GCP 監控與日誌入門:Cloud Monitoring & Cloud Logging 完全指南

你建好了第一台 VM(GCP-103)、設定好 IAM 權限(GCP-105),系統跑起來了。但它跑得好不好,你心裡有底嗎?CPU 有沒有飆高?有沒有錯誤訊息?有沒有人在凌晨三點嘗試入侵?
說真的,最怕的不是出問題,而是出了問題你完全不知道——這就是「可觀測性」(Observability,白話講就是「系統現在到底怎麼了,你看不看得到」)要解決的事,而 GCP 上扛起這件事的主角,就是 Cloud Monitoring 和 Cloud Logging。
兩者都屬於 GCP 的可觀測性工具套件(Google Cloud Observability),這套件下還有幾個核心服務:
| 服務 | 解決什麼問題 |
|---|---|
| Cloud Monitoring | 指標數據、Dashboard、告警、Uptime 檢查 |
| Cloud Logging | 日誌收集、搜尋、路由、匯出 |
| Cloud Trace | 分散式追蹤、請求延遲分析 |
| Cloud Profiler | 程式碼層級的 CPU/記憶體分析 |
| Error Reporting | 應用程式錯誤彙整與通知 |
⚠️ 舊名稱提醒:「Stackdriver」是 2020 年初之前的舊名稱,後來改名為 Cloud Monitoring 和 Cloud Logging(現整合在 Google Cloud Observability 之下)。考試和文件中請以新名稱為準,但仍可能在舊教材或社群討論看到 Stackdriver 這個叫法。
這篇我們會把 Cloud Monitoring 和 Cloud Logging 從頭走一遍——指標怎麼看、Dashboard 怎麼做、告警和 Uptime Check 怎麼設,再到日誌怎麼查、怎麼用 Log Sink 匯出、怎麼從日誌長出監控指標,最後順手裝個 Ops Agent 解鎖記憶體指標。途中該記的 ACE 考點,我都會在旁邊提醒你。
一、Cloud Monitoring:讓數據說話
1.1 什麼是 Cloud Monitoring?
Cloud Monitoring 是 GCP 的代管監控服務,會自動收集 GCP 服務的指標數據,讓你可以:
- 在 Dashboard 上即時視覺化系統狀態
- 設定告警規則,在指標超出閾值時通知你
- 執行 Uptime Check 確認服務持續可用
GCP 服務的指標是自動收集的,你不用額外設定。一建立 VM 或 Cloud SQL,相關指標就會自動送進 Cloud Monitoring。
1.2 指標的三種類型
在 Cloud Monitoring 中,所有指標都屬於以下三種類型之一:
| 類型 | 說明 | 範例 |
|---|---|---|
| Gauge(量規) | 測量某個瞬間的當前值 | CPU 使用率(現在是幾 %?) |
| Delta(差量) | 測量某個時間區間內的變化量 | 每分鐘收到的請求數 |
| Cumulative(累積) | 從某個起點不斷累加的值 | 從服務啟動至今的總請求數 |
實務意義:設告警之前先搞清楚自己用的是哪種指標類型,因為類型不同,數值該怎麼解讀也不一樣。
1.3 Compute Engine 的可用指標
以下是 Compute Engine VM 預設提供的指標:
| 指標 | 說明 | 是否預設提供 |
|---|---|---|
| CPU 使用率 | VM 的 CPU 佔用百分比 | ✅ 是 |
| 磁碟 IOPS | 每秒磁碟讀寫次數 | ✅ 是 |
