PCA 雲端架構師之旅 07 — 儲存特性分析

「這個要用 Cloud SQL 還是 Spanner?Firestore 還是 Bigtable?」這大概是 PCA 考試裡出現頻率最高的一類題,也是實務上最常被人憑感覺亂選的東西。
但這題其實不該用「選服務」的方式去想。順序反了。你該先把資料攤開來看清楚——它長什麼樣、多大、讀多還寫多、能不能接受慢一點才一致——讓資料的特性自己把選項收斂掉。這篇就先做這一步,特性分析(characteristics analysis),完全不碰服務選型。服務名稱一個都別急著講。
這是 PCA 雲端架構師之旅 的第七步。上一篇 06 · REST API 設計。
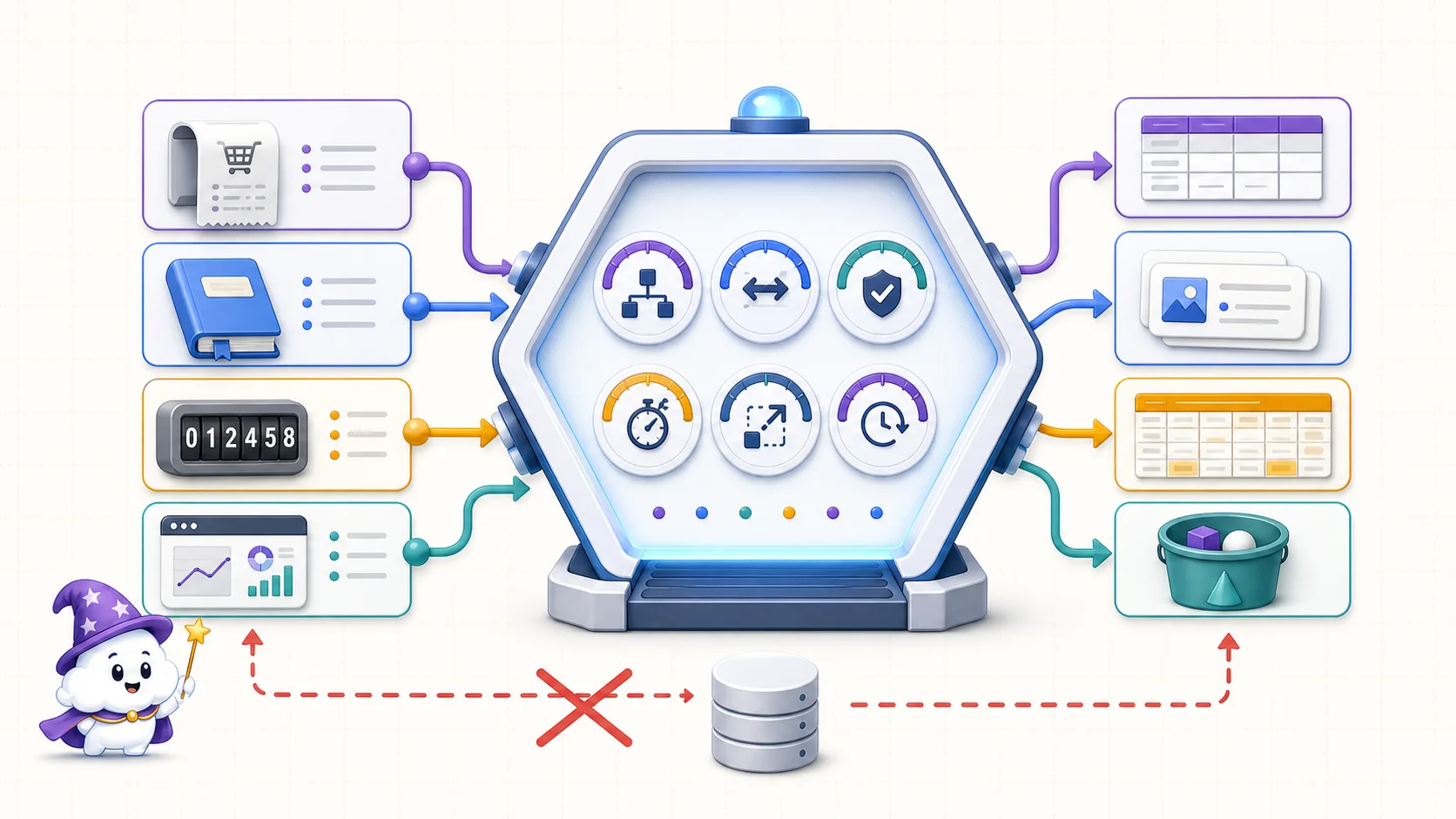
圖解:訂單、檔案、即時庫存與分析事件的脾氣不同。先檢查結構、讀寫模式、一致性、延遲、規模與生命週期,才會自然分流到關聯式、文件、寬欄或物件儲存;跳過這一步,常會把所有資料硬塞進同一個資料庫。
為什麼要先分析、後選型
我看過太多團隊一上來就在白板上寫服務名字。「流量會爆,用 Spanner 吧」「這是 NoSQL,丟 Firestore」——聽起來很果斷,但十次有八次選錯,因為他們根本還不知道自己在存什麼。
最經典的反面教材,是把所有東西塞進同一個資料庫。早期圖快,訂單、商品、使用者行為、報表查詢全擠在一台 Cloud SQL 上。前半年沒事,等資料量上來,分析查詢一跑,整台機器的交易延遲就被拖垮,下單變慢、客訴進來,最後只好半夜緊急把分析流量搬走。這種痛,每個做久的人多少都經歷過一次。問題從來不在 Cloud SQL 不夠好,而在於一開始沒去區分「這些資料的脾氣根本不一樣」。
所以特性分析不是考試專用的形式主義。它是讓你在動手前,先承認一件事:你手上不是「一坨資料」,而是好幾種脾氣完全不同的資料,硬要它們住同一間房,遲早出事。
考試把這件事濃縮了。PCA 的 case study 幾乎都會丟給你資料量、成長率、查詢模式的線索——「訂單每年 2000 萬筆、保留 7 年、需要跨區強一致」「使用者點擊紀錄每日 5 億筆」。這些數字看起來像背景設定,其實是出題者把答案的一半藏在裡面:能跨區強一致又能裝 7 年訂單的服務,本來就沒幾個。題目不會明說答案,它丟幾個似是而非的選項,等你用資料特性把錯的刪掉。
📝 考場提點
看到資料量、成長率、保留年限、一致性要求這些字眼,立刻在草稿紙上把它標出來,這幾乎都是消去法的鑰匙。「每日 5 億筆」直接刪掉 Cloud SQL;「跨區強一致」基本上把答案推向 Spanner;「保留 7 年但平常很少查」就是在提示你做冷熱分層。別一看到「關聯式」就反射選 Cloud SQL——出題者最愛在這種地方放陷阱。
該從哪幾個角度看一筆資料
把一筆資料拿在手上,值得問的角度其實就這幾個。我習慣這樣盤:
| 維度 | 你要問自己的問題 |
|---|---|
| 結構(Structure) | 結構化、半結構化、非結構化? |
| 規模(Size) | 單筆多大?總量多少?成長率? |
| 讀寫比(R/W Ratio) | 讀多寫少?寫多讀少? |
