GCP 資料儲存策略:Cloud Storage 與 Cloud SQL 選型指南

資料儲存的三大挑戰:成本、效能、可靠性如何兼顧?
當你的應用越長越大,資料量從 GB 一路漲到 TB、甚至 PB,你大概會碰到這幾個頭痛問題:
- 成本失控:儲存費用每月暴增,卻有 80% 的資料根本沒人存取
- 效能瓶頸:資料庫查詢越來越慢,用戶抱怨頁面載入緩慢
- 資料遺失風險:單一區域故障導致服務中斷,甚至資料永久遺失
這幾個坑,多半是同一件事沒搞定——儲存服務一開始就挑錯了。
GCP 儲存服務一堆,這篇就用一張決策樹幫你分清楚 Cloud Storage、Cloud SQL 跟三個 NoSQL 各自該用在哪,順便算給你看每種選錯會多燒多少錢。
在進決策樹之前,先把兩組基本概念講清楚,後面看表才不會卡住:
- 結構化 vs 非結構化:結構化資料是長得整整齊齊、有欄位有列的東西(像訂單、會員資料),適合丟進資料庫用 SQL 查;非結構化資料是圖片、影片、PDF、備份檔這種沒有固定欄位的檔案,丟進物件儲存最省事。
- SQL vs NoSQL:SQL(關聯式)資料庫用表格+固定 schema,擅長跨表 JOIN 跟交易一致性;NoSQL 不綁固定 schema,換來的是更大的規模跟更彈性的資料模型(文件、寬欄位等),但通常得犧牲一些查詢能力或一致性。
把這兩條軸搞懂,下面的決策樹就只是在問你「資料長什麼樣、要多大、要多一致」。
GCP 儲存服務全景圖:選型決策樹
在細看各個服務之前,先把 GCP 儲存服務分成三大類來看:
1. 物件儲存(Object Storage)
代表服務:Cloud Storage
Cloud Storage 是物件儲存,拿來丟圖片、影片、備份這種非結構化檔案最合適,幾乎無限擴展又能接全球 CDN,成本壓得很低。靜態網站、媒體檔案、資料湖、備份與歸檔都是它的主場。
2. 區塊儲存(Block Storage)
代表服務:Persistent Disk、Local SSD
區塊儲存是掛在虛擬機器(VM)上的磁碟,延遲低、吞吐量高。資料庫的底層儲存、需要高 IOPS 的應用都靠它撐著——你開 VM 跑資料庫,底下吃的就是這層。
3. 資料庫服務(Database Services)
代表服務:Cloud SQL、Firestore、Bigtable、Spanner
資料庫服務存的是結構化資料,支援查詢與交易,還能自動備份。應用程式資料、使用者資料、分析資料這些需要查得快、又要保證一致性的場景都歸它管,差別只在於後面要挑哪一種(關聯式還是 NoSQL)。
選型決策樹
開始
├─ 需要儲存檔案(圖片、影片、備份)?
│ └─ YES → Cloud Storage
│
├─ 需要關聯式資料庫(SQL)?
│ ├─ 單一區域即可 → Cloud SQL
│ └─ 需要全球分散 → Cloud Spanner
│
├─ 需要 NoSQL 資料庫?
│ ├─ 文件型資料(行動應用)→ Firestore
│ ├─ 時間序列/大數據 → Bigtable
│ └─ 全球分散 + 強一致性 → Cloud Spanner
│
└─ 需要高效能磁碟(VM 用)?
