GCP AI 與大數據:從 BigQuery 到生成式 AI 的完整工具鏈
ACE 考到 Data/AI 這塊,最容易卡在「這題到底該選 Dataflow 還是 Dataproc」「BigQuery 跟 Bigtable 又差在哪」。這幾個服務名字長得像、功能又有重疊,光看官方文件很難一次分清楚。但只要把它們的差別搞清楚,選型題其實是送分題。
這篇把 BigQuery、Dataflow/Dataproc、Pub/Sub、Vertex AI、Gemini API 怎麼選、怎麼兜成一套智能客服講清楚,最後用一個端到端的實戰案例把工具全部串起來。
BigQuery 資料倉儲:PB 級數據分析的基石
為什麼選擇 BigQuery?
BigQuery 是 GCP 的全代管資料倉儲服務,業界長期把它放在雲端資料倉儲的第一梯隊。最讓人有感的是這幾點——你完全不用管伺服器,丟一段 SQL 進去就跑;PB 級的資料照樣秒回;資料用串流寫進去,馬上就能查得到。下面分開講。
🆕 2025-2026 BigQuery 重大更新
提醒:本文撰於 2025-12。底下這些「重大更新」box 裡的價格、配額、生效日期最容易過時,GCP 也常調整。文中數字只當參考量級,真要用請點官方連結確認當期數字。
1. BigQuery Earth Engine 整合(正式推出,GA)
- 功能:直接在 BigQuery 中查詢 Earth Engine 地理空間數據集
- 數據規模:存取 PB 級的衛星影像、氣候數據、地形資料
- 用途:環境監測、氣候變遷分析、農業優化、城市規劃
- 範例:分析特定區域過去 20 年的森林覆蓋變化
2. Serverless Spark in BigQuery(正式推出,GA)
- 功能:在 BigQuery 中直接執行 Spark 作業,無需管理 Dataproc 叢集
- 優勢:自動擴展、不用管基礎設施、跟 BigQuery 數據接得很順
- 用途:複雜的 ETL 處理、機器學習特徵工程、大規模數據轉換
- 成本:按實際計算資源使用計費,相較於自管 Dataproc 叢集可降低營運與閒置成本(實際節省幅度依工作負載而定)
使用範例(以下為概念示意,BigQuery 跑 Spark 實際是用 stored procedures for Spark,請以官方文件為準):
-- BigQuery 用 stored procedure 跑 Spark(需先建好 Spark 連線)
CREATE PROCEDURE my_dataset.process_data()
WITH CONNECTION `my-project.us.my-spark-connection`
OPTIONS (engine = 'SPARK', runtime_version = '2.1')
LANGUAGE python AS r"""
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataProcessor").getOrCreate()
# 你的 Spark 邏輯
""";無伺服器架構(Serverless)的意思是,伺服器容量規劃、備份與災難恢復、版本升級與維護這些事你都不用碰——上傳數據、寫 SQL,BigQuery 會自動配運算資源跑分析。
規模上它能處理 Petabyte(PB,相當於一百萬個 GB)等級的資料,而且查 10 億筆記錄通常也是秒級完成。成本是按掃描量計費:on-demand 模式下,掃描 1 TiB 約 $6.25 美元,每個月前 1 TiB 還免費(GCP 計價單位是 TiB,比 TB 稍大;確切數字以官方定價頁為準)。
近即時分析這點也很實用:傳統資料庫得先建索引、預先載入數據才能查,BigQuery 則支援即時串流寫入,資料寫進去馬上就能查,不用等批次載入。
最後是 AI 輔助查詢優化——Gemini in BigQuery 現已納入定價模型,提供:
- 自然語言轉 SQL:直接用中文問「過去 30 天銷售額最高的前 10 個產品」,自動生成 SQL
- 查詢優化建議:AI 會分析你的 SQL 並提出效能改進建議
- 異常偵測:自動標記數據異常,如突然的流量激增或銷售下降
BigQuery SQL 查詢優化技巧
BigQuery 雖然快,但查詢寫得不好還是會多花錢(因為 on-demand 是按掃描量計費)。下面這幾招優化技巧最值得先學起來:

1. Partitioned Tables(分區表)
問題:查詢包含數十億筆歷史數據的表格時,即使只需要最近一週的數據,也會掃描整張表。
解決方案:根據時間或整數範圍分區。
-- 建立按日期分區的表格
CREATE TABLE `project.dataset.sales`
PARTITION BY DATE(order_date)
AS SELECT * FROM `project.dataset.raw_sales`;
-- 查詢時只掃描特定分區
SELECT SUM(amount)
FROM `project.dataset.sales`
WHERE DATE(order_date) BETWEEN '2026-01-01' AND '2026-01-07';效益:查詢只掃描 7 天的數據分區,成本降低 99%(假設總數據涵蓋 2 年)。
2. Clustering(聚類)
問題:即使使用分區,單一分區內的數據仍可能雜亂無章。
解決方案:根據常用查詢欄位自動排序。
-- 建立分區 + 聚類的表格
CREATE TABLE `project.dataset.sales`
PARTITION BY DATE(order_date)
CLUSTER BY customer_id, product_id
AS SELECT * FROM `project.dataset.raw_sales`;效益:查詢特定客戶或產品時,BigQuery 可跳過大量不相關的區塊,進一步減少掃描成本。
3. Materialized Views(物化視圖)
問題:某些複雜的聚合查詢(如每日銷售總額)會被重複執行。