| 磁碟吞吐量 | 磁碟讀寫速率(bytes/sec) | ✅ 是 |
| 網路流量 | 進出 VM 的位元組數 | ✅ 是 |
| 記憶體使用率 | 記憶體佔用百分比 | ❌ 需安裝 Ops Agent |
| Process-level 指標 | 單一程序的資源使用 | ❌ 需安裝 Ops Agent |
💡 重要陷阱:記憶體使用率不是預設指標!需要在 VM 上安裝 Ops Agent 才能收集。這是 ACE 考試常見的混淆點。
1.4 安裝 Ops Agent(解鎖記憶體等進階指標)
# 方法 1:在 VM 內直接安裝
curl -sSO https://dl.google.com/cloudagents/add-google-cloud-ops-agent-repo.sh
sudo bash add-google-cloud-ops-agent-repo.sh --also-install
# 方法 2:建立 VM 時自動安裝(Agent Policy / OS Config)
# Console 做法:建立 VM 時勾選「Install Ops Agent for Monitoring and Logging」
# → VM Manager 會建立 Ops Agent OS policy(設定 enable-osconfig metadata label)自動安裝並維護 Ops Agent
# gcloud 做法:用 Agent Policy 批次治理整個專案/符合標籤的 VM
gcloud compute instances ops-agents policies create ops-agents-policy-safe-rollout \
--agent-rules="type=ops-agent,version=current-major,package-state=installed,enable-autoupgrade=true" \
--instance-filter-inclusion-labels="env=prod"⚠️ 舊教材常見的
--metadata=google-monitoring-enable=1,google-logging-enable=1對應的是「已棄用的 legacy Monitoring/Logging Agent」,並非 Ops Agent,且該 metadata 只是啟用/停用 image 內預裝的 legacy agent,不會安裝 Ops Agent,請勿使用。
裝好之後,Ops Agent 就會自動開始收集記憶體、程序等進階指標,送到 Cloud Monitoring。
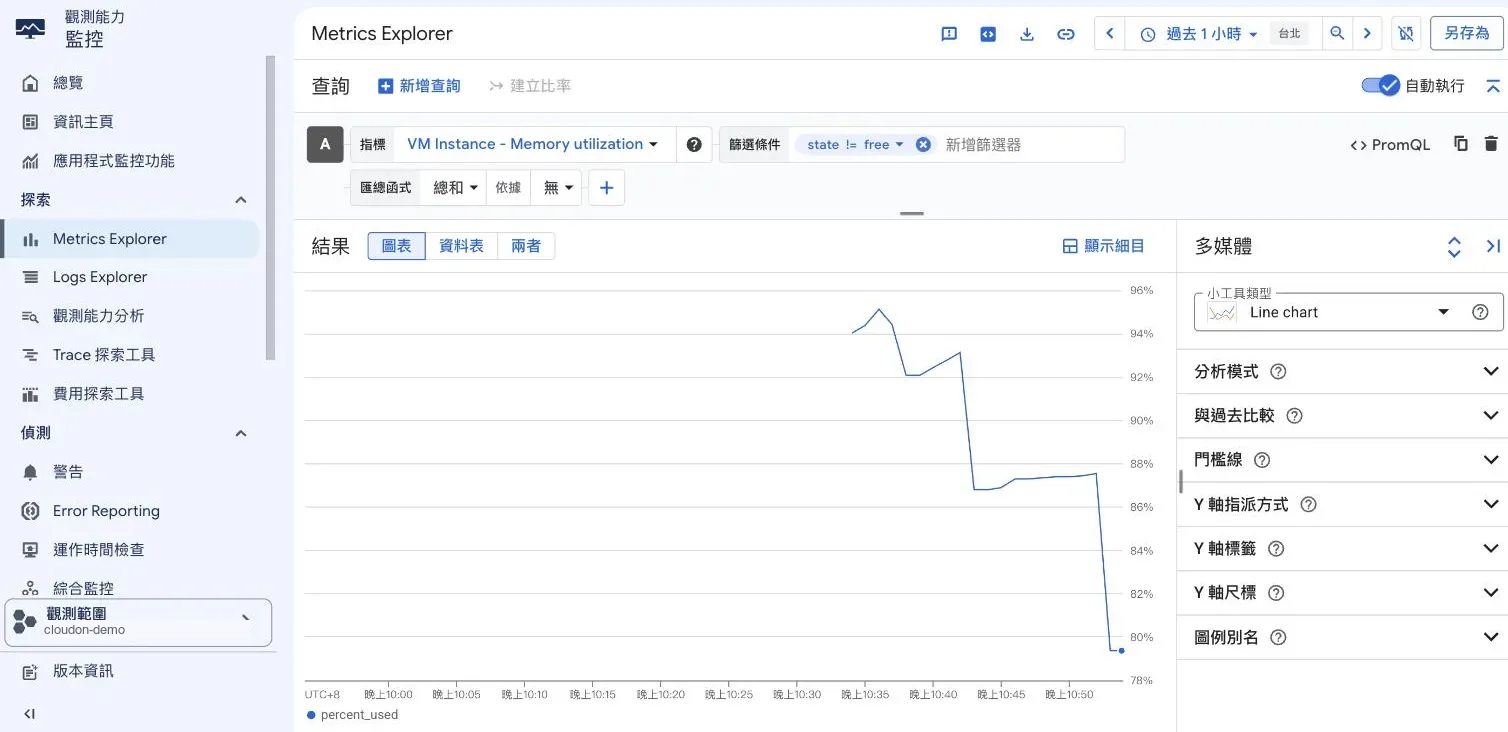
agent.googleapis.com/memory/percent_used——注意那個
agent. 前綴,沒裝 Ops Agent 的 VM 這裡是空的。折線那段起伏,是我在機器上壓了點負載後記憶體的真實變化。
1.5 建立自訂 Dashboard
GCP Console 為每個服務都附了預設 Dashboard,不過你也可以自己做一個:
建立步驟(Console):
- 前往 Cloud Monitoring → Dashboards → Create Dashboard
- 為 Dashboard 命名(例如:「生產環境總覽」)
- 點選 Add Widget 新增圖表:
- Line Chart:適合顯示趨勢(CPU 隨時間變化)
- Gauge:適合顯示當前狀態(目前 CPU 是幾 %)
- Scorecard:大數字顯示單一關鍵指標