└─ Persistent Disk 或 Local SSD快速選型指南:
| 需求 | 推薦服務 | 原因 |
|---|---|---|
| 儲存圖片、影片 | Cloud Storage | 成本低、全球 CDN |
| 備份與歸檔 | Cloud Storage (Archive) | 最低儲存成本 |
| MySQL/PostgreSQL | Cloud SQL | 全代管、自動備份 |
| 行動應用資料 | Firestore | 即時同步、離線支援 |
| IoT 時間序列 | Bigtable | PB 級擴展、低延遲 |
| 全球金融系統 | Cloud Spanner | 99.999% 可用性(多區域配置) |
Cloud Storage 深度解析:四種儲存類別的成本與效能權衡
Cloud Storage 是 GCP 的物件儲存服務,角色類似 AWS S3。比較不一樣的是 GCP 有四種儲存類別,讓你可以很精準地控制成本。
近期重要新功能
根據 Google Cloud 官方發布,Cloud Storage 近期加了幾個值得注意的功能:
階層式命名空間(Hierarchical Namespace,HNS)現已正式推出(GA)
HNS 給你一層類似檔案系統的目錄結構,可以直接對資料夾做重新命名與移動(不像傳統物件儲存得整批複製再刪)。官方在 AI/ML checkpoint 寫入的情境上量到最高 20 倍的提升,關鍵在於目錄操作變成原子的、只動 metadata,不用搬實際資料。數據湖、機器學習訓練資料集、大規模檔案管理都很受用。
gRPC 連線支援
相較於 REST API,gRPC 在高頻率存取、大量小檔案操作的場景下能降低延遲、拉高吞吐量,透過 Cloud Storage 的 gRPC API 客戶端使用。
生命週期 age: 0 行為變更
把物件的 age 條件設為 0 時,會在物件建立後的 UTC 午夜才滿足條件。如果你的生命週期規則用了 age: 0,要留意這個行為(詳見下方考場提點)。
BigQuery 跨區域存取 Cloud Storage 的計費變更
BigQuery 跨區域存取 Cloud Storage 會收取網路傳輸費用,把 BigQuery 與 Cloud Storage 放在同一區域就能避免這筆。實際生效日期請以官方 release notes 為準。
四種儲存類別比較
根據 Google Cloud 官方文件,四種儲存類別大致是這樣分工的(下表定價以 europe-west2/倫敦 區域為例,僅供示意;不同區域費率不同,且定價會隨時間調整,請以官方頁面為準):
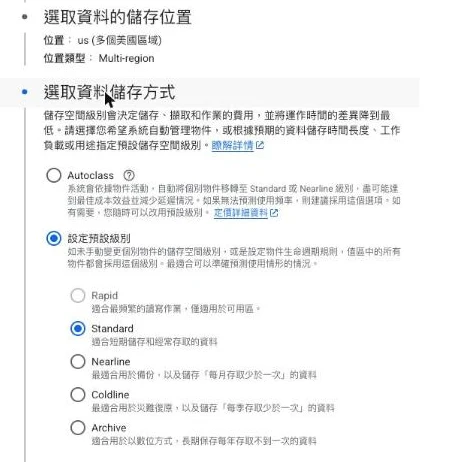
| 儲存類別 | 適用場景 | 存取頻率 | 最短儲存期限 | 定價(倫敦) | 檢索費用 |
|---|---|---|---|---|---|
| Standard | 熱資料 | 頻繁存取 | 無 | $0.023/GB-month | 無 |
| Nearline | 溫資料 | 每月 <1 次 | 30 天 | $0.013/GB-month | 有 |
| Coldline | 冷資料 | 每季 <1 次 | 90 天 | $0.007/GB-month | 有 |
| Archive | 歸檔資料 | 每年 <1 次 | 365 天 | $0.0025/GB-month | 有 |
關鍵洞察:
- 儲存成本差到 9 倍:Archive 只要 Standard 的 11% 成本
- 檢索費用要算進去:Nearline、Coldline、Archive 一旦存取就要額外付費
- 小心最短期限這個雷:提前刪除,還是得付滿整段期限的費用
📝 考場提點
ACE 很愛考 Cloud Storage 的省錢/生命週期題,兩個陷阱必背:
- 最短儲存期限(minimum storage duration):Nearline 30 天、Coldline 90 天、Archive 365 天。物件還沒住滿就刪掉(或被生命週期降級/覆寫),照樣要付滿整段期限的費用——所以「剛上傳就會頻繁改動」的資料千萬別丟冷類別。
- Lifecycle Policy 看的是存取頻率,不是直接看價格:題目給你「物件 30 天後很少存取、90 天後幾乎不碰」這種敘述,正解就是設生命週期規則,用