解決方案:建立快取視圖,自動更新。
-- 建立物化視圖
CREATE MATERIALIZED VIEW `project.dataset.daily_sales`
AS
SELECT
DATE(order_date) AS sale_date,
SUM(amount) AS total_sales
FROM `project.dataset.sales`
GROUP BY sale_date;
-- 查詢物化視圖(極快)
SELECT * FROM `project.dataset.daily_sales`
WHERE sale_date = '2026-01-15';效益:物化視圖會自動增量更新(automatic refresh),查詢時直接讀預先算好的結果,速度可以快上一個量級(實際提升幅度依查詢與資料而定)。
跟其他雲的資料倉儲比起來
簡單講:BigQuery 是真正的 serverless、自動擴展、按掃描量計費,跟 Vertex AI / Gemini 原生整合;AWS Redshift 偏 cluster-based、要自己調節點;Azure Synapse 走 T-SQL。ACE 考試不會考跨雲比較,所以這裡知道「BigQuery = serverless 資料倉儲、用標準 SQL」就夠了,重點放在它跟 GCP 其他服務怎麼搭。
📝 考場提點
BigQuery 的考點幾乎都圍著「怎麼少掃資料、少花錢」打轉,記住這幾招就能秒選:
- 分區(Partition)+ 聚類(Cluster):按日期分區、按常用欄位聚類,查詢只掃需要的區塊,掃描量大降。題目出現「歷史資料很多、只查一段時間」就往這想。
- 避免
SELECT *:on-demand 按掃描的「欄位」計費,只 SELECT 用得到的欄位最省。- External Table(外部表 / 聯邦查詢):題目說「想用 SQL 直接查 Cloud Storage 上的 CSV/Parquet,不想先載入」→ 答案就是 BigQuery External Table。這是高頻陷阱,看到「不載入就查」幾乎都選它。
- 計費模式:on-demand 按掃描量、容量定價(capacity / slots)按運算量;考你「成本可預測、用量大」常導向容量定價。
實戰範例:分析網站流量數據
假設你有一個電商網站,每天產生數百萬筆點擊日誌。使用 BigQuery,你可以:
-- 1. 匯入 Google Analytics 4 數據(自動同步)
-- 2. 查詢過去 7 天流量最高的頁面
SELECT
page_location,
COUNT(*) AS page_views,
COUNT(DISTINCT user_pseudo_id) AS unique_users
FROM `project.analytics.events_*`
WHERE _TABLE_SUFFIX BETWEEN '20260115' AND '20260121'
AND event_name = 'page_view'
GROUP BY page_location
ORDER BY page_views DESC
LIMIT 10;執行時間:約 2-3 秒(即使掃描 1 億筆記錄)
Dataflow vs Dataproc:數據處理服務的選型策略
當數據量大到一台機器處理不來時,你就需要分散式數據處理框架。GCP 在這塊有兩個主力:Dataflow 和 Dataproc。問題是,該選哪一個?
🆕 2025-2026 Dataflow 重大更新
1. Dataflow Prime 成為託管範本的預設模式(2025 年 8 月 4 日起)
- 變更:從 2025 年 8 月 4 日起,**Google 託管的範本作業(Google-managed template jobs)**預設跑在 Dataflow Prime;如果你要用標準 Dataflow,得把
enable_prime服務選項設成false - 優勢:自動垂直與水平擴展、更好的資源利用率、降低閒置成本
- 適用對象:注意這是針對 Google 託管範本,不是「所有新作業」一律切換
2. ⚠️ Dataflow SQL 已棄用
- 狀態:官方時程是 2024 年 7 月 31 日起無法在 Console 使用、2025 年 1 月 31 日起無法在 Cloud CLI(gcloud)使用 Dataflow SQL
- 替代方案:官方主推 Apache Beam SQL;另外用 BigQuery + Serverless Spark 也是合理替代
- 遷移建議:現有 Dataflow SQL 用戶應盡快改用 Beam SQL 或改在 BigQuery 處理
Dataflow Prime 範例:
# 使用 Dataflow Prime(自動啟用)
gcloud dataflow flex-template run my-pipeline \
--template-file-gcs-location=gs://my-bucket/template.json \
--region=asia-east1 \
--enable-streaming-engine # Prime 自動優化核心差異一覽表
| 面向 | Dataflow | Dataproc |
|---|---|---|
| 架構 | Serverless(無伺服器) | Managed Clusters(代管叢集) |
| 程式模型 | Apache Beam(統一 batch + streaming) | Hadoop/Spark(主要 batch) |
| 管理複雜度 | 低(自動擴展) | 中(需管理叢集配置) |
| 啟動時間 | 快(秒級) | 慢(分鐘級,需啟動 VM) |
| 成本模式 | 按使用量計費 | 按叢集運行時間計費 |
| 適合場景 | 即時串流、無維護需求 | 批次處理、遷移 Hadoop/Spark 工作 |
Dataflow:Serverless 串流與批次處理
什麼是 Apache Beam?