- Heatmap:適合顯示延遲分布
- 選擇指標來源(例如:
compute.googleapis.com/instance/cpu/utilization) - 設定圖表維度(按 VM 名稱、Zone 分組等)
gcloud 方式(進階):
# 列出所有可用指標 descriptor(透過 Monitoring API,搜尋 cpu 相關)
# gcloud 沒有對應的子指令,需直接呼叫 Monitoring API
PROJECT_ID=$(gcloud config get-value project)
curl -s -H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://monitoring.googleapis.com/v3/projects/${PROJECT_ID}/metricDescriptors?filter=metric.type%3D%22compute.googleapis.com/instance/cpu/utilization%22" \
| jq -r '.metricDescriptors[].type'1.6 設定 Alerting Policy(告警規則)
告警規則由三個部分組成:
Alerting Policy
├── Condition(什麼條件觸發告警?)
├── Notification Channel(通知誰?用什麼方式?)
└── Documentation(告警說明,可附上 Runbook 連結)實戰:設定 CPU 使用率超過 80% 時發 Email 通知
方法 1:Console 設定(最直覺)
- Cloud Monitoring → Alerting → Create Policy
- Select a metric:
compute.googleapis.com/instance/cpu/utilization - Configure trigger:
- Condition type:
Threshold - Trigger:
Any time series violates - Threshold value:
0.8(即 80%) - Duration:
1 min(持續 1 分鐘才觸發)
- Condition type:
- Configure notifications:新增 Email 通知頻道
- 設定告警名稱並儲存
方法 2:gcloud CLI
# 列出現有的告警政策
gcloud monitoring policies list
# 建立通知頻道(Email)
gcloud beta monitoring channels create \
--display-name="Team Email" \
--type=email \
--channel-labels=email_address=team@yourcompany.com
# 建立告警政策(使用 JSON 設定)
gcloud monitoring policies create \
--policy-from-file=alerting-policy.json常見通知頻道:
| 頻道類型 | 適用場景 |
|---|---|
| 一般告警通知 | |
| Slack | 團隊即時通訊 |
| PagerDuty | 緊急事件待命輪班 |
| Webhook | 自訂整合(LINE Bot、自動化腳本) |
| SMS | 緊急電話通知 |
1.7 Uptime Check:自動監控服務可用性
Uptime Check 會從全球多個位置定期打 HTTP/HTTPS/TCP 請求過去,看你的服務有沒有正常回應。
