PCA 雲端架構師之旅 11 — 可靠性與擴展性

拓樸畫完,下一個要回答的問題很現實,也是老闆半夜會跳起來想的那個:這套架構,撐得住嗎?
撐得住其實藏著兩件事。一是可靠性——一台機器掛了,服務還能繼續跑;二是擴展性——流量突然衝上來,系統接得住。它們聽起來像兩個題目,但你做久了會發現解法重疊得很厲害,繞來繞去都是同一套口訣:無狀態、多副本、自動化。
這是 13 步驟 PCA 雲端架構師之旅 的第十一站。PCA 考題特別偏愛用「雙 11 活動流量是平日 20 倍」或「整座機房跳電」這種劇本來戳你,看你是真的懂韌性,還是只會背名詞。
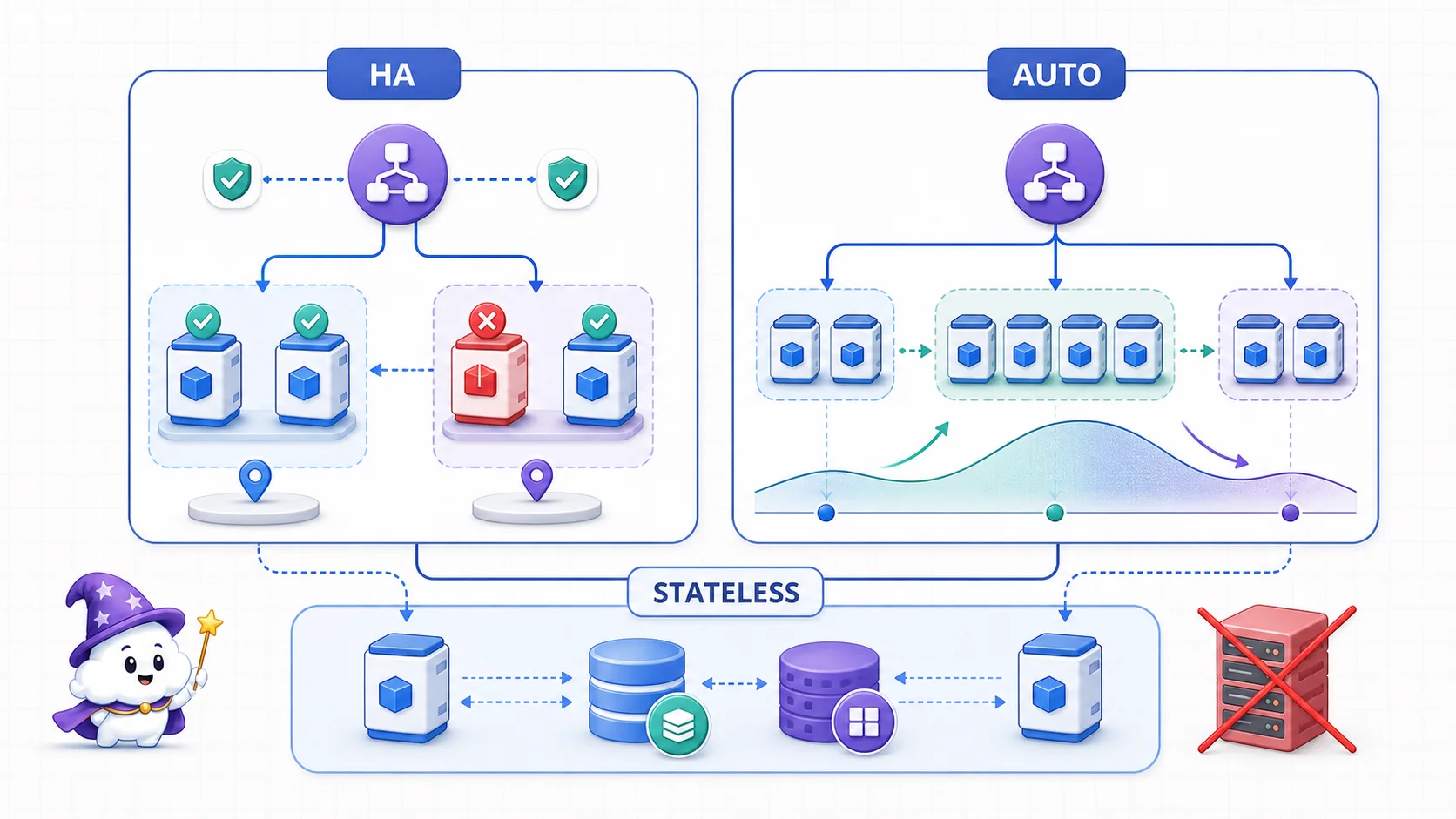
圖解:可靠性回答「一個副本壞了還能不能服務」,擴展性回答「流量變多時能不能加副本」。兩者共同地基是 stateless:應用副本不把 session 鎖在自己身上,狀態放到外部資料庫或快取,故障切換與 autoscaling 才能真的生效。
可靠性跟擴展性,先把它們分清楚
很多人一聽到「高可用」就直接想到「我有備份啊」,這是考場上最常見的第一個坑。
備份是資料保護——東西壞了、刪錯了,你還救得回來。高可用(HA,High Availability)是服務可用——一台節點掛掉的當下,使用者根本不該察覺。兩件事都要做,但它們解的是完全不同的問題。我看過不少團隊把每日備份做得滴水不漏,結果某個 zone 一出狀況,服務直接躺平兩小時——備份完整無缺,但那兩小時的訂單就是進不來。對電商來說,那兩小時就是真金白銀。
擴展性(Scalability)則是另一條軸線:平常五台機器夠用,雙 11 那天要五十台,活動結束又縮回去。重點不只是「加得上去」,還包括「加得夠快」跟「縮得回來」——縮不回來,你的雲端帳單會讓財務長找你喝咖啡。
這兩條軸線的交集,就是這篇要講的東西。好消息是它們共用一套底層思路,壞消息是 PCA 很愛在「看起來都對」的選項裡,埋一個剛好不滿足 SLA 的陷阱。
SLA 那幾個 9,背起來真的有用
PCA 考題很喜歡丟一句「SLA 要求 99.95%」,然後要你判斷單一 region 的 Cloud SQL HA 夠不夠。這時候你腦袋裡得有一張換算表,秒答:
- 99.9%(3 個 9)≈ 每月停機 43 分鐘
- 99.95% ≈ 每月停機 22 分鐘
- 99.99%(4 個 9)≈ 每月停機 4 分鐘
別小看這幾個數字。99.9% 跟 99.99% 看起來只差一個 9,月停機容忍度卻從 43 分鐘掉到 4 分鐘——這中間的差距,往往就是「單 region 撐得住」跟「非得跨 region」的分水嶺。SLA 每往上加一個 9,成本通常不是線性成長,是翻著跳。這個取捨我們留到第 13 步成本那篇再深入,這裡你先記住一件事:SLA 數字是業務需求,不是技術願望。客戶說要四個 9,你得回頭問他願不願意付四個 9 的錢。
📝 考場提點
看到題目寫死 SLA 數字,先在草稿紙上把它換成月停機分鐘數,再去對選項。常見陷阱長這樣:題目要 99.99%,選項給你「單一 region、Cloud SQL 啟用 HA」——這配置很標準、很漂亮,但單 region 架構天花板大約落在 99.95% 上下,碰到整個 region 級的事件就破功,剛好壓不到四個 9。真正的答案通常是「跨 region 部署 + 全域負載平衡」。記住:region 內 HA 解的是 zone 失效,region 失效要靠跨 region。
無狀態,是這整篇的地基
如果這篇你只能帶走一句話,那就是:讓你的應用變成無狀態(stateless)。