age條件+SetStorageClass動作自動降級(30 天 → Nearline、90 天 → Coldline、365 天 → Archive)。看到關鍵字 age 條件和 SetStorageClass 動作就對了。順帶一提,前面提到的
age: 0行為(建立後 UTC 午夜才滿足)也偶爾入題,記得「設 0 不等於立刻生效」。
Standard Storage:熱資料的最佳選擇
適用場景:
- 網站靜態資源(CSS、JS、圖片)
- 頻繁存取的使用者上傳檔案
- 機器學習訓練資料集
效能:
- 延遲:約 10 毫秒
- 吞吐量:無限制(自動擴展)
成本範例:
每月儲存 1 TB 資料
Standard: $23/monthNearline Storage:每月存取少於一次
適用場景:
- 資料備份(每月測試恢復一次)
- 長尾多媒體內容(舊影片、舊照片)
- 日誌歸檔(保留 30-90 天)
成本範例:
每月儲存 1 TB,每月存取一次
儲存成本: $13/month
檢索費用: $0.01/GB × 1,000 GB = $10
總成本: $23/month注意:如果存取頻率超過每月一次,Nearline 反而可能比 Standard 還貴!
Coldline Storage:每季存取少於一次
適用場景:
- 合規要求的歷史資料(需保留但很少存取)
- 災難復原備份(希望永不使用)
- 舊版本的軟體發行檔
成本範例:
每月儲存 10 TB,每季存取一次
儲存成本: $70/month
檢索費用: $0.02/GB × 10,000 GB = $200 (每季)
平均月成本: $70 + $66.7 = $136.7/monthArchive Storage:長期歸檔的王者
適用場景:
- 法規要求保留 7 年的資料
- 歷史交易記錄(很少查詢)
- 舊監控錄影(僅緊急時調閱)
成本範例:
每月儲存 100 TB,每年存取一次
儲存成本: $250/month
檢索費用: $0.05/GB × 100,000 GB = $5,000 (每年)
年總成本: $250 × 12 + $5,000 = $8,000對照一下:同樣這批資料如果改用 Standard,年成本會飆到 $27,600!
生命週期管理:自動化成本優化
根據 Elite Cloud 分析,用**物件生命週期策略(Object Lifecycle Policy)**就能讓儲存類別自動往下降級。
範例規則:
# 自動降級規則
- condition:
age: 30 # 超過 30 天
action:
type: SetStorageClass
storageClass: NEARLINE
- condition:
age: 90 # 超過 90 天
action:
type: SetStorageClass
storageClass: COLDLINE
- condition:
age: 365 # 超過 365 天
action:
type: SetStorageClass
storageClass: ARCHIVE實際效益:
假設你有 10 TB 的日誌資料:
- 最新 30 天(Standard):300 GB × $0.023 = $6.9
- 30-90 天(Nearline):1.8 TB × $0.013 = $23.4
- 90-365 天(Coldline):8.3 TB × $0.007 = $58.1
- 超過 365 天(Archive):移至 Archive
總成本:$88.4/month(若全用 Standard 需 $230/month)
Autoclass:自動化儲存類別優化
GCP 的 Autoclass 功能(2022 年推出,現已支援既有 bucket;來源:Cast AI)會追蹤存取模式,自動幫你調整儲存類別,本質是規則式自動化,不是 AI/ML 模型:
- 不用自己手動設:系統會自動追蹤存取頻率
- 即時調整:30 天沒存取就自動降到 Nearline
- 成本看得見:Cloud Console 會顯示每個 bucket 的優化建議
Cloud SQL 高可用架構:2025 年架構大升級
Cloud SQL 是 GCP 的全代管關聯式資料庫服務,支援 MySQL、PostgreSQL、SQL Server。