| 一致性(Consistency) | 強一致還是最終一致? |
| 延遲(Latency) | 毫秒級?秒級?分鐘級? |
| 查詢模式(Access Pattern) | 點查?範圍查?全文檢索?聚合? |
| 生命週期(Lifecycle) | 熱、溫、冷、歸檔的時程? |
| 敏感度(Sensitivity) | PII、PCI、PHI 合規要求? |
這八個裡,新手最常漏掉的是讀寫比跟生命週期。同樣是「訂單」,讀寫比 1:1 跟 100:1,背後的架構天差地遠;保留 7 年的訂單和保留 7 天的點擊紀錄,成本策略也完全不是同一回事。我會特別盯這兩欄,因為它們最容易被「反正是關聯式資料」這種粗分類蓋過去。
至於 GCP 這邊有哪些武器可以對應,先放一張對照表打底——這篇還不選,但你心裡得有個地圖:
| 服務 | 定位 | 關鍵字 |
|---|---|---|
| Cloud SQL | 中小型關聯式 | MySQL/PostgreSQL/SQL Server、zonal/regional HA |
| AlloyDB | 高效能 PostgreSQL | 高 OLTP + 分析工作負載 |
| Spanner | 全球強一致關聯式 | multi-region、horizontal scale、SQL |
| Firestore | 文件資料庫 | 行動/Web、即時同步、中小規模 |
| Bigtable | 寬列 NoSQL | 超大量時間序列、IoT、低毫秒延遲 |
| BigQuery | 分析型資料倉儲 | PB 級 OLAP、columnar、SQL |
| Memorystore | 記憶體快取 | Redis/Memcached、毫秒以下 |
| Cloud Storage | 物件儲存 | 大檔案、備份、靜態資產 |
| Filestore | 網路檔案系統 | NFS、legacy lift-and-shift |
對照表裡最該記牢的分水嶺是 OLTP 和 OLAP。OLTP(線上交易處理,Online Transactional Processing)寫得多、一次動一筆、要求低延遲,下單就是典型;OLAP(線上分析處理,Online Analytical Processing)反過來,大量讀、做聚合、可以等個幾秒。一筆資料是哪一種,幾乎就決定了它該住哪一棟。把交易資料丟進分析型倉儲、或拿交易資料庫硬跑報表,就是前面講的「全擠一台」會爆掉的根因。
我盤資料時實際在問的問題
維度表是 checklist,但實戰上我不會八欄逐一填完才動腦。拿到一筆資料,腦袋裡先跑這幾個快問快答,通常前兩問就能把它定位個七八成:
它是拿來交易還是拿來分析的?這一刀先砍下去,OLTP 跟 OLAP 兩邊的服務完全不同棟。接著問它需不需要跨 region 強一致——這題很關鍵,因為「需要」基本上就只剩 Spanner 一條路,而「不需要」卻硬上 Spanner,是在燒錢。再來看查詢是點查(拿單一 key 撈一筆)還是範圍掃描,這會直接影響 key 怎麼設計、服務怎麼挑。然後是熱資料多久變冷,決定你要不要做分層。最後一定要問有沒有合規限制,因為合規常常不是「加個功能」,而是直接框死你的選項——可能逼你用 regional storage、強制 CMEK(客戶自管金鑰)、把網路關進 VPC-SC(VPC Service Controls)。
