PCA 雲端架構師之旅 08 — GCP 儲存服務選擇

上一篇我們把資料的脾氣摸清楚了:要存多久、多大、讀寫比例、能忍多少延遲。這一篇就是收割的時候——把這些特性對應到實際的 GCP 服務名字。
聽起來像查表就好,對吧?偏偏這是整份 PCA case study 最會咬人的地方。GCP 一字排開七個儲存服務,每一個旁邊都站著一個「長得超像但其實不對」的替身。Cloud SQL 旁邊站著 Spanner,Firestore 旁邊站著 Bigtable,選錯一個,那整題就跟著陪葬。
這是 13 步驟 PCA 雲端架構師之旅 的第 8 站。前面把需求收乾淨了,現在輪到動真格的選型。
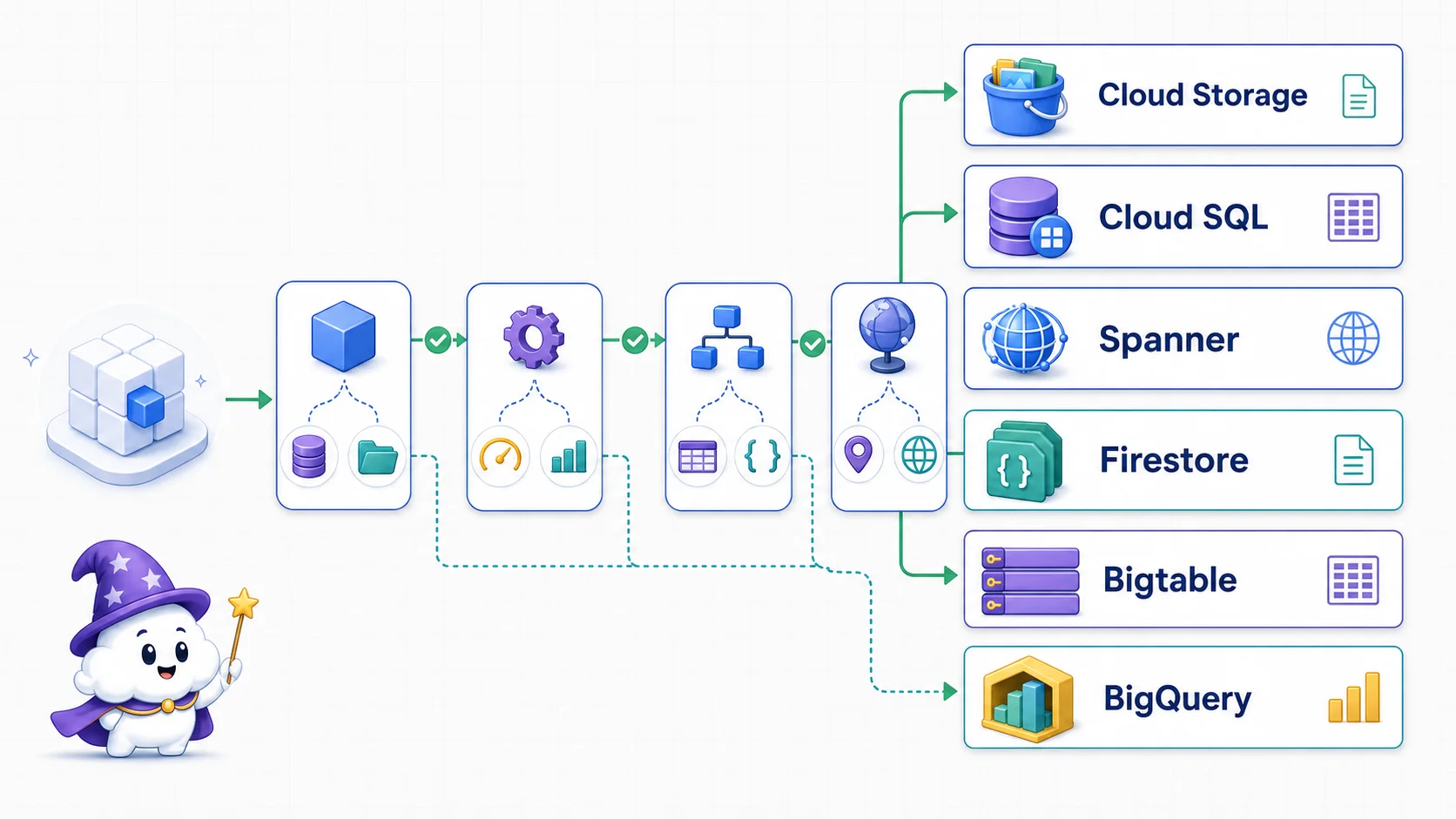
圖解:先問資料是不是檔案,再分交易與分析;交易資料接著看關聯模型、存取方式與是否需要全球強一致。檔案進 Cloud Storage、一般關聯交易先看 Cloud SQL、全球關聯交易看 Spanner、文件看 Firestore、大量低延遲 key-range 存取看 Bigtable、分析則進 BigQuery。
題目從來不會直接報服務名給你
考試最壞心的地方在於:它幾乎不會寫「請選用 Spanner」。它會丟一段業務描述,等你自己翻譯。像這樣:
- 「全球用戶、強一致、金流交易、每秒數千筆寫入」——這是在點名 Spanner。
- 「百 PB 時序資料、單鍵查詢 < 10ms」——這是 Bigtable 的主場。
- 「分析師要用 SQL 查半年內的訂單」——這在喊 BigQuery。
你的工作,就是把這些形容詞翻成服務名。而我看過太多人栽在三個地方:
第一種,把 Cloud SQL 當成萬用解。看到「資料庫」三個字眼睛一亮就選 Cloud SQL,完全沒看後面那句「全球」或「每秒上萬筆」。Cloud SQL 是好東西,但它有它的天花板。
第二種,Firestore 跟 Bigtable 分不清。兩個都掛著 NoSQL 的招牌,新手就以為可以互換。實際上這兩個的設計哲學差到不行——一個是給前端 App 即時同步用的,一個是給每秒灌幾萬筆時序資料用的,硬湊在一起就是災難。
第三種,忘記 BigQuery 不接前端交易。BigQuery 能做的事情太多了,多到讓人忘記它「不能」做什麼。它不是拿來接使用者每一次下單點擊的。
這三個雷之所以致命,是因為它們在現實裡也天天有人踩。我看過不少團隊一開始把什麼都塞進 Cloud SQL,連分析查詢都直接打上去,結果一跑大報表就把線上交易拖垮——OLTP 跟 OLAP 共用一個庫,遲早出事。考試只是把這種痛濃縮成一道選擇題而已。
📝 考場提點
拿到儲存題,先不要急著看選項,先在描述裡圈關鍵詞:圈出「全球 / global」「強一致 / strong consistency」「每秒 N 筆」「時序 / time-series」「分析 / analytics」「檔案 / 物件」這幾類字眼。這些字幾乎都是服務名的暗號。選項裡那個「技術上也行得通、但規模或成本不對」的選擇,通常就是專門設計來騙沒圈關鍵詞的人。
七個服務,一張表先記在腦子裡
選型前,這張對照表得先燒進記憶。考場上你沒時間現推,得能反射性地說出每個服務的定位、一致性模型跟規模天花板。