先把兩個高可用常用詞講白話:RPO(Recovery Point Objective) 是「你能容忍遺失多少資料」,RTO(Recovery Time Objective) 是「你能容忍多久才救回來」。RPO=0 代表故障切換後一筆都不會掉;RTO 越小代表服務中斷越短。下面的新舊架構比較會一直用到這兩個詞。
2025 年重大架構變更
根據 Cloud SQL 官方文件,Google 在 2025 年把高可用架構大改了一輪:
關鍵時程:
- 2025 年 1 月 13 日:舊版高可用配置(legacy HA)正式棄用
- 2025 年 5 月 1 日起:自動升級至新版區域持久性磁碟架構
新舊架構差異:
| 特性 | 舊版 HA | 新版 HA (2025) |
|---|---|---|
| 架構基礎 | 主從複製 | 區域持久性磁碟 |
| 容錯移轉 | 手動 + 自動 | 全自動 |
| RPO(資料遺失) | 秒級 | 0(零資料遺失) |
| RTO(恢復時間) | 30-60 秒 | 約 60 秒(依環境而異) |
| 成本 | 雙倍執行個體 | 單一執行個體 + HA 費用 |
高可用架構運作原理
架構圖:
[Primary Instance] [Standby Replica]
│ │
├─ Regional Persistent Disk ──────┤
│ (同區域跨可用區同步複製) │
│ │
└─ Health Check ──────────────────┘
(心跳每秒偵測 primary)
故障時:
[Primary 故障] → [心跳偵測不到] → [自動容錯移轉] → [Standby 升級]
↓ ↓ ↓ ↓
0 秒 連續偵測不到 切換中(約 60 秒) 新 Primary容錯移轉流程:
- 健康檢查失敗:心跳系統每秒偵測 primary 是否健康,連續多次偵測不到就觸發容錯移轉
- VIP 切換:VIP(Virtual IP,虛擬 IP,一個不綁死在單一機器上的浮動 IP)自動指向待命副本,應用程式連的位址不用改
- 應用程式重連:客戶端斷線後重連,整段 failover 後預期約 60 秒無法使用,實際時間依環境而異
- 無資料遺失:區域持久性磁碟同步複製,RPO = 0
主從複製:讀取分流
除了 HA,Cloud SQL 還可以開讀取副本(Read Replicas):
用途:
- 分散讀取流量(寫入仍在主執行個體)
- 跨區域災難復原
- 資料分析查詢(避免影響主資料庫)
範例架構:
[Primary (asia-east1)]
│
├─ Read Replica 1 (asia-east1) ── 本地讀取
├─ Read Replica 2 (us-central1) ── 跨區備援
└─ Read Replica 3 (europe-west1) ── 全球分散成本考量:
- 主執行個體:db-n1-standard-2 ($100/month)
- 每個讀取副本:$100/month + 跨區網路費用
- 總成本:$100 + $100 × 3 = $400/month
備份與恢復策略
Cloud SQL 的備份有兩種做法:
1. 自動備份(Automated Backups)
- 頻率:每日一次(可自訂時間)
- 保留期限:7-365 天(可調整)
- 恢復方式:還原至新執行個體或覆蓋現有執行個體
範例設定:
gcloud sql instances patch my-instance \
--backup-start-time=02:00 \
--backup-location=asia \
--retained-backups-count=302. 隨需備份(On-Demand Backups)
- 用途:重大變更前手動備份
- 保留期限:永久保留(直到手動刪除)
- 成本:依儲存量計費
最佳實踐:
✅ 3-2-1 備份原則:
- 3 份備份副本
- 2 種不同儲存媒體(自動備份 + 匯出至 Cloud Storage)
- 1 份異地備份(跨區域)
✅ 定期測試恢復:
- 每月執行一次恢復演練
- 驗證 RTO(恢復時間目標)與 RPO(資料遺失容忍度)
效能優化技巧
1. 選擇正確的機器類型
| 機器類型 | vCPU | RAM | 適用場景 |
|---|---|---|---|
| db-f1-micro | 1 | 0.6 GB | 開發測試 |
| db-n1-standard-1 | 1 | 3.75 GB | 小型應用 |