建立 Uptime Check:
# 透過 Console:Cloud Monitoring → Uptime checks → Create Uptime Check
# 設定:
# - Protocol: HTTPS
# - Resource type: URL
# - Hostname: yourdomain.com
# - Path: /health
# - Check frequency: 1 minute
# - Locations: Asia Pacific, Americas, Europe(建議全選)免費額度:每個 metrics scope(指標範圍——簡單說就是 Cloud Monitoring 計費與聚合資料的單位,預設綁在 billing account 上)每月前 100 萬次 Uptime Check 執行免費。注意計費主體是 metrics scope/billing account,不是單一 project,所以額度是好幾個專案一起共用的,別誤以為每個專案都各有 100 萬次。
💡 重點提點
Uptime Check 的免費額度算的是「整個 billing account」每月前 100 萬次,不是「每個專案」各 100 萬次。很多人在一個帳單帳戶下開了一堆專案,每個都狂設高頻 Uptime Check,結果額度其實是大家共用的,超出就開始按 $0.30/1,000 次計費。設定 Check frequency 時心裡有這條,不要每台服務都無腦設成「每分鐘一次、全球位置全選」。
配合告警:通常會在 Uptime Check 失敗時設個告警通知,這樣服務一掛掉你馬上就知道。
二、Cloud Logging:日誌是問題的第一線索
2.1 什麼是 Cloud Logging?
Cloud Logging 會自動收集 GCP 服務、應用程式和基礎設施的日誌,讓你能搜尋、分析、匯出,也能拿來設告警。
日誌的四大類型:
| 類型 | 說明 | 範例 |
|---|---|---|
| Admin Activity | 修改資源設定或中繼資料的 API 呼叫 | 建立 VM、修改防火牆規則 |
| Data Access | 讀取資源設定或資料的 API 呼叫 | 讀取 Cloud Storage 物件 |
| System Event | GCP 系統本身的修改事件 | VM 自動重新排程、維護事件 |
| Policy Denied | 因安全政策拒絕的存取嘗試 | IAM 拒絕的 API 呼叫 |
2.2 稽核日誌啟用與配置(ACE 必考)
| 稽核日誌類型 | 預設啟用 | 可停用 | 費用 |
|---|---|---|---|
| Admin Activity | ✅ 永遠啟用 | ❌ 不可停用 | 免費 |
| System Event | ✅ 永遠啟用 | ❌ 不可停用 | 免費 |
| Policy Denied | ✅ 永遠啟用 | ❌ 不可停用 | 免費 |
| Data Access | ❌ 預設停用 | ✅ 可手動啟用 | 計費(量可能很大) |
# 查詢 Admin Activity 稽核日誌(誰做了什麼操作)
gcloud logging read 'logName="projects/my-project/logs/cloudaudit.googleapis.com%2Factivity"' \
--limit=20 --format=json