| 服務 | 類型 | 最適場景 | 一致性 | 規模上限 |
|---|---|---|---|---|
| Persistent Disk (PD) | Block | VM 掛載磁碟、資料庫底層 | 強 | 單盤 64 TB |
| Cloud Storage (GCS) | Object | 圖片、備份、資料湖、靜態網站 | 強(物件層級) | 無限 |
| Cloud SQL | 關聯式(區域) | 中小型 OLTP、單區域交易 | 強 | 單實例 64 TB |
| Spanner | 關聯式(全球) | 全球交易、金融、多區強一致 | 全球外部一致 | PB 級 |
| Firestore | 文件 NoSQL | 行動 App、即時同步、低寫入量 | 強(文件層級) | PB 級 |
| Bigtable | 寬列 NoSQL | 時序、IoT、廣告、推薦系統 | 單叢集強一致;跨叢集複寫為最終 | PB 級,高吞吐 |
| BigQuery | 資料倉儲 | 分析型查詢、報表、ML 訓練資料 | 強 | EB 級 |
表格背歸背,但真正幫你做決定的是底下這幾條分水嶺。每一條都是一刀,砍下去就排除掉一半選項:
交易型還是分析型? 也就是常聽到的 OLTP 對 OLAP。要接使用者一筆一筆的交易(下單、改個資、更新庫存),走 Cloud SQL、Spanner 或 Firestore;要做事後的聚合分析、跑報表、餵 ML 訓練,那是 BigQuery 的活。這條搞錯,後面全錯。
一個 region 夠不夠? 服務只在台灣一個 region 跑,Cloud SQL 綽綽有餘;要做到跨 region 還要強一致——同一筆訂單在台北寫、東京馬上讀得到正確值——那才輪到 Spanner 出場。Spanner 的全球外部一致(external consistency)是它最值錢的賣點,也是它最貴的原因。
有沒有 schema? 結構化、有欄位定義的資料走資料庫;圖片、影片、日誌、備份這種非結構化的檔案,丟 Cloud Storage。
要低延遲小量,還是高吞吐大量? Firestore 擅長前端那種「讀一筆寫一筆、但要快」的場景;Bigtable 擅長「每秒灌幾萬筆、之後要快速掃時序」的場景。同樣掛 NoSQL,這兩個其實活在不同的世界。
一個需求進來,我腦子裡跑的順序
實務上我拿到一個儲存需求,腦子裡會像過篩子一樣一層一層往下篩,幾秒鐘就能定位。你也可以照這個順序走:
先看它是檔案還是結構化資料。是圖片、影片、備份這類檔案,直接 Cloud Storage,收工。是有結構的資料,繼續往下。
接著問它是要拿來交易還是拿來分析。如果這份資料的用途是讀很多、做聚合、出報表,那它屬於 BigQuery,不要硬塞進交易型資料庫。
確定是交易型之後,問它需不需要跨 region 強一致。需要,Spanner;不需要,繼續篩。
再來分關聯式還是 NoSQL。需要 JOIN、有複雜關聯、要跑交易,關聯式,走 Cloud SQL。是 NoSQL,最後一刀——
寫入量是不是又大又偏時序 / IoT? 是,Bigtable;不是,Firestore。