| db-n1-standard-4 | 4 | 15 GB | 中型應用 |
| db-n1-highmem-8 | 8 | 52 GB | 記憶體密集 |
2. 啟用 Query Insights
這是 Cloud SQL 內建的查詢分析工具,幫你找出慢查詢:
-- 查看最慢的 10 個查詢
SELECT query, total_time, calls
FROM pg_stat_statements
ORDER BY total_time DESC
LIMIT 10;3. 連線池優化
使用 Cloud SQL Proxy 或 Private IP 減少連線建立時間:
# 使用 Cloud SQL Proxy(推薦)
./cloud-sql-proxy --instances=my-project:asia-east1:my-instance=tcp:33064. Managed Connection Pooling
根據 Cloud SQL 官方文件,Managed Connection Pooling(MCP) 讓 Cloud SQL 幫你代管連線池(確切 GA 時間與計費請以官方頁面為準):
核心優勢:
- 連線池自動管:Cloud SQL 幫你管連線池,應用程式端不用另外設定
- 少掉連線開銷:重複用現有連線,省下一直建立、關閉連線的成本
- 效能更好:很適合高並發、短連線的場景(例如 Serverless 函數)
- 資源吃得少:資料庫連線數變少,記憶體用量也跟著降
適用場景:
- Cloud Run / Cloud Functions 等 Serverless 應用
- 高並發 Web 應用(每秒數百次連線)
- 短生命週期連線(連線時間 <1 分鐘)
啟用方式:
gcloud beta sql instances patch INSTANCE_NAME \
--enable-connection-pooling成本效益:
- 計費方式請以官方定價頁為準(部分情境含在 Cloud SQL 定價內,實際以官方文件確認)
- 資料庫連線數可以少掉 30-50%
- 可以拿來取代第三方連線池方案(像 PgBouncer)
NoSQL 資料庫選型:Firestore、Bigtable、Spanner 完全比較
根據 Google Cloud Blog,GCP 有三大 NoSQL 服務,各自守在不同的位置。
Firestore:行動應用的最佳拍檔
定位:無伺服器文件資料庫
資料模型:
{
"users": {
"user123": {
"name": "Alice",
"email": "alice@example.com",
"profile": {
"avatar": "https://...",
"bio": "Software Engineer"
}
}
}
}核心特性:
- 即時同步:資料一變更,馬上推送到所有客戶端
- 離線支援:沒網路時照樣能讀寫,連上線後自動同步
- 自動擴展:從 0 撐到數 TB,不用自己手動調
Firestore Enterprise Edition 與 MongoDB 相容性(已正式推出,GA)
根據 Google Cloud 官方公告,Firestore with MongoDB compatibility 已於 2025 年 8 月正式推出(GA),屬於 Firestore Enterprise edition:
MongoDB 相容性:
- 支援 MongoDB Wire Protocol,可以直接用 MongoDB 驅動程式
- 從 MongoDB 搬到 Firestore 比較省事
- 同時保留 Firestore 自動擴展、全代管的好處
適用場景:
- 現有 MongoDB 應用遷移至 GCP
- 需要 MongoDB API 但希望使用全代管服務
- 混合使用 Firestore 原生 API 與 MongoDB API
注意事項:
- 雖已 GA,部分 MongoDB 功能的支援程度仍可能與原生 MongoDB 有差異
- 上線前建議先在測試環境驗證相容性
適用場景:
- 行動應用(iOS、Android)
- 即時聊天應用
- 協作工具(Google Docs 風格)
- 使用者個人資料與設定
定價(下列數字僅供示意,定價會隨時間與區域調整,請以官方 Firestore 定價頁 為準):
- 儲存:$0.18/GB-month
- 讀取:$0.06 per 100k 文件