Dataflow 用的是 Apache Beam 的統一程式模型,好處是同一套程式碼就能同時處理批次和串流數據。串流場景常聽到兩個詞:**windowing(時間視窗)**是「把連續不斷的資料切成一段一段來算」(例如每 60 秒算一次),**watermark(水位線)**則是「判斷某個時間區段的資料到齊了沒、可以結算了沒」——遲到的資料怎麼處理也靠它。這兩個是 Dataflow 在串流聚合上的招牌能力。
Beam 的核心概念:
Pipeline(管道)
├─ PCollection(數據集合)
├─ Transform(轉換操作)
└─ I/O Connector(輸入輸出)實戰範例:即時計算網站訪問量
假設你有一條即時的網站日誌串流(透過 Pub/Sub 傳送),想每分鐘算一次訪問量:
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
# 定義 Dataflow Pipeline
with beam.Pipeline(options=PipelineOptions()) as p:
(p
| 'Read from Pub/Sub' >> beam.io.ReadFromPubSub(
topic='projects/my-project/topics/website-logs')
| 'Parse JSON' >> beam.Map(lambda msg: json.loads(msg))
| 'Extract Page' >> beam.Map(lambda log: log['page_url'])
| 'Count per Minute' >> beam.WindowInto(
beam.window.FixedWindows(60)) # 60 秒視窗
| 'Count' >> beam.combiners.Count.PerElement()
| 'Write to BigQuery' >> beam.io.WriteToBigQuery(
table='my-project:analytics.page_views')
)執行方式:
python dataflow_pipeline.py \
--project=my-project \
--runner=DataflowRunner \
--region=asia-east1 \
--temp_location=gs://my-bucket/tempDataflow 會自動:
- 啟動 VM workers
- 根據數據量自動擴展(auto-scaling)
- 處理失敗重試
- 完成後自動關閉資源
成本:只在 pipeline 執行時計費,無閒置成本。
Dataproc:Hadoop/Spark 叢集的代管服務
什麼時候選 Dataproc
一句話:手上有舊的 Hadoop/Spark 工作要從地端搬上雲、團隊本來就熟 Spark/Hive/Presto、或者要跑 HBase、Flink 這類特殊工具(甚至要自己掌控叢集的機器類型和節點數),就選 Dataproc。
實戰範例:批次處理銷售數據
假設你每天都有銷售數據(CSV 檔放在 Cloud Storage),想算出每個產品的總銷售額:
# spark_job.py
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("SalesAnalysis").getOrCreate()
# 讀取 Cloud Storage 中的 CSV
df = spark.read.csv("gs://my-bucket/sales/*.csv", header=True)
# 計算每個產品的總銷售額
result = df.groupBy("product_id").sum("amount")
# 寫回 BigQuery
result.write \
.format("bigquery") \
.option("table", "my-project:analytics.product_sales") \
.save()建立 Dataproc 叢集:
gcloud dataproc clusters create my-cluster \
--region=asia-east1 \
--num-workers=5 \
--worker-machine-type=n1-standard-4提交作業:
gcloud dataproc jobs submit pyspark \
--cluster=my-cluster \
--region=asia-east1 \
gs://my-bucket/spark_job.py成本優化技巧:
- 用可中斷式 VM 當 workers 能省不少(Preemptible 與 GCP 現在主推的 Spot VM 是同一套定價模型,折扣浮動約 60%–91%,依機型與供需而定)。注意這類 VM 隨時可能被收回,適合可容忍中斷的批次作業
- 作業完成後立即刪除叢集(用
--max-idle參數自動化)
選型決策樹
需要即時串流處理?
├─ Yes → Dataflow
└─ No → 需要批次處理
團隊已熟悉 Hadoop/Spark?
├─ Yes → Dataproc
└─ No → 偏好無維護體驗?
├─ Yes → Dataflow
└─ No → Dataproc(但需學習成本)關鍵原則:
- 優先選 Dataflow:新專案、需要串流處理、或者懶得管叢集的話
- 選 Dataproc:手上有舊的 Hadoop/Spark 程式碼、或團隊本來就熟這些工具
📝 考場提點
Dataflow / Dataproc / Pub/Sub 是 ACE 最愛拿來互相干擾的三個選項,題目其實都靠關鍵字暗示答案:
- 看到「串流 + 即時聚合 / windowing(時間視窗)/ Apache Beam」→ Dataflow。Beam 同一套程式碼能跑批次也能跑串流,又有 windowing/watermark 處理時序,這是它的招牌。
- 看到「既有 Spark/Hadoop 要遷移、程式碼改最少」→ Dataproc。直接把 Spark job 搬上去就好;換成 Dataflow 反而要改寫成 Beam,是陷阱。
- 看到「解耦、發布訂閱、一對多、緩衝突發流量、非同步」→ Pub/Sub。它是訊息佇列,不負責運算,別跟前兩個搞混。
- 看到選項裡有「Pub/Sub Lite」可以直接排除——它已經 EOL(2026/3/18 關閉),出現在選項就是干擾項。
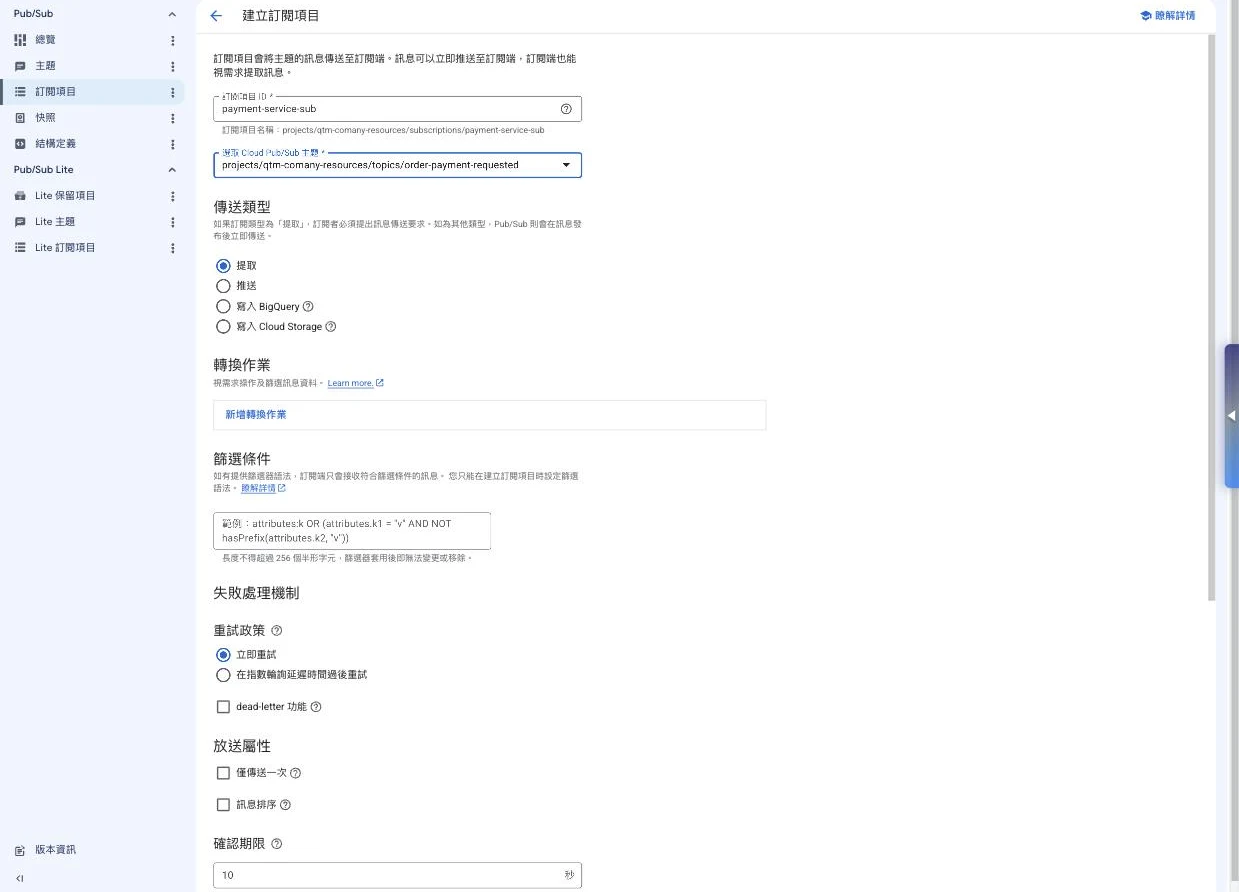
Pub/Sub 訊息佇列:建構事件驅動的即時架構
什麼是 Pub/Sub?