# 查詢 Data Access 日誌(誰讀取了什麼資料)
gcloud logging read 'logName="projects/my-project/logs/cloudaudit.googleapis.com%2Fdata_access"' \
--limit=10啟用 Data Access 日誌(需手動開啟):
# 在 IAM 政策中啟用 Data Access 日誌
# Console → IAM & Admin → Audit Logs → 選擇服務 → 勾選 Data Read / Data WriteACE 考試重點:Admin Activity 日誌永遠啟用、不可停用、免費。Data Access 日誌預設停用、需手動啟用、會計費。遇到「如何追蹤誰刪除了 VM」的題目,答案是 Admin Activity audit log。
2.3 日誌保留期限
日誌保留期限是按照日誌 Bucket而不是日誌類型來計算的:
| Bucket | 預設保留期 | 說明 |
|---|---|---|
| _Required | 400 天(不可更改) | 稽核日誌(Admin Activity、System Event,及 Access Transparency) |
| _Default | 30 天(可設定 1-3,650 天) | 一般應用程式日誌、Data Access 與 Policy Denied 稽核日誌 |
| 自訂 Bucket | 30 天(可設定) | 你自行建立的 Bucket |
2.4 Log Explorer:搜尋與分析日誌
Log Explorer 是 Cloud Logging 的主要 UI,支援強大的查詢語法。
基本查詢語法:
# 查看特定資源類型的日誌
resource.type="gce_instance"
# 查看特定嚴重等級以上的日誌
severity >= "ERROR"
# 同時過濾資源類型和嚴重等級
resource.type="gce_instance" AND severity >= "WARNING"
# 查看特定 VM 的日誌
resource.type="gce_instance" AND
resource.labels.instance_id="1234567890"
# 查看 Cloud Run 服務的日誌
resource.type="cloud_run_revision"
# 搜尋包含特定文字的日誌
textPayload:"error connecting to database"
# 查看特定時間範圍(前一小時)
timestamp >= "2026-03-11T10:00:00Z" AND
timestamp <= "2026-03-11T11:00:00Z"嚴重等級(Severity)由低到高:
DEBUG → INFO → NOTICE → WARNING → ERROR → CRITICAL → ALERT → EMERGENCY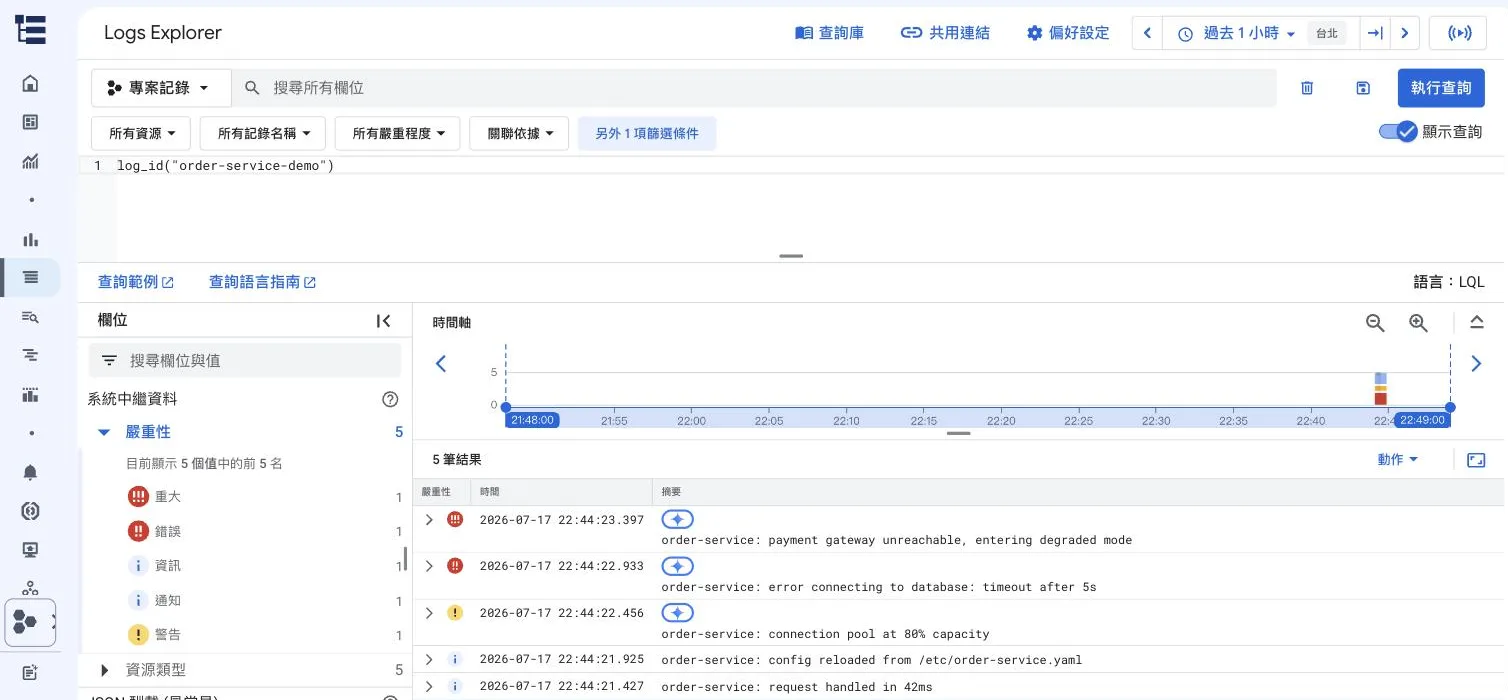
2.5 gcloud 查詢日誌
# 查詢 Compute Engine 最新 10 筆日誌
gcloud logging read "resource.type=gce_instance" --limit=10
# 查詢 ERROR 以上等級的日誌
gcloud logging read "severity>=ERROR" \
--limit=20 \
--format=json
# 列出專案中所有的 Log 名稱
gcloud logging logs list
# 查詢特定 Log 的內容
gcloud logging read 'logName="projects/my-project/logs/cloudaudit.googleapis.com%2Factivity"' \