- 寫入:$0.18 per 100k 文件
範例成本:
10,000 活躍用戶 App:
- 儲存 10 GB 資料 → $1.8/month
- 每天 1M 讀取 → $18/month
- 每天 100k 寫入 → $5.4/month
總成本:$25.2/monthBigtable:時間序列與大數據的扛霸子
定位:寬欄位 NoSQL,PB 級擴展
補充:寬欄位(wide-column) 是一種資料模型,每一列用一個 row key 當索引,下面可以掛非常多欄(甚至每列欄位數不一樣),很適合「同一個 key 一直追加時間點」的資料。
資料模型:
Row Key: sensor123#2026-12-26T12:00:00
Column Family: metrics
temperature: 25.3
humidity: 60.2
pressure: 1013.25核心特性:
- PB 級擴展:從 1 TB 一路撐到數百 PB
- 低延遲:毫秒級讀寫,就算到了 PB 規模也一樣
- 高吞吐:每秒可以做到百萬次操作
適用場景:
- IoT 時間序列資料(感測器、監控)
- 金融交易歷史(tick 資料,也就是每一筆成交/報價的逐筆紀錄,量大又要按時間查)
- 廣告技術(點擊流分析)
- 機器學習特徵儲存
定價:
- 節點成本:$0.65/hour per node
- 儲存成本:$0.17/GB-month (SSD) 或 $0.026/GB-month (HDD)
範例成本:
3 節點 Bigtable 叢集 + 10 TB SSD:
- 節點:$0.65 × 3 × 730 hours = $1,424/month
- 儲存:$0.17 × 10,000 GB = $1,700/month
總成本:$3,124/month重要限制:
- ❌ 不支援多行事務(只能單行事務)
- ❌ 小數據集別用它(建議 >1 TB,不然成本不划算)
Spanner:全球分散式 SQL 的終極武器
定位:全球分散式關聯式資料庫
核心特性:
- 99.999% 可用性(全球多區域)
- 強一致性:就算跨大洲也保證 ACID
- 無限擴展:可以水平擴展到數 PB
- AI 整合:原生 Vertex AI 支援
- 向量搜尋:語意搜尋(2024 年起的 Spanner editions 功能)
- 全文搜尋:內建全文索引(2024 年起的 Spanner editions 功能)
適用場景:
- 全球金融系統(多國交易)
- 線上遊戲(全球玩家同步)
- 供應鏈管理(跨國庫存)
- 零售電商(全球訂單)
定價:
- 節點成本:$0.90/hour per node(區域)或 $3.00/hour(多區域)
- 儲存成本:$0.30/GB-month(區域)或 $0.50/GB-month(多區域)
範例成本:
3 節點多區域 Spanner + 1 TB 資料:
- 節點:$3.00 × 3 × 730 = $6,570/month
- 儲存:$0.50 × 1,000 GB = $500/month
總成本:$7,070/month成本警告:Spanner 是 GCP 最貴的資料庫服務,真的有全球分散需求再用它!
三大 NoSQL 選型決策
前面那張全景決策樹是幫你在所有儲存服務裡做第一刀切分;這裡換個聚焦角度,只比 Firestore、Bigtable、Spanner 這三個怎麼選——當你已經確定要走 NoSQL,再用這張表決定挑哪個。
| 需求 | Firestore | Bigtable | Spanner |
|---|---|---|---|
| 資料規模 | <10 TB | >1 TB | 無限制 |
| 資料模型 | 文件(JSON) | 寬欄位 | 關聯式(SQL) |
| 事務支援 | ✅ ACID | ❌ 僅單行 | ✅ ACID |
| 全球分散 | ❌ | ❌ | ✅ |
| 即時同步 | ✅ | ❌ | ❌ |
| 離線支援 | ✅ | ❌ | ❌ |
| 成本 | 💰 低 | 💰💰 中 | 💰💰💰 高 |
| 適合場景 | 行動 App | IoT/時間序列 | 全球金融 |
快速判斷:
需要即時同步 + 離線支援?
└─ YES → Firestore
資料量 >1 TB + 時間序列?
└─ YES → Bigtable
需要全球分散 + 強一致性 + SQL?