這條主線之外,還有兩個常被忘記的旁支。一個是冷資料:要存超過一年但幾乎不讀的東西(合規歸檔、舊備份),別放在熱儲存燒錢,丟 Cloud Storage 的 Nearline / Coldline / Archive,依讀取頻率挑級別。另一個是掛載磁碟:純粹要給 VM 當本地磁碟用的,那是 Persistent Disk(或新一點的 Hyperdisk)的事,跟前面那條主線是兩回事。
📝 考場提點
這套篩選順序的價值在於「越早砍掉越省時間」。第一刀「檔案 vs 結構化」最該先問,因為它一刀就能把 Cloud Storage 的題目跟資料庫的題目分開。我看過考生在資料庫五個選項裡糾結老半天,回頭才發現題目講的根本是一堆使用者上傳的影片——那壓根不是資料庫題。先問大方向,再鑽細節,時間才夠用。
走一遍範例 — 登雲書店
老朋友登雲書店又上場了。它是電商平台,會員、訂單、商品、圖片、瀏覽紀錄、報表,全都要找地方存。我們把每一類資料丟進前面那台篩子,看它各自落在哪:
| 資料 | 選擇 | 為什麼 |
|---|---|---|
| 商品圖片、封面圖 | Cloud Storage Standard | 非結構化檔案、需 CDN 分發 |
| 舊版封面、檔案歸檔 | Cloud Storage Coldline | 30 天後幾乎不讀、成本最低 |
| 會員資料、訂單主檔 | Cloud SQL for PostgreSQL | 台灣單 region、讀寫比 7:3、關聯式 JOIN |
| 購物車、即時推播 token | Firestore | 低延遲、前端 SDK 直連、文件結構彈性 |
| 瀏覽紀錄、點擊串流 | Bigtable | 每秒數萬筆寫入、時序查詢 |
| 每日營收、用戶行為分析 | BigQuery | 分析師寫 SQL、跨月聚合 |
| Cloud SQL 底層磁碟 | Persistent Disk SSD | 由 Cloud SQL 自動管理 |
這張表裡有兩格,正是試題最愛拿來下套的位置。
第一個,會員跟訂單資料為什麼不丟 Firestore。Firestore 是 NoSQL,看起來「現代」,新手很容易被吸過去。但登雲書店的訂單要去 JOIN 商品表、用戶表、物流表——這種跨表關聯的查詢用關聯式做才直觀,Firestore 天生就不擅長跨文件 JOIN。題目要是把 Firestore 放進選項,就是在等你只看到「NoSQL 很潮」就跳坑。
第二個,瀏覽紀錄為什麼不直接寫進 BigQuery。每秒數萬筆的點擊串流如果直接走 BigQuery 串流 insert,會撞上 quota,延遲也撐不住接前端。正確的做法是分兩段:Bigtable 先扛住高吞吐寫入,再每天 batch 一份到 BigQuery 給分析師查。一收一算分開,這是時序資料的標準姿勢,現實專案也是這樣搭的。

還沒按執行,BigQuery 就先亮出綠色勾勾告訴你「這趟會掃 12.99 MB」——別小看這行小字,它是 PCA
成本題的命脈。BigQuery 計費看的是查詢掃過多少位元組,不是回傳幾列,所以
SELECT * 會把整張表每一欄都掃一遍,帳單自然貴。只挑真正要的欄位、再拿分區欄位當