這套問法沒有標準答案表可以背,但問順了你會發現,很多看起來很糾結的選型,問到第二題就分出勝負了。
走一遍範例 — 登雲書店
回到我們的老朋友。登雲書店上雲,到底有哪些資料要存?我把主要的幾類拉出來做特性分析。注意,下面這張表只到「結論」為止——還是不選服務,那是下一篇的事。先忍住手。
資料特性表
| 資料 | 結構 | 規模/成長 | 讀寫比 | 一致性 | 延遲要求 | 查詢模式 | 生命週期 | 敏感度 |
|---|---|---|---|---|---|---|---|---|
| 商品目錄 | 結構化 | 120 萬 SKU、年增 20% | 1000:1 | 最終一致可接受 | P95 < 50ms | 點查 + 關鍵字 + 分類 | 長期 | 低 |
| 商品全文索引 | 半結構化 | 同上 | 10000:1 | 最終一致 | P95 < 100ms | 全文、fuzzy | 可重建 | 低 |
| 庫存數量 | 結構化 | 120 萬列、少量更新 | 50:1 | 強一致(避免超賣) | P99 < 100ms | 點查 | 長期 | 中 |
| 購物車 | 半結構化 | 同時 5 萬台裝置 | 5:1 | 單裝置強一致即可 | P95 < 50ms | by userId | 30 天自動過期 | 中(PII) |
| 訂單 | 結構化 | 每年 600 萬筆、保留 7 年 | 2:1 | 強一致 + 跨區容錯 | P95 < 200ms | 點查 + 多條件 | 熱 90 天 / 溫 1 年 / 冷 7 年 | 高(PII) |
| 金流明細 | 結構化 | 每筆訂單 1–3 列 | 1:1 | 強一致 + 可稽核 | P95 < 300ms | 點查、範圍 | 永久、WORM | 高(PCI) |
| 閱讀進度 | 半結構化 | 每會員 × 每本書一筆 | 20:1 | 最後寫入優先 | P95 < 100ms | 點查(userId + bookId) | 熱到下次使用 | 中(PII) |
| 點擊與瀏覽紀錄 | 半結構化 | 每日 5 億筆、保留 18 個月 | 寫多(分析讀) | 最終一致 | 寫入 < 10ms、分析秒級 | 時間範圍、聚合 | 自動生命週期過渡 | 中(去識別) |
| 分析型事實表 | 結構化 | 每日 +100 GB、保留 3 年 | 讀多(D+1) | 最終一致 | 查詢秒級 | 大規模聚合 | 分割 + 壓縮 | 中 |
| 商品圖片 | 非結構化 | 單張 500KB、全量 5 TB | 極讀多 | 最終一致 | CDN 命中 < 50ms | by objectKey | 長期 + CDN | 低 |
| 批次匯入檔 | 非結構化 | 單檔最大 200MB | 一次性 | — | 分鐘級 | by jobId | 30 天保留稽核 | 中(商業敏感) |