無狀態的意思是,任何一個實例(instance)都能接任何一個請求,因為它身上不存任何「只有它知道」的東西。使用者的 session、購物車、上傳到一半的檔案——這些 state 全都搬到外部去:session 丟 Memorystore,檔案丟 GCS,認證用 JWT 放 cookie 自己帶。
為什麼這是地基?因為 autoscaling 的整個前提就是它。autoscaler 要能隨時起一台新的、隨時砍掉一台舊的,如果 state 黏在某台機器的記憶體裡,砍掉那台 = 那些使用者的 session 蒸發,當場被登出。我實在看過太多這種案例了:團隊圖方便,把 session 直接存在應用程式本機記憶體,平常單機跑得好好的,一開 autoscaling 就災難——縮容一觸發,一批使用者莫名其妙被踢出去重登,客服電話被打爆。問題不在 autoscaler,在那個沒人改的有狀態設計。
所以順序很重要:先把應用改成無狀態,autoscaling 才有意義。真的改不動的有狀態服務(有些老系統就是這樣),退而求其次用 sticky session 或外部 state store,但那是補丁,不是首選。
把韌性拆成四個可以逐一檢查的面向
實務上設計韌性,我習慣把它切成四塊,一塊一塊過,免得漏。考試也是同一套維度,這張對照表值得記熟:
| 維度 | 你要解決的問題 | GCP 常用工具 |
|---|---|---|
| 高可用 (HA) | 單點掛掉不影響服務 | Regional MIG、Cloud SQL HA、GKE regional cluster |
| 自動擴展 (Autoscaling) | 流量變動自動加減 | MIG autoscaler、GKE HPA / VPA / Cluster Autoscaler、Cloud Run |
| 無狀態設計 (Stateless) | 任何實例都能接任何請求 | 外部 session store(Memorystore)、JWT、外部檔案存 GCS |
| 故障轉移 (Failover) | 主故障自動切備 | Cloud SQL failover、multi-region LB、DNS failover |
這張表不是要你硬背,是當你拿到一個元件時,照著它問自己一輪:這東西的單點故障在哪?它是有狀態還是無狀態?它的 autoscaling 該看什麼指標觸發、CPU 還是 QPS、冷啟動時間能不能接受?它失效的時候,切換要多久——人手動切是分鐘級、自動切是秒級、還是根本不能切(0 容忍)?最後別忘了問擴展上限:GCP 的 quota 你申請夠了嗎?instance 數量、external IP 這些都有上限,雙 11 當天才發現 quota 卡住,叫天天不應。
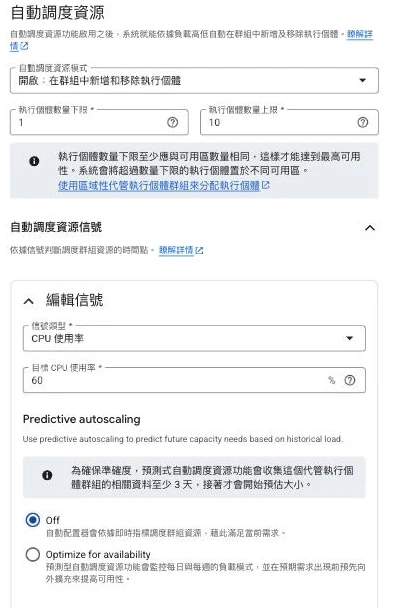
這張把水平自動擴縮的三個旋鈕一次擺齊:下限/上限(1 到 10)圈出 MIG 能伸縮的範圍,CPU 使用率目標 60% 決定它何時動手。這裡藏一個很多人讀錯的點——60% 不是「CPU 一過 60% 就加一台」的門檻,而是「目標追蹤」:MIG 會持續增減 VM,設法讓整群的平均 CPU 貼著 60% 跑。最下面那個 Predictive autoscaling 也別略過,切到 Optimize for availability 就是 Google 內建的預熱——它會依歷史負載預測尖峰、提前把 VM 開好,正好是本篇後面說的「瞬間尖峰要靠預熱」的現成解。
最後那個 quota,是真的會在實戰裡咬人的一條。預設 quota 常常不夠你尖峰用,而調高 quota 的審核要時間。所以但凡你規劃了一個會大幅 scale-out 的架構,提前幾週把 quota 申請單送出去——這是工作上會踩、考試也愛考的細節。