Cloud Pub/Sub 是 GCP 的全代管訊息佇列服務,基於發布-訂閱模式(Publish-Subscribe Pattern)。
⚠️ 2025-2026 Pub/Sub 重要通知
Pub/Sub Lite 已於 2026 年 3 月 18 日正式關閉
- 狀態:Pub/Sub Lite 已停止服務(2026/3/18 EOL)
- 原因:Cloud Pub/Sub 標準版已大幅降價,Lite 版的成本優勢已不明顯
- 替代方案:遷移至 Cloud Pub/Sub 標準版
- 考試提醒:ACE 考試中看到 Pub/Sub Lite 選項,直接排除
標準版 vs Lite 版對比(Lite 已關閉):
| 特性 | Pub/Sub 標準版 | |
|---|---|---|
| 可用性 SLA | 99.95% | 已停止服務 |
| 自動擴展 | ✅ 全自動 | 已停止服務 |
| 全球部署 | ✅ 支援 | 已停止服務 |
| 定價 | 按訊息量計費 | 已停止服務 |
| 推薦度 | ✅ 唯一選擇 | ❌ 已關閉 |
核心概念
Publisher(發布者)
↓
Topic(主題)
├─ Subscription A → Subscriber A
├─ Subscription B → Subscriber B
└─ Subscription C → Subscriber C特點:
- 解耦:發布者不需知道誰在訂閱
- 一對多:一個 Topic 可以有多個 Subscription
- 非同步:發布者發送訊息後立即返回,不等待處理完成
應用場景:事件驅動架構
場景 1:日誌聚合
假設你有 100 台伺服器,每台都會吐日誌。用 Pub/Sub 的話:
伺服器 1 → Pub/Sub Topic "logs"
伺服器 2 → Pub/Sub Topic "logs"
...
伺服器 100 → Pub/Sub Topic "logs"
Subscription "log-to-bigquery"
→ Dataflow → BigQuery(長期儲存)
Subscription "log-to-alerting"
→ Cloud Functions → 發送告警 Email好處:
- 伺服器只要丟到 Pub/Sub 就好,後續怎麼處理它不用管
- 想加新的訂閱者(例如多接一個監控工具)隨時都行,不會動到現有系統
場景 2:微服務解耦
假設你有個電商平台,訂單服務每次都得通知庫存服務、物流服務、發票服務:
傳統做法(緊耦合):
訂單服務 → HTTP 呼叫庫存服務
→ HTTP 呼叫物流服務
→ HTTP 呼叫發票服務問題:
- 物流服務一掛掉,整個訂單流程跟著卡住
- 想加新服務,就得回頭改訂單服務的程式碼
使用 Pub/Sub(解耦):
訂單服務 → Pub/Sub Topic "order-created"
Subscription "inventory" → 庫存服務
Subscription "shipping" → 物流服務
Subscription "invoicing" → 發票服務好處:
- 訂單服務只要發一次訊息就好
- 各服務各跑各的,互不干擾
- 想加新服務(例如會員積分)只要加個訂閱,訂單服務一行都不用動
實戰範例:即時網站活動追蹤
假設你想記下使用者在網站上的每一次點擊,而且要即時分析:
1. 前端發送事件到 Pub/Sub
// 前端 JavaScript
function trackClick(element) {
fetch('/api/track', {
method: 'POST',
body: JSON.stringify({
event: 'click',
element: element.id,
timestamp: Date.now(),
}),
});
}
// 後端 API (Cloud Run)
const { PubSub } = require('@google-cloud/pubsub');
const pubsub = new PubSub();
app.post('/api/track', async (req, res) => {
const topic = pubsub.topic('user-events');
await topic.publishMessage({
data: Buffer.from(JSON.stringify(req.body)),
});
res.status(200).send('Event tracked');
});2. Dataflow 即時處理並寫入 BigQuery
# 使用前面的 Dataflow 範例
(p
| 'Read from Pub/Sub' >> beam.io.ReadFromPubSub(
topic='projects/my-project/topics/user-events')
| 'Count clicks per page' >> ...
| 'Write to BigQuery' >> ...