表格填完,最有價值的不是表格本身,而是它逼出來的那幾個「啊,這幾類資料的脾氣差這麼多」的瞬間。挑幾條來講:
訂單跟金流明細是這份表裡最硬的兩塊——強一致、要跨區容錯、敏感度又高。它們的特性已經把答案推向 Spanner 或 Cloud SQL HA 這個方向了(到底哪一個,下一篇才攤開來比)。庫存乍看也是強一致,而且更新頻繁,需要 ACID,但別被「強一致」三個字嚇到就反射選 Spanner——它的資料量其實很小,未必值得那個價錢。這就是讀寫比和規模欄位幫你踩煞車的地方。
點擊紀錄是另一種極端:寫爆多、本質是時間序列、最後拿去做分析。這種資料的形狀,自然指向 Bigtable 接即時寫入、BigQuery 做後續分析的分層組合。商品目錄則是讀到不行、又能接受最終一致,往 Firestore 加 Memorystore 快取再罩個 CDN 走就很順。至於商品圖片,非結構化、讀極多——老實說這幾乎沒得選,Cloud Storage 配 Cloud CDN 就是標準解。
金流還有一條紅線單獨講:它是 PCI 資料。這意味著它不只是「挑哪個資料庫」的問題,而是整個落地方式都被合規綁住——得放進獨立 project、加密金鑰走 CMEK、網路關進 VPC-SC。這條等到後面講安全時會再深入,但在特性分析這一步就得先把旗子插上。
順手把生命週期也分好層
訂單保留 7 年、點擊紀錄保留 18 個月、圖片長期擺著——這些「放很久但越久越少碰」的資料,如果一路用最貴的熱儲存裝到底,帳單會很難看。所以特性分析的尾巴,順手把冷熱分層也想一遍:
| 階段 | 訂單 | 點擊紀錄 | 圖片 |
|---|---|---|---|
| 熱 | OLTP 主儲存 | 即時儲存 | Standard + CDN |
| 溫 | 同主儲存,降副本 | Nearline | Nearline |
| 冷 | 匯出 BigQuery + Nearline | Coldline | Coldline |
| 歸檔 | Archive Storage | Archive | Archive |
實務上這一層常被忘記,等到財務長盯著雲帳單問「為什麼三年前的圖片還在用最貴的儲存等級」,才回頭補生命週期政策。在設計階段順手定好,比事後清理省事太多。
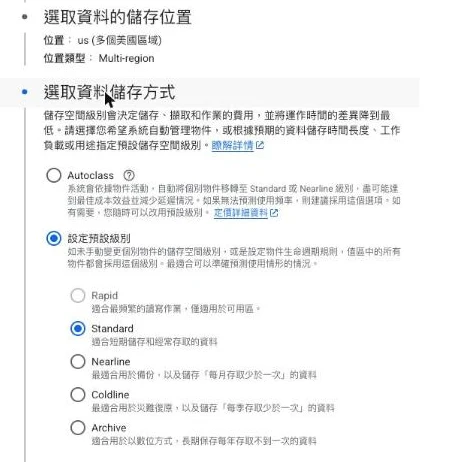
上面那張分層表在 Console 裡就是這塊「儲存級別」選單。這裡藏著一個常被反著踩的考點:上表教你別把冷資料留在貴的等級,但 Nearline/Coldline/Archive 各有 30/90/365 天的最短儲存時間 ——資料還沒住滿天數就搬走或刪掉,系統照樣按整段收你錢,太早搬反而更貴。所以生命週期政策不是越早往下沉越省,得先確定它在上一層真的待夠了。實在懶得算,最上面那個 Autoclass 讓 GCP 自動幫你搬,也是題目裡會出現的省事解。
走到這裡,你還是沒決定「訂單到底是 Spanner 還是 Cloud SQL」,但你已經很清楚:哪些資料得當祖宗供著、哪些丟給便宜的最終一致服務就好。這就是這一步的全部目的。