走一遍範例 — 登雲書店
回到我們的老朋友。登雲書店目標 SLA 99.95%,雙 11 流量會衝到平日 15 倍。把上面那四個面向套到它身上,設計大概長這樣:
前端(GKE regional cluster)
- Regional cluster 橫跨 3 個 zone,控制平面 HA 由 GCP 代管
- Pod 以 HPA 擴展,觸發條件:CPU > 60% OR 自訂 metric
requests_per_second > 80 - Cluster Autoscaler 自動加 node(上限 100 個 node,預先申請 quota)
- Pod 設
topologySpreadConstraints,分散到三個 zone,不讓單 zone 失效造成大範圍中斷
後端服務(Cloud Run)
- 無狀態設計,session 存 Memorystore for Redis
- Cloud Run min instances = 5(避免冷啟動)、max = 500
- 請求並發(concurrency)設 80,避免單 container 被打爆
資料庫(Cloud SQL for PostgreSQL)
- 啟用 HA(primary + standby,不同 zone),自動 failover
- 加 2 個 read replica 分散讀取
- 備份每日 + Point-in-Time Recovery(PITR)開啟 7 天
瀏覽紀錄(Bigtable)
- 單叢集 3 節點,CPU > 70% 自動加節點
- 關鍵時刻(雙 11 前三天)手動 pre-scale 到 6 節點,活動後縮回
流量進入層
- Global External Application LB,內建跨 region failover
- Cloud Armor 設 rate limit:單 IP 每分鐘 300 req,防爬蟲攻擊
- Cloud DNS A record TTL 設 60 秒(讓 DR 切換快)
這套設計裡有個細節特別值得拿出來講,因為它是 PCA 的高頻陷阱——Cloud SQL HA 的 standby 是 hot standby,但你不能直接拿它來讀。很多人第一直覺是「我都有一台 standby 了,讀流量分一半過去不就好了?」不行。那台 standby 純粹是為了 failover 待命的,平常不對外服務。你要分散讀取,得另外開 read replica(範例裡那 2 台就是幹這個的),或者升級到 AlloyDB。
我特別點出這個,是因為它直接戳中一個觀念混淆:HA 跟 read scaling 是兩回事。HA 解的是「主掛了有人頂」,read scaling 解的是「讀太多分散負載」。一台機器同時兼這兩個角色聽起來很省,但 Cloud SQL 就是不讓你這樣玩,這也正是考題愛埋的點。
📝 考場提點
「Cloud SQL HA standby 能不能直接讀」幾乎是必考題,答案是不能,它只待命做 failover。題目若同時要求「高可用」又要「分散讀取負載」,正確配置是 HA(primary + standby)外加 read replica,兩個一起上,不要想用一台解決。看到選項寫「啟用 HA 讓 standby 承接讀流量」就直接刪掉。另外提醒一個時間分配的小技巧:case study 那種大題,先把每個元件對到「HA / autoscaling / stateless / failover」四格,比你逐字重讀題目快得多,也比較不會漏掉某一層。
那些上線後才發現的坑