)3. Looker Studio 即時儀表板
連接 BigQuery 表格,建立即時儀表板顯示:
- 每分鐘點擊量
- 最熱門頁面
- 使用者地理分布
延遲:從點擊到儀表板顯示,通常在 5-10 秒內。
跟其他 Message Queue 比
跟 RabbitMQ(強在複雜路由)、Kafka(強在高吞吐與事件溯源)、AWS SQS(AWS 原生)相比,Pub/Sub 的賣點是全代管、自動擴展、跟 GCP 生態系深度整合。ACE 不考跨雲訊息佇列比較,你只要記住:在 GCP 裡要做解耦、事件驅動、緩衝突發流量,又不想自己維運叢集,就是 Pub/Sub。它完全不用管基礎設施、自動擴展撐得住每秒數百萬訊息,還能跟 BigQuery、Dataflow、Cloud Functions 無縫串接。
Vertex AI 與 AutoML:機器學習的民主化
Vertex AI 的三塊:模型、訓練、Agent
Vertex AI 這個品牌正在被重塑。Google 在 Cloud Next 2026 把 Agent 平台對外重新包裝為 Gemini Enterprise Agent Platform,敘事改用 Build / Scale / Govern 這種「打造 → 規模化 → 治理」的生命週期分法(底下對應 ADK、Agent Engine 等元件),不再強調「三大核心功能」這種固定切分。品牌與框架名稱變動很快,請以官方 Agent 平台頁為準。
不過對 ACE 考生來說,底下這幾塊能力本身沒變,搞懂用途就夠:Model Garden(拿現成模型)、Model Builder(自己訓練,含 AutoML 與自訂訓練)、以及建 Agent 的工具。一塊一塊看。
1. Model Garden(模型花園)
功能:預訓練模型庫,包括:
🆕 2026 最新 Gemini 模型家族:
- Gemini 3.1 Pro:旗艦級多模態推理模型,支援約 100 萬(1M)tokens 上下文、輸出上限 64K tokens
- Gemini 3 Flash:速度與智慧最佳平衡,推薦大多數企業場景
- Gemini 2.5 Pro / Flash:上一代模型,仍廣泛使用,性價比高
- Gemini Computer Use:可控制電腦界面的 AI 代理(截圖→決策→操作)
- Imagen 4:圖像生成
- Veo:影片生成
- Chirp:語音識別
🆕 2026 熱門第三方模型:
- Llama 4:Meta 最新開源模型
- DeepSeek R1 / V3:開源推理模型
- Kimi K2:中文超長文本模型
- Mistral Large 2:企業級推理模型
- Anthropic Claude 4:強推理與程式碼能力
開源模型:Llama 系列、Mistral 系列、Stable Diffusion 專業模型:醫療影像分析、金融詐欺偵測
使用方式(以下為概念示意,呼叫 Gemini 實際請用 Google Gen AI SDK 的 generate_content,見後面 Gemini API 章節;實際 API 以官方文件為準):
from google import genai
client = genai.Client(vertexai=True, project='my-project', location='us-central1')
# 使用 Gemini 3.1 Pro 進行文本生成
response = client.models.generate_content(
model='gemini-3.1-pro',
contents='解釋量子運算的基本原理'
)
print(response.text)
# 多模態:直接餵音訊 + 指令(概念示意)
response_audio = client.models.generate_content(
model='gemini-3-flash',
contents=['總結這段對話的重點', audio_part] # audio_part 為音訊內容
)
print(response_audio.text)2. Model Builder(模型建構器)
包含兩種訓練方式:
A. AutoML(無程式碼訓練)
適合場景:
- 資料科學團隊資源有限
- 想快速驗證 ML 可行性(POC)
- 不需要複雜的模型自訂
支援的數據類型:
| 類型 | 任務 | 範例 |
|---|---|---|
| 圖像 | 分類、物體偵測、圖像分割 | 判斷照片中是否有受損車輛 |
| 文本 | 分類、情感分析、實體提取 | 客服訊息自動分類 |
| 表格 | 回歸、分類、預測 | 預測客戶流失率 |
| 影片 | 動作識別、物體追蹤 | 監控影片中的異常行為 |
實戰範例:訓練圖像分類模型
假設你手上有 10,000 張車輛照片,每張都標好了「正常」或「受損」:
- 上傳數據到 Cloud Storage:
gsutil -m cp -r ./car-images gs://my-bucket/car-dataset/-
建立 Dataset(在 Vertex AI Console):
- 選擇「Image」類型
- 匯入 CSV 標籤檔(格式:
gs://path/to/image.jpg,normal)
-
訓練 AutoML 模型:
- 選擇「AutoML Image Classification」
- 設定訓練預算(如 1 小時)
- 點擊「Train」
-
評估模型:
- Vertex AI 會自動算好混淆矩陣(confusion matrix,把「猜對/猜錯」攤成一張對照表)、精確率(Precision)、召回率(Recall)
- 白話講:Precision 是「模型說『受損』的,有多少真的受損」(抓得準不準);Recall 是「真正受損的,被模型抓出來多少」(抓得齊不齊)
- 範例結果:Precision 95%、Recall 92%
-
部署到端點(以下為概念示意,實際參數與物件請參官方 Vertex AI 文件):
endpoint = model.deploy(
machine_type="n1-standard-4",
min_replica_count=1,
max_replica_count=5
)
# 預測
prediction = endpoint.predict(instances=[{
"content": base64.b64encode(image_bytes).decode('utf-8')
}])
print(prediction.predictions[0]['label']) # 'normal' 或 'damaged'成本:AutoML 是按 **node-hour(節點小時)**計價,而且影像、表格、文字不同資料型別單價不一樣,部署後再按請求次數計費。實際金額以官方 Vertex AI 定價頁為準。
B. Custom Training(自訂訓練)
如果 AutoML 滿足不了你的需求(例如要特殊架構、自訂損失函數),就改用自訂訓練:
from google.cloud import aiplatform
# 準備 Docker 容器(包含訓練程式碼)
job = aiplatform.CustomTrainingJob(
display_name="fraud-detection",
container_uri="asia-east1-docker.pkg.dev/my-project/my-repo/fraud-model:v1"
)
# 執行訓練
job.run(
dataset=dataset,
model_display_name="fraud-model-v1",
machine_type="n1-standard-8",
accelerator_type="NVIDIA_TESLA_T4",
accelerator_count=2
)3. Agent Builder(代理建構器)
功能:建構對話式 AI 代理,整合搜尋與資料來源。
應用場景:
- 企業知識庫搜尋(如內部文件查詢)
- 客服聊天機器人
- 電商產品推薦對話
🆕 2025-2026 重大更新:Sessions 與 Memory Bank(正式推出)
根據 Vertex AI Agent Builder 發布公告,Sessions 和 Memory Bank 已經在 2026 年正式推出(GA):
Sessions(對話會話):
- 功能:追蹤多輪對話上下文,實現連貫對話
- 用途:記住使用者先前的問題和答案,提供更智能的回應
Memory Bank(記憶庫):
- 功能:長期儲存使用者偏好、對話歷史、個人化資訊
- 用途:跨會話記住使用者資訊,提供個人化服務
- 範例:記住使用者的購物偏好、語言選擇、過往問題
計費:Sessions 和 Memory Bank 都已進入收費(按會話/事件次數與儲存量計)。各家來源的計費起始日與單價口徑不太一致,這裡不寫死數字,請直接以官方定價頁為準。
實戰範例:建立具有記憶功能的客服機器人
from google.cloud import discoveryengine
# 建立數據儲存(匯入 FAQ 文件)
data_store = discoveryengine.DataStore.create(
project='my-project',
location='global',
data_store_id='customer-support-faq'
)
# 上傳文件(支援 PDF、HTML、TXT)
data_store.import_documents(
gcs_source='gs://my-bucket/faq-docs/*.pdf'
)
# 建立對話引擎
agent = discoveryengine.ConversationalSearchService.create_conversation(
data_store_name=data_store.name
)
# 使用者提問
response = agent.converse(
query="如何退換貨?"
