Vertex AI MLOps 模型評估
課程概述
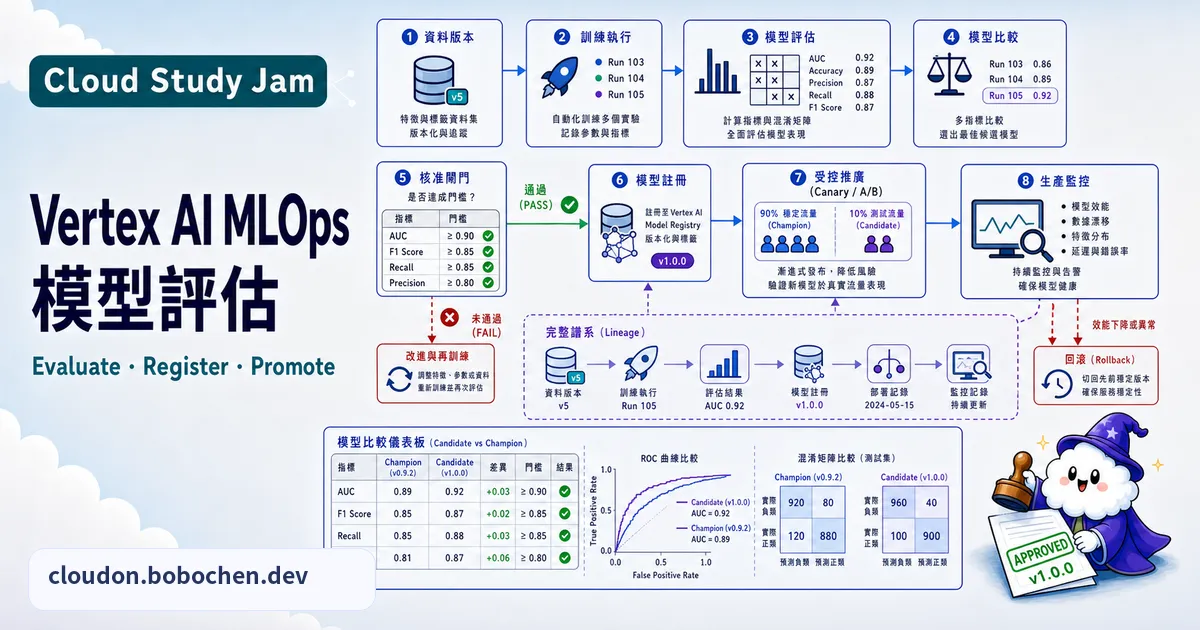
把 AI 模型做出來只是起點,真正麻煩的是後面:怎麼持續評估、改進,還要能穩穩地部署上線。MLOps(Machine Learning Operations)就是把軟體工程那套 DevOps 實踐搬進機器學習,讓模型不只在開發環境跑得漂亮,到了生產環境也能持續可靠地運作。這一整段流程,從模型評估到 Pipeline 自動化,Vertex AI 都有對應的工具可以接。
你將學到
- 理解 MLOps 的核心原則與成熟度模型
- 掌握 Vertex AI Model Evaluation 的關鍵指標
- 使用 Vertex AI Pipelines 建構自動化 ML 工作流
- 在 Model Registry 中管理模型版本與元數據
- 設計 A/B 測試實驗比較模型效能
核心概念
MLOps 成熟度等級
Google 定義了 MLOps 的三個成熟度等級:
| 等級 | 特徵 | 自動化程度 |
|---|---|---|
| Level 0 | 手動流程 | 手動訓練、手動部署、無監控 |
| Level 1 | ML Pipeline 自動化 | 自動訓練、自動驗證、持續訓練(CT) |
| Level 2 | CI/CD + CT | 程式碼變更自動觸發 Pipeline、模型自動部署 |
模型評估指標
不同類型的模型需要不同的評估指標:
分類模型:
- Precision(精確率) — 預測為正的案例中,真正為正的比例
- Recall(召回率) — 所有正案例中,被模型正確識別的比例
- F1 Score — Precision 和 Recall 的調和平均數
- AUC-ROC — 模型區分正負類別的整體能力
生成式 AI / Agent 評估:
- Groundedness(有據性) — 回答是否基於提供的上下文
- Relevance(相關性) — 回答是否切中問題
- Coherence(連貫性) — 回答的邏輯是否通順
- Safety(安全性) — 回答是否包含有害或偏見內容
Vertex AI Pipelines
Vertex AI Pipelines 用的是 Kubeflow Pipelines 或 TFX 框架,把整個 ML 工作流定義成一張 DAG(有向無環圖),每個步驟都是獨立的容器化元件:
- 資料準備 — 從 BigQuery / Cloud Storage 擷取與前處理
- 訓練 — 在 Vertex AI Training 上執行模型訓練
- 評估 — 自動計算評估指標,與基準模型比較
- 條件部署 — 只有在指標優於基準時才自動部署
- 監控 — 部署後持續監控模型效能與資料漂移
Model Registry
Model Registry 就是統一放模型的地方。同一個模型可以有好幾個版本,每個版本都會記下:
- 訓練時使用的資料集與參數
- 評估指標結果
- 部署狀態(哪些 endpoint 正在使用此版本)
- 標籤與描述(方便搜尋與分類)
A/B 測試(Traffic Split)
Vertex AI Endpoints 支援流量分流。你可以將 90% 的流量導向現有模型,10% 導向新模型,比較兩者在真實環境中的表現。當新模型確認優於舊模型後,再逐步切換全部流量。
實作重點
- Pipeline 定義檔使用 Python SDK(
kfp或google-cloud-aiplatform)撰寫 - 評估步驟應定義「通過閾值」——例如 F1 Score > 0.85 才允許部署
- Model Registry 的版本命名建議使用語意化版號(v1.0.0)加上日期標籤
- A/B 測試至少運行一週,確保樣本量足以做出統計顯著的結論
- 常見陷阱:只看離線評估指標,忽略了線上指標(延遲、throughput、使用者滿意度)
Lab 導讀
Lab 連結:MLOps with Vertex AI: Model Evaluation — Google Cloud Skills Boost
這個 Lab 會帶你做一條端到端的 MLOps Pipeline。你會在 Vertex AI Pipelines 裡定義訓練、評估、部署的自動化流程,用 Model Evaluation 服務算指標,再到 Model Registry 管理模型版本。看的時候特別留意一件事:評估這一步,是怎麼變成自動部署的「品質閘門」的。
延伸學習
- 部署多代理系統 — Agent 部署到 Agent Engine 的託管實踐
- AI 世界的安全導論 — 模型部署的安全考量與風險管控
- Agent Development Kit 智能代理開發 — 回顧 Agent 基礎,結合 MLOps 建構完整流程
相關文章
您可能也會對這些文章感興趣
Vertex AI MLOps 模型評估
深入學習 Vertex AI 的 MLOps 工作流程,掌握模型評估指標、A/B 測試、CI/CD for ML 與模型註冊管理的完整實作
AI 世界的安全導論
全面認識 AI 系統面臨的安全威脅與防禦策略,涵蓋模型安全、資料保護、對抗性攻擊與 GCP 安全工具的實作整合
Data Store Agent 虛擬 FAQ
學習使用 Vertex AI Search 與 Dialogflow CX 建構 Data Store Agent,打造自動化的企業知識問答系統