--limit=52.6 Log Sink:日誌路由與匯出
日誌預設都存在 Cloud Logging 的 Bucket 裡。如果你要長期保存、分析,或是接到其他系統,就可以用 Log Sink 把日誌路由到:
| 目的地 | 適用場景 |
|---|---|
| BigQuery | 長期保存、SQL 查詢分析 |
| Cloud Storage | 低成本封存(GCS bucket) |
| Pub/Sub | 串流到 Splunk、Datadog 等第三方系統 |
| 其他 Cloud Logging Bucket | 集中管理多個專案的日誌 |
建立 Log Sink(匯出到 BigQuery):
# 1. 建立 BigQuery Dataset
bq mk --location=asia-east1 my_logs_dataset
# 2. 建立 Log Sink
gcloud logging sinks create my-bigquery-sink \
bigquery.googleapis.com/projects/my-project/datasets/my_logs_dataset \
--log-filter='resource.type="gce_instance" AND severity>=WARNING'
# 3. 查看 Sink 的 Service Account(需要授予 BigQuery 寫入權限)
gcloud logging sinks describe my-bigquery-sink
# 4. 授予 Sink 的 SA 寫入 BigQuery 的權限
gcloud projects add-iam-policy-binding my-project \
--member="serviceAccount:SINK_WRITER_IDENTITY" \
--role="roles/bigquery.dataEditor"建立 Log Sink(封存到 Cloud Storage):
# 建立 GCS Bucket
gsutil mb -l asia-east1 gs://my-logs-archive-bucket
# 建立 Log Sink
gcloud logging sinks create my-gcs-sink \
storage.googleapis.com/my-logs-archive-bucket \
--log-filter='resource.type="gce_instance"'常見的還有「把全部稽核日誌集中到 BigQuery 做合規分析」這種用法,filter 直接針對 cloudaudit.googleapis.com 撈:
# 把所有稽核日誌匯出到 BigQuery 做分析
gcloud logging sinks create audit-to-bq \
bigquery.googleapis.com/projects/my-project/datasets/audit_logs \
--log-filter='logName:"cloudaudit.googleapis.com"'2.7 Log-based Metrics:從日誌建立指標
有時候你會想根據日誌內容來觸發告警,例如:「日誌裡一出現 ‘connection refused’ 就通知我」。這時就輪到 Log-based Metrics 上場。
類型:
- Counter:計算符合條件的日誌條目數量(每分鐘幾筆錯誤?)