)
print(response.reply.summary) # AI 自動從文件中擷取答案成本:按查詢次數計費,每 1,000 次查詢約 $3 美元。
AutoML vs 自訂訓練 vs 預訓練模型
| 方案 | 開發時間 | 精確度 | 成本 | 適合場景 |
|---|---|---|---|---|
| 預訓練模型(Model Garden) | 幾小時 | 中等 | 低 | 通用任務(如文本摘要、圖像標註) |
| AutoML | 1-2 天 | 高 | 中 | 特定領域(如車損偵測、客訴分類) |
| 自訂訓練 | 1-4 週 | 非常高 | 高 | 複雜任務(如醫療診斷、自動駕駛) |
建議流程:
- 先拿 Model Garden 的預訓練模型試試
- 精確度不夠的話,用 AutoML 快速訓一個
- 還是要再調的話,才投資源去做 自訂訓練
Gemini API 生成式 AI:企業級整合指南
Gemini Developer API vs Vertex AI Gemini API
Google 提供兩種 Gemini API 產品:
| 面向 | Gemini Developer API | Vertex AI Gemini API |
|---|---|---|
| 定位 | 個人開發、快速原型 | 企業級應用 |
| 免費額度 | ✅ 有免費層級(依模型而定的 RPM/RPD 限制,例如每日數百至上千次請求) | ❌ 無免費額度 |
| SLA 保證 | ❌ | ✅ 有 SLA(依 PayGo/Provisioned Throughput 而異) |
| 資料隱私 | 可能用於模型改進 | 保證不用於訓練 |
| GCP 整合 | 基本 | 深度整合(BigQuery、Vertex AI) |
| 認證方式 | API Key | Google Cloud Service Account |
| 適合場景 | 學習、實驗、小型專案 | 生產環境、企業應用 |
結論:
- 開發階段:用 Gemini Developer API(免費又快)
- 上線階段:換成 Vertex AI Gemini API(有企業級保障)
關於 SLA:Vertex 上的 Gemini SLA 比一個「99.9%」數字細——standard PayGo(隨用隨付)對到的是 99.5% 量級的 SLO,要拿到真正的 availability SLA 通常得走 Provisioned Throughput(預留吞吐量)。要寫進架構文件時,請以官方 SLA 頁為準。
統一 SDK:一套程式碼,兩種 Backend
2026 年推出的 Google Gen AI SDK,讓你能輕鬆切換 backend:
from google import genai
# 使用 Gemini Developer API
client = genai.Client(api_key='YOUR_API_KEY')
# 或使用 Vertex AI backend
client = genai.Client(
vertexai=True,
project='my-project',
location='us-central1'
)
# 程式碼完全相同
response = client.models.generate_content(
model='gemini-3.1-pro',
contents='解釋 Kubernetes 的核心概念'
)
print(response.text)支援語言:Python、JavaScript/TypeScript、Go、Java
實戰應用:建構智能文件摘要系統
假設你有一堆法律合約文件(PDF),想讓系統自動產摘要:
from google import genai
from google.cloud import storage
import base64
client = genai.Client(
vertexai=True,
project='my-project',
location='us-central1'
)
# 讀取 PDF(從 Cloud Storage)
storage_client = storage.Client()
bucket = storage_client.bucket('my-bucket')
blob = bucket.blob('contracts/contract-2026-01.pdf')
pdf_bytes = blob.download_as_bytes()
# 使用 Gemini 3.1 Pro(支援長文本 + 多模態)
response = client.models.generate_content(
model='gemini-3.1-pro',
contents=[
"請摘要以下合約的關鍵條款、雙方權利義務、以及注意事項:",
{
"mime_type": "application/pdf",
"data": base64.b64encode(pdf_bytes).decode('utf-8')
}
]
)
print(response.text)輸出範例:
【合約摘要】
- 甲方:ABC 公司,乙方:XYZ 供應商
- 合約期限:2026/01/01 ~ 2026/12/31
- 主要條款:
1. 乙方每月提供不少於 1,000 件產品
2. 甲方需於 30 天內付款
3. 違約金為合約總額的 10%
- 注意事項:
- 第 5 條規定不可轉包,需特別留意
- 第 12 條有獨家供應限制成本:Gemini 3.1 Pro 按 token 計費,input 和 output 單價不同,長上下文(超過某個 token 門檻)還會分級加價、batch 模式則較便宜。定價變動很快,實際數字請以官方定價頁為準。
企業級功能:Gemini for Google Cloud
Gemini for Google Cloud 是針對企業的生成式 AI 助理,整合到 GCP 各項服務:
1. Gemini Cloud Assist
協助開發者撰寫 Terraform、Kubernetes YAML:
你:「建立一個 GKE 叢集,3 個節點,使用 e2-standard-4 機器」
Gemini Cloud Assist:
```terraform
resource "google_container_cluster" "primary" {
name = "my-gke-cluster"
location = "us-central1"
initial_node_count = 3
node_config {
machine_type = "e2-standard-4"
}
}2. BigQuery 自然語言轉 SQL
你:「過去 7 天銷售額最高的前 10 個產品」
Gemini in BigQuery 自動生成:
SELECT
product_id,