WHERE 條件,這個數字就會肉眼可見地往下掉;考場一看到「降低 BigQuery
查詢成本」,腦子第一個該閃過的就是這一格。
那 Spanner 呢?這題裡它一格都沒佔到,原因很單純:登雲書店現在只在台灣一個 region。Spanner 的價值要等到跨國電商階段才浮現——哪天台日韓共用同一個帳號、同一張訂單表、而且每一筆都要全球強一致,那才是 Spanner 該登場的時候。在單一 region 的此刻,Cloud SQL 的成本效益遠遠勝過 Spanner,硬上 Spanner 反而是燒錢。這個取捨點,後面的成本章節還會再回來算一次帳。
幾個「看起來合理、其實扣分」的選擇
把上面的篩選跑熟之後,剩下的就是認得出那些常見的誤判。這幾個我特別提出來,因為它們不只是考點,現實裡也是真金白銀的學費。
為了顯得專業而上 Spanner。 這大概是最常見的過度設計。題目根本沒提跨 region、沒提全球強一致,有人偏要選 Spanner,覺得「比 Cloud SQL 高級」。問題是 Spanner 的成本比 Cloud SQL 高一大截,而 PCA 考題超愛拿成本當排除條件——題目裡只要出現「財務長要求控制成本」「預算有限」這類句子,那個過度設計的選項基本上就是設計來淘汰你的。需求沒講的東西,不要自己腦補上去。
拿 BigQuery 當即時交易後端。 BigQuery 的強項是 scan PB 級資料做聚合,它不是設計來接每秒上千筆 UPDATE 的。看到「即時訂單狀態更新」「即時庫存扣減」這種字眼,第一反應就該把 BigQuery 從選項裡劃掉。
以為 Persistent Disk 跟 Cloud Storage 可以互換。 這兩個根本不是同一種東西。PD 是掛在 VM 上、給作業系統當區塊磁碟用的;GCS 是透過 HTTP 存取的物件儲存,自帶生命週期管理、能直接接 CDN。把使用者上傳的圖片塞進 PD,等於白白丟掉 CDN 分發跟自動分層降溫這些能力,又貴又難擴展。我看過有人圖方便把上傳檔案全堆在 VM 的磁碟上,後來流量一大、跨機器要共享檔案時,整個架構動彈不得——這種坑現實裡比考試裡還痛。
延伸閱讀
下一步:資料各就各位之後,下一篇要處理怎麼把流量穩穩送進來——網路與 Load Balancing。
系列導航
🎯 換你練習
理論讀完,換自己來。到 架構師設計工作坊 · 步驟 8 填入你的 case study,邊寫邊內化。
相關文章
您可能也會對這些文章感興趣

PCA 雲端架構師之旅 08 — GCP 儲存服務選擇
把儲存需求對應到正確的 GCP 服務:Persistent Disk、Cloud Storage、Cloud SQL、Firestore、Bigtable、Spanner、BigQuery 的決策樹與取捨。PCA 考點實戰。

PCA 雲端架構師之旅 01 — 讀懂案例情境
PCA 考試第一步就是讀懂 case study。本文帶你拆解業務目標、技術限制、利害關係人,避免沒看完題目就開始選 GCP 服務。

PCA 雲端架構師之旅 02 — 定義 User Personas
PCA 架構設計不是畫服務圖,而是從使用者開始。本文教你定義 User Persona,讓後續的 SLO、API、儲存選型都有依據。