- Distribution:從日誌中提取數值分布(API 回應時間分布)
- Boolean:是否有符合條件的日誌出現(True/False)
建立 Log-based Counter(計算 HTTP 500 錯誤次數):
gcloud logging metrics create http-500-errors \
--description="Count of HTTP 500 errors" \
--log-filter='resource.type="gce_instance" AND
jsonPayload.statusCode=500'建好之後,這個指標就會出現在 Cloud Monitoring 裡,拿來設告警或做 Dashboard 都行。
2.8 Log-based Alerting
你也可以直接在 Cloud Logging 裡設告警,特定日誌一出現就發通知:
Cloud Logging → Log-based alerts → Create alert
設定觸發條件:「當 severity=CRITICAL AND resource.type=gce_instance 的日誌出現時,每 1 分鐘最多通知一次」
三、GCP 可觀測性工具家族
除了 Cloud Monitoring 和 Cloud Logging,GCP 還有幾個相關工具:
3.1 Cloud Trace:分散式追蹤
當你的應用由多個微服務組成,一個請求可能會經過 A → B → C → D 好幾個服務。Cloud Trace 幫你追每個請求的完整路徑,還有每一站花了多少延遲:
適用場景:
- 找出哪個服務造成整體延遲高
- 追蹤一個用戶請求在各服務間的流轉路徑
整合方式:在應用程式中引入 OpenTelemetry SDK(支援 Go、Java、Node.js、Python),Trace 數據自動送到 Cloud Trace。
3.2 Cloud Profiler:程式碼效能分析
Cloud Profiler 會用極低的額外負擔,持續分析生產環境中應用程式的 CPU 和記憶體使用情況,而且直接對應到原始碼的行數。
支援語言:Go、Java、Node.js、Python
適用場景:「我的服務很慢,但我不知道是哪段程式碼造成的」
3.3 Error Reporting:應用程式錯誤彙整
Error Reporting 會自動彙整、分類應用程式拋出的例外(Exception),讓你一眼看出「最常發生的錯誤是哪一個」。
支援平台:App Engine、Cloud Functions、Cloud Run、Compute Engine、GKE
注意:行動應用程式的 Crash 監控建議使用 Firebase Crashlytics。
四、免費額度與定價
Cloud Logging 免費額度(每月)
| 項目 | 免費額度 |
|---|---|
| 一般日誌儲存 | 每個專案前 50 GiB 免費 |
| Log Routing | 永遠免費 |
| _Required bucket(稽核日誌,400 天保留) | 永遠免費 |
超出後:$0.50/GiB(一般日誌)
Cloud Monitoring 免費額度(每月)
| 項目 | 免費額度 |
|---|---|
| GCP 服務的非計費指標 | 無限量免費(CPU、網路等) |
| 計費指標(自訂指標等) | 前 150 MiB 免費 |
| Uptime Check | 每個 billing account 每月前 100 萬次免費 |
| Write API | 永遠免費 |
定價和免費額度會隨時間調整,這裡的數字幫你抓個量級就好,實際請以 Google Cloud Observability 官方定價頁 為準。
五、ACE 考試重點整理
Cloud Monitoring 和 Cloud Logging 在 ACE 考試裡出現的頻率很高,以下是幾種常見題型:
類型 1:指標選擇
題目:你想監控 VM 的記憶體使用率,但在 Cloud Monitoring 中找不到記憶體相關指標。最可能的原因是?
- ❌ Cloud Monitoring 不支援記憶體指標
- ❌ 需要付費升級才能使用記憶體指標
- ✅ Ops Agent 尚未安裝(記憶體指標需要 Ops Agent)
類型 2:日誌匯出
題目:你需要將 GCP 日誌長期保存並用 SQL 分析。最適合的做法是?
- ❌ 增加 Cloud Logging 的 _Default Bucket 保留期
- ✅ 建立 Log Sink,將日誌匯出到 BigQuery
類型 3:告警設定
題目:你的 Web 服務需要在回應時間超過 2 秒時通知工程師。應使用哪個工具?
- ✅ Cloud Monitoring Alerting Policy,設定
http/server_latency指標的閾值
類型 4:日誌類型
題目:你想查看過去 7 天內誰修改了你的防火牆規則。應查看哪種日誌?
- ❌ System Event Logs(GCP 系統事件,不是人為操作)
- ❌ Data Access Logs(讀取資料,不是修改設定)
- ✅ Admin Activity Logs(修改資源設定的 API 呼叫)
類型 5:保留期限
題目:Admin Activity 日誌的預設保留期是多少天?