SUM(amount) AS total_sales
FROM `project.dataset.sales`
WHERE DATE(order_date) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
GROUP BY product_id
ORDER BY total_sales DESC
LIMIT 10;3. Colab Enterprise 的 Gemini Code Assist
在 Jupyter notebooks 中:
- 自動補全程式碼
- 解釋複雜的數據分析
- 生成視覺化圖表程式碼
OpenAI 相容模式:無痛遷移
如果你本來就在用 OpenAI API,Gemini API 有提供相容層:
from openai import OpenAI
# 只需更改 base_url 和 api_key
client = OpenAI(
base_url="https://generativelanguage.googleapis.com/v1beta/openai/",
api_key="YOUR_GEMINI_API_KEY"
)
# 程式碼與 OpenAI 完全相同
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[
{"role": "user", "content": "寫一個 Python 快速排序"}
]
)
print(response.choices[0].message.content)好處:現有程式碼一行都不用改,把端點換掉就能試 Gemini。
實戰案例:建構智能客服系統的完整架構
接下來我們把前面這些工具全部兜起來,做一套端到端的智能客服系統。
系統需求
- 即時對話:使用者透過網頁或 LINE 提問
- 知識庫搜尋:從 FAQ、產品文件中找答案
- 智能回覆:使用生成式 AI 生成自然語言回覆
- 數據分析:分析常見問題、客戶滿意度
- 持續改進:根據數據優化模型
架構設計
[使用者] → [網頁/LINE Bot]
↓
[Cloud Run API]
├─ Pub/Sub Topic "customer-queries"
├─ Vertex AI Agent Builder(搜尋 FAQ)
└─ Gemini API(生成回覆)
↓
[Pub/Sub Subscription]
↓
[Dataflow]
↓
[BigQuery]
↓
[Looker Studio 儀表板]步驟 1:建立知識庫(Vertex AI Agent Builder)
from google.cloud import discoveryengine
# 建立數據儲存
data_store = discoveryengine.DataStore.create(
project='my-project',
location='global',
data_store_id='customer-faq'
)
# 匯入 FAQ 文件(支援 CSV、JSON、網站爬蟲)
data_store.import_documents(
gcs_source='gs://my-bucket/faq/*.json'
)
# 建立搜尋引擎
search_engine = discoveryengine.Engine.create(
project='my-project',
location='global',
engine_id='customer-support-search',
data_store_ids=['customer-faq']
)步驟 2:API 端點(Cloud Run)
from flask import Flask, request, jsonify
from google.cloud import discoveryengine, genai, pubsub
app = Flask(__name__)
genai_client = genai.Client(vertexai=True, project='my-project')
search_client = discoveryengine.SearchServiceClient()
pubsub_client = pubsub.PublisherClient()
@app.route('/chat', methods=['POST'])
def chat():
user_query = request.json['message']
# 1. 搜尋知識庫
search_response = search_client.search(
serving_config='projects/my-project/locations/global/engines/customer-support-search/servingConfigs/default_search',
query=user_query
)
# 2. 提取搜尋結果
context = "\n".join([
result.document.derived_struct_data['snippets'][0]['snippet']
for result in search_response.results[:3]
])
# 3. 使用 Gemini 生成回覆
response = genai_client.models.generate_content(
model='gemini-3-flash', # Flash 版本更快、更便宜
contents=f"""
你是一個客服助理。請根據以下知識庫內容回答使用者問題:
【知識庫】
{context}
【使用者問題】
{user_query}
請用友善、專業的語氣回答,並盡量簡潔。如果知識庫中沒有相關資訊,請誠實告知。
"""
)
# 4. 記錄到 Pub/Sub(供後續分析)
pubsub_client.publish(
topic='projects/my-project/topics/customer-queries',
data=json.dumps({
'query': user_query,
'response': response.text,
'timestamp': datetime.now().isoformat()
}).encode('utf-8')
)
return jsonify({'reply': response.text})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)步驟 3:部署到 Cloud Run
# 建立 Dockerfile
cat > Dockerfile <<EOF
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY app.py .
