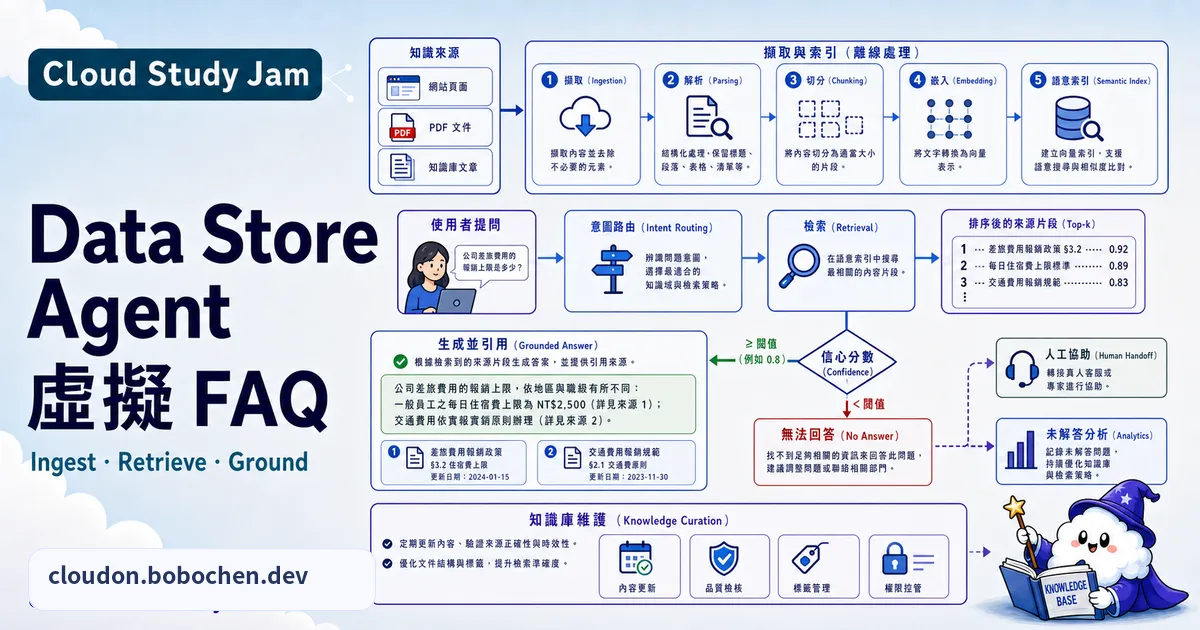
企業每天都會收到一堆重複的問題,像是退貨政策、產品規格、帳號管理、操作流程。Data Store Agent 可以把你現有的文件、FAQ、網站內容,直接變成一套 AI 知識問答系統。你不用手動標註 Intent,也不用自己寫對話流程,只要把文件上傳上去,Agent Search(前身為 Vertex AI Search)會自動建好索引,剩下理解問題、生成回答的部分就交給 Dialogflow CX(現稱 Conversational Agents)的 Data Store Agent。
你將學到
- 理解 Data Store Agent 的架構與資料流
- 在 Agent Search 中建立不同類型的資料存儲區
- 設定 Dialogflow CX 的 Data Store Handler
- 掌握文件前處理與結構化最佳實踐
- 調校搜尋品質與回答準確度
核心概念
什麼是 Data Store Agent?
Data Store Agent 是 Dialogflow CX 裡的一種 Agent 類型。它會把使用者的問題丟到 Agent Search 的 Data Store 去檢索,再用 LLM 把檢索結果整理成一段自然語言的回答。說穿了,它就是一套幫你預先搭好的 RAG(Retrieval-Augmented Generation)系統。
資料存儲區類型
Agent Search 支援三種資料來源:
| 類型 | 來源 | 適用場景 |
|---|---|---|
| 網站 | 指定 URL 清單或網域 | 將公司官網、Help Center 轉為問答系統 |
| 非結構化文件 | Cloud Storage 中的 PDF、HTML、DOCX 等 | 產品手冊、內部文件、政策文件 |
| 結構化資料 | BigQuery 表或 JSON/CSV 檔案 | 產品目錄、價格表、常見問題資料庫 |
Grounding 與引用
Data Store Agent 的回答不是憑空生出來的,每個回答都會附上引用來源(Citation)。使用者可以點引用連結去看原始文件,確認這個回答可不可信。這點對企業來說很重要:AI 講的話必須有據可查。
搜尋品質的三個槓桿
- 文件品質 — 輸入是什麼品質,輸出大概就是什麼品質。結構清楚、內容完整的文件,效果會比格式亂七八糟的掃描 PDF 好很多
- Chunk 策略 — Agent Search 會把文件切成一段一段的片段(chunk)來建索引,chunk 切多大會直接影響檢索的精準度
- Boost 控制 — 你可以調高特定文件或屬性的權重,例如讓最新版本的文件排在前面
FAQ 資料的特殊優勢
如果你手邊有整理好的 FAQ 資料(也就是問題配上答案),效果會比純文件好很多。原因是:
- 每筆 FAQ 本身就是一個完整的「問題→答案」單位
- 搜尋匹配更準,使用者怎麼問,會直接對到既有的問題
- 不用再讓 LLM 從一大篇長文件裡撈資料、拼湊答案
實作重點
- 建好 Data Store 之後要等索引跑完,通常 5-30 分鐘,看你資料量多大
- 在 Dialogflow CX 新增 Data Store Handler 時,回答預設就會用 LLM 合成,不用特別開模式;要調品質是去 Tool 設定動摘要(Summarization)、改寫(Rewriter)和 Grounding 信心門檻,預設值「Default」通常夠用,要細修再選「Customize」
- 上傳文件前先把格式整理一下,把頁首頁尾、頁碼、浮水印這些雜訊清掉
- 善用 metadata(像是文件類別、更新日期),搜尋時就能拿來過濾
- 一個常見的坑:PDF 裡的表格和圖片資訊可能會掉,建議把關鍵的表格改寫成文字說明
Lab 導讀
Lab 連結:Virtual FAQ with data store agents — Google Cloud Skills Boost
這個 Lab 會帶你從零做出一套企業 FAQ 系統。你會把文件上傳到 Cloud Storage、在 Agent Search 建立 Data Store、設定 Dialogflow CX 的 Data Store Agent,最後做出一個能回答公司政策和產品問題的虛擬助手。做的時候重點看一下:回答的品質,跟它引用的來源對不對得上。
延伸學習
- Gemini Enterprise 入門(前身 Agentspace) — 更大規模的企業知識搜尋平台
- Generative Playbooks 建構代理 — 結合 Data Store Tool 與 Playbook 建構更完整的 Agent
- Agent Assist 與 GenAI 功能 — 將知識問答能力應用到客服中心場景
相關文章
您可能也會對這些文章感興趣
Data Store Agent 虛擬 FAQ
學習使用 Vertex AI Search 與 Dialogflow CX 建構 Data Store Agent,打造自動化的企業知識問答系統
Generative Playbooks 建構代理
學習使用 Dialogflow CX 的 Generative Playbooks 功能,以自然語言定義對話流程與工具整合,快速建構智能客服代理
Vertex AI MLOps 模型評估
深入學習 Vertex AI 的 MLOps 工作流程,掌握模型評估指標、A/B 測試、CI/CD for ML 與模型註冊管理的完整實作