- ✅ 400 天(儲存在 _Required bucket,不可修改)
六、實戰演練:端對端監控設定
以下用一台 Compute Engine VM 為例,把完整監控設起來:
# Step 1: 安裝 Ops Agent(解鎖記憶體等指標)
# 在 VM 內執行:
curl -sSO https://dl.google.com/cloudagents/add-google-cloud-ops-agent-repo.sh
sudo bash add-google-cloud-ops-agent-repo.sh --also-install
# 確認 Ops Agent 正在執行
sudo systemctl status google-cloud-ops-agent
# Step 2: 設定 Uptime Check(Console 操作)
# Cloud Monitoring → Uptime checks → Create
# 填入: HTTPS, yourdomain.com, /health, Check every 1 minute
# Step 3: 建立告警政策(CPU > 80%)
# Cloud Monitoring → Alerting → Create Policy
# Metric: compute.googleapis.com/instance/cpu/utilization
# Threshold: 0.8, Duration: 1 min
# Notification: Email to your team
# Step 4: 建立 Log Sink(匯出 ERROR 日誌到 BigQuery)
gcloud logging sinks create production-errors-sink \
bigquery.googleapis.com/projects/my-project/datasets/production_logs \
--log-filter='resource.type="gce_instance" AND severity>=ERROR'
# Step 5: 查詢日誌確認設定正確
gcloud logging read \
'resource.type="gce_instance" AND severity>=ERROR' \
--limit=5 \
--format=table七、總結
Cloud Monitoring 核心記憶點:
| 功能 | 關鍵點 |
|---|---|
| 記憶體指標 | 需安裝 Ops Agent |
| 指標類型 | Gauge(瞬間值)/ Delta(區間變化)/ Cumulative(累積) |
| Dashboard | 預設為唯讀,可自訂 |
| 告警 | 條件 + 通知頻道 + 文件說明 |
| Uptime Check | 全球位置、HTTP/HTTPS/TCP |
Cloud Logging 核心記憶點:
| 功能 | 關鍵點 |
|---|---|
| 保留期 | _Required: 400 天;_Default: 30 天 |
| Admin Activity 日誌 | 修改資源設定的操作,保留 400 天 |
| Log Sink | 匯出到 BigQuery / GCS / Pub/Sub |
| Log-based Metrics | 從日誌建立 Cloud Monitoring 指標 |
| 查詢語法 | resource.type, severity, timestamp, textPayload |
系列文章連結
- 📖 上一篇:GCP-105: GCP IAM 完全指南
- 📖 下一篇:ACE-207: Terraform on GCP 實戰指南
- 📖 進階延伸:ACE-205: 企業級資安防護
延伸閱讀
- Cloud Monitoring 官方文件
- Cloud Logging 官方文件
- Logging Query Language 語法參考
- Log Sinks 設定指南
- Ops Agent 安裝指南
- Cloud Monitoring 定價
監控和日誌搞定了,下一步通常就是煩惱「資料要存哪、怎麼存才不會又貴又慢」。系列下一階段我們就來聊 GCP 的資料儲存策略,到時候見。
相關文章
您可能也會對這些文章感興趣

GCP 監控與日誌入門:Cloud Monitoring & Cloud Logging 完全指南
從零開始掌握 GCP 可觀測性工具!完整解析 Cloud Monitoring 指標類型、自訂 Dashboard、Alerting Policy 告警設定、Uptime Check;Cloud Logging 日誌查詢、Log Sink...

Google Cloud Storage 指南:儲存類別、權限、生命週期與防刪除
從 Bucket、Flat 與 Hierarchical Namespace 開始,整理 Cloud Storage 位置、儲存類別、Autoclass、IAM、Signed URL、Lifecycle、Soft Delete、版本控制與成...

GCP-108:Cloud SQL 入門——托管關聯式資料庫完全指南
深入了解 Google Cloud SQL 托管關聯式資料庫服務,涵蓋 MySQL、PostgreSQL、SQL Server 支援版本、高可用架構、連線方式、備份策略,以及 ACE 考試必考知識點。