CMD ["python", "app.py"]
EOF
# 部署
gcloud run deploy customer-support-api \
--source . \
--region asia-east1 \
--allow-unauthenticated步驟 4:數據分析(Dataflow + BigQuery)
# dataflow_pipeline.py
import apache_beam as beam
with beam.Pipeline() as p:
(p
| 'Read from Pub/Sub' >> beam.io.ReadFromPubSub(
topic='projects/my-project/topics/customer-queries')
| 'Parse JSON' >> beam.Map(json.loads)
| 'Extract fields' >> beam.Map(lambda x: {
'timestamp': x['timestamp'],
'query': x['query'],
'response_length': len(x['response'])
})
| 'Write to BigQuery' >> beam.io.WriteToBigQuery(
table='my-project:analytics.customer_queries',
schema='timestamp:TIMESTAMP,query:STRING,response_length:INTEGER'
)
)步驟 5:建立即時儀表板(Looker Studio)
連接 BigQuery 表格 analytics.customer_queries,建立圖表:
- 每小時提問量(折線圖)
- 最常見問題(表格,依出現次數排序)
- 平均回覆長度(單一數值)
- 未解決問題(篩選出回覆包含「無相關資訊」的查詢)
成本估算(每月 10,000 次查詢)
| 服務 | 用量 | 成本 |
|---|---|---|
| Vertex AI Agent Builder | 10,000 次搜尋 | $30 |
| Gemini 3 Flash | 10,000 次生成 | $20 |
| Cloud Run | 10,000 次請求 | $2 |
| Pub/Sub | 10,000 次訊息 | $0.4 |
| Dataflow | 持續運行(Streaming) | $50 |
| BigQuery | 儲存 + 查詢 | $10 |
| 總計 | $112 |
備註:上表是粗估,只是讓你抓個量級概念——實際金額依用量假設與當期定價浮動很大,請以各服務官方定價頁為準。如果開發/測試期改用 Gemini Developer API(有免費額度),初期成本還能再壓低。
總結與下一步
考前你只要記住三件事
走過這一圈,這篇塞了很多服務,但真的會在考場救你的其實沒幾個。考前一晚把這三件事記牢就夠:
第一,選型題靠關鍵字。 串流 + 即時聚合 / windowing 選 Dataflow;既有 Spark/Hadoop 要遷移選 Dataproc;解耦、發布訂閱、緩衝突發流量選 Pub/Sub;看到 Pub/Sub Lite 直接排除(已 EOL)。
第二,BigQuery 的題目幾乎都在考「怎麼少掃資料」。 分區、聚類、避免 SELECT *、用 External Table 不載入就查 GCS——這幾招記熟,BigQuery 的題就是送分。
第三,Vertex AI 是「統一 ML 平台」。 不用記它最新叫什麼框架(品牌一直在變、現在往 Gemini Enterprise Agent Platform 走),記住它涵蓋從 Model Garden 拿現成模型、AutoML 快速訓練、到自訂訓練與建 Agent 一條龍就好。Gemini API 則是接生成式 AI 的入口,支援文字、圖像、影片多模態。
至於前面那個智能客服實戰案例,價值不在背它,而在讓你看懂這些服務怎麼一棒接一棒串成一條 pipeline——這正是 ACE 想驗的「會不會兜架構」。
學習路徑建議
1. 入門實作(1 週)
- 完成 BigQuery 的 Qwiklabs 實驗室
- 建立一個簡單的 Dataflow pipeline(批次處理 CSV 檔案)
- 使用 Gemini Developer API 建立一個簡單的聊天機器人
2. 進階實作(2-3 週)
- 使用 Vertex AI AutoML 訓練一個圖像分類模型
- 建構一個即時數據分析系統(Pub/Sub + Dataflow + BigQuery)
- 將 Gemini API 整合到現有應用(如客服系統、文件摘要)
3. 企業級專案(1-2 個月)
- 規劃完整的數據管道(ETL/ELT)
- 建立 ML Ops 流程(模型訓練、部署、監控)
- 導入 FinOps 文化,優化 GCP 成本
延伸學習資源
官方文件
實作教學
- Cloud Ace Blog:繁體中文 GCP 教學
- 東東 GCP 教學:深入的技術解析
- Google Codelabs:官方實作教學
社群資源
- GCP Taiwan User Group:台灣 GCP 社群
- Google Cloud Community:官方論壇
ACE 考試重點整理
必背知識點
- BigQuery 是無伺服器資料倉儲,支援 SQL,適合 PB 級分析
- Dataflow 是全託管 Apache Beam 管線,適合串流和批次處理
- Dataproc 是託管 Spark/Hadoop,適合既有 Spark 工作負載遷移
- Pub/Sub 是全託管訊息佇列,解耦生產者和消費者
- Vertex AI 是統一 ML 平台,整合 AutoML 和自訂訓練
- Gemini API 是 Google 最新生成式 AI 模型的存取方式
常見陷阱題
Q:需要對即時串流資料做聚合分析(如每分鐘平均溫度),選什麼? A:Dataflow(Apache Beam 支援 windowing 和 watermark)。BigQuery 串流插入可以接收資料,但即時聚合用 Dataflow。
Q:團隊有大量既有 Spark 作業要遷移到 GCP,選什麼? A:Dataproc。直接跑 Spark,程式碼幾乎不用改。Dataflow 需要改寫為 Beam。
Q:需要用 SQL 分析 Cloud Storage 中的 CSV 檔案,但不想載入,選什麼? A:BigQuery External Table(聯邦查詢)。直接在 BigQuery 用 SQL 查詢 GCS 上的檔案。
準備好往 GCP 的資安世界鑽進去了嗎?
下一課 ACE-205:企業級資安防護——GCP 安全架構與合規指南,會帶你搞懂零信任架構、KMS 和 VPC Service Controls。
相關文章
您可能也會對這些文章感興趣
GCP AI 與大數據:從 BigQuery 到生成式 AI 的完整工具鏈
完整掌握 GCP 大數據與 AI 工具鏈:從 BigQuery 資料倉儲、Dataflow/Dataproc 數據處理、Pub/Sub 訊息佇列,到 Vertex AI 機器學習與 Gemini API 生成式 AI。包含實戰案例:智能客服...
打造不當機的系統:GCP 高可用架構設計實戰
完整掌握 GCP 高可用架構設計:從 Managed Instance Group 自動擴縮容、負載平衡器選型、Cloud CDN 全球加速,到多區域容錯設計。包含 2026 最新功能如 Predictive Autoscaling、Ser...
GCP 資料儲存策略:Cloud Storage 與 Cloud SQL 選型指南
全面比較 GCP 儲存服務:Cloud Storage 儲存類別與生命週期、Cloud SQL vs AlloyDB vs Spanner 資料庫選型、Firestore vs Bigtable NoSQL 策略。包含成本效能分析、ACE...