設計圖畫得再漂亮,真正會出事的往往是這幾個地方。考試會考,工作上更會親自教訓你。
session 存在 Pod 記憶體裡,這個前面講過但值得再罵一次。 autoscaling 一縮容,session 跟著消失,使用者突然登出。正解就是把 session 搬到 Memorystore,或用 JWT 放 cookie 讓使用者自己帶著走。這條是無狀態原則的直接後果,犯了基本上代表前面的地基沒打好。
資料庫連線池(connection pool)沒人調,是另一個經典的隱形殺手。 Cloud SQL 的連線數有上限(依 tier 而定),平常沒事,等你 autoscaling 把 Pod 開到幾百個、每個 Pod 各自開一個 connection pool,連線數瞬間爆表,資料庫直接拒絕新連線——諷刺的是,你的 autoscaling 越成功,這個問題炸得越快。對策是上 Cloud SQL Auth Proxy 配合合理的 max_connections,或者在前面架一層 PgBouncer 統一管理連線。我的經驗是,這個問題在壓測階段不一定看得出來,常常是真實尖峰才現形,所以容量規劃時就要把它算進去。
autoscaler 反應不夠快,這條最容易讓人措手不及。 很多人以為設了 autoscaling 就高枕無憂,其實它有延遲。以 GKE HPA 為例,控制器預設每 15 秒同步一次指標、scale-up 沒有穩定視窗(0 秒),但 scale-down 預設要等 300 秒的穩定視窗——也就是說突發流量打進來的那前幾分鐘,新 Pod 還沒長出來,現有的就先被打爆了。怎麼救?三招:min replicas 設一個撐得住基本盤的底線、可預期的尖峰(像雙 11)事先預熱(pre-warm)、或者乾脆改用 Cloud Run 這種冷啟動快很多的服務。一句話總結:autoscaling 是用來接住「漸進成長」的,不是用來接「瞬間尖峰」的,瞬間尖峰要靠預熱。
延伸閱讀
- Google Cloud 架構框架:可靠性 — 官方韌性設計原則,PCA 考題的引用來源。
- Compute Engine Managed Instance Group — MIG 的 HA 與 autoscaling 機制。
- GKE Autoscaling 指南 — HPA / VPA / Cluster Autoscaler 怎麼搭配。
- Cloud SQL 高可用 — 把 standby 不能讀這件事看清楚。
系列導航
- 系列首頁:PCA 雲端架構師之旅
- 上一篇:PCA 雲端架構師之旅 10 — 網路拓樸
- 下一篇:PCA 雲端架構師之旅 12 — 災難復原 (DR)
下一步:可靠性顧的是「平常別掛」,但萬一整個 region 真的出事呢?下一篇我們進到災難復原(DR),談 RTO / RPO 跟備援策略,把最壞的情況也想清楚。
🎯 換你練習
理論讀完,換自己來。到 架構師設計工作坊 · 步驟 11 填入你的 case study,邊寫邊內化。
相關文章
您可能也會對這些文章感興趣

PCA 雲端架構師之旅 11 — 可靠性與擴展性
設計高可用與可擴展的架構:HA 策略、autoscaling、多區部署、無狀態設計、failover。PCA 架構師的韌性思維。

PCA 雲端架構師之旅 01 — 讀懂案例情境
PCA 考試第一步就是讀懂 case study。本文帶你拆解業務目標、技術限制、利害關係人,避免沒看完題目就開始選 GCP 服務。

PCA 雲端架構師之旅 02 — 定義 User Personas
PCA 架構設計不是畫服務圖,而是從使用者開始。本文教你定義 User Persona,讓後續的 SLO、API、儲存選型都有依據。