幾個容易翻車的地方
把所有資料塞同一個資料庫,前面講過了,這是最大的雷,本質是 monolith 病——一台機器同時扛 OLTP、OLAP、全文檢索,結果三樣都做不好。願意花力氣分清楚資料特性,多半就是為了不再踩這個坑。
第二個是低估資料量的複合成長。「每日 5 億筆」單看還好,乘上時間就嚇人:光是 18 個月的保留期,每日 5 億筆 × 365 天 × 1.5 年 就快 2700 億筆,這個量級 Cloud SQL 根本扛不住。新手常只看當下的單日數字就拍板,沒去算它累積一年多會變成什麼怪物。
第三個比較細,但很考經驗:索引與查詢成本。Firestore 預設幫你每個欄位都自動建索引,欄位一多,寫入成本會悄悄爬上去;Bigtable 則完全相反,它沒有 secondary index,所有查詢都得靠 row key 設計撐住——這兩種特性如果在選型時沒先想清楚,上線後要改的代價很高。
最後一個是合規。很多人講到合規腦袋裡只浮出「加密」兩個字,但 PCI DSS 要的遠不只如此——網路隔離、稽核紀錄、金鑰管理一樣都不能少。考試裡只要看到金流、信用卡,就別只想加密,把這一整串都拉進考量。
📝 考場提點
遇到合規題,先在腦中過一遍「資料駐留 → 加密金鑰 → 網路隔離 → 稽核」這條線,再去看選項。出題者很愛放一個「技術上最漂亮」但踩了某條合規的選項當誘餌——例如把金流資料丟進 BigQuery 做即時分析,效能滿分、合規零分。時間分配上,case study 的合規題通常牽一髮動全身,值得多花 30 秒確認,不要為了趕進度跳過。
延伸閱讀
- GCP 資料庫選型決策樹 — 官方決策輔助。
- Spanner vs Cloud SQL vs Firestore 比較 — 官方比較頁面。
- Bigtable schema design guidance — row key、列族設計指南。
- Google Cloud Architecture Framework — Data Strategy — 儲存選擇官方指南。
下一步:資料特性表到手,接下來就要動真格——把每一筆資料對應到具體的 GCP 產品,正式做選型。這部分交給系列第 8 篇 儲存與資料庫選型。
🎯 換你練習
理論讀完,換自己來。到 架構師設計工作坊 · 步驟 7 填入你的 case study,邊寫邊內化。
相關文章
您可能也會對這些文章感興趣

PCA 雲端架構師之旅 07 — 儲存特性分析
PCA 必考:如何用讀寫特性、一致性、資料量分析每筆資料的儲存需求。本文用登雲書店資料分類表示範選擇 GCP 儲存服務的思路。

PCA 雲端架構師之旅 01 — 讀懂案例情境
PCA 考試第一步就是讀懂 case study。本文帶你拆解業務目標、技術限制、利害關係人,避免沒看完題目就開始選 GCP 服務。

PCA 雲端架構師之旅 02 — 定義 User Personas
PCA 架構設計不是畫服務圖,而是從使用者開始。本文教你定義 User Persona,讓後續的 SLO、API、儲存選型都有依據。