└─ YES → Spanner
都不符合?
└─ 考慮 Cloud SQL(關聯式)或 Firestore(文件)📝 考場提點
選型題是 ACE 的送分題,但前提是你記得住關鍵字對應。看到題目裡這些字,直接對號入座:
題目關鍵字 正解 PB 級 + 個位數毫秒延遲、IoT/時序 Bigtable 全球分散 + 強一致性 + SQL/OLTP Spanner 行動 App + 即時同步/離線 Firestore MySQL/PostgreSQL 最小改動搬遷 Cloud SQL 分析型、PB 級 SQL 查詢 BigQuery 干擾選項是出題者最愛埋的坑,這幾個一定要排除:
- Firestore 撐不了 PB 級——看到 PB+低延遲就不要選它,那是 Bigtable 的地盤。
- BigQuery 延遲是秒級,是資料倉儲不是線上資料庫,任何「個位數毫秒」「線上低延遲」的題目都不選它。
- Cloud SQL 不做全球規模——要「全球分散+強一致性」就得換 Spanner,Cloud SQL 只到單一區域(加跨區讀取副本)。
成本優化實戰:10 個省錢技巧
參考 Lucidity 最佳實踐 與 Elite Cloud 費用解析,這裡整理幾招實際好用的 GCP 儲存省錢技巧。
1. 生命週期管理自動化
Before:
10 TB 日誌全用 Standard Storage
成本:$230/monthAfter(啟用生命週期規則):
- 最新 30 天(Standard):300 GB × $0.023 = $6.9
- 30-90 天(Nearline):1.8 TB × $0.013 = $23.4
- 90-365 天(Coldline):8.3 TB × $0.007 = $58.1
成本:$88.4/month(省 61%)2. 區域選擇策略
不同 GCP 區域的儲存成本可以差到 30%:
| 區域 | Standard 成本 | Coldline 成本 |
|---|---|---|
| us-central1(愛荷華) | $0.020/GB | $0.004/GB |
| us-east1(南卡) | $0.020/GB | $0.004/GB |
| asia-east1(台灣) | $0.023/GB | $0.007/GB |
| europe-west1(比利時) | $0.020/GB | $0.004/GB |
建議:法規允許的話,挑 us-central1 或 europe-west1。
3. Cloud SQL 機器類型優化
過度配置範例:
應用程式只需 2 GB RAM
卻使用 db-n1-standard-4(15 GB RAM)
成本:$180/month
優化後使用 db-n1-standard-1(3.75 GB RAM)
成本:$50/month(省 72%)4. Cloud SQL 讀取副本按需啟用
常見誤區:永久運行 3 個讀取副本
優化方案:
- 正常流量:僅主執行個體
- 高峰流量:自動啟動讀取副本(使用 Cloud Functions 觸發)
成本對比:
永久 3 副本:$400/month
按需啟動(每月運行 100 小時):$100 + $13.7 = $113.7/month
省 71%5. 壓縮資料再上傳
Before:
1 TB 未壓縮日誌
儲存成本:$23/month(Standard)After(gzip 壓縮,壓縮率 80%):
200 GB 壓縮日誌
儲存成本:$4.6/month(省 80%)實作:
# 壓縮後上傳
gzip logs/*.log
gsutil -m cp logs/*.log.gz gs://my-bucket/logs/6. 刪除未使用的快照
Cloud SQL 的自動備份會一直吃儲存空間:
範例:
100 個快照,每個 10 GB
儲存成本:1 TB × $0.11 = $110/month
優化:僅保留最近 7 個快照
儲存成本:70 GB × $0.11 = $7.7/month(省 93%)7. 使用 Committed Use Discounts(承諾使用折扣)
Cloud SQL 可以承諾用 1 年或 3 年,最多能省到 52%:
| 承諾期限 | 折扣 |
|---|---|
| 1 年 | 25% |
| 3 年 | 52% |
範例:
db-n1-standard-4 隨需定價:$180/month
1 年承諾:$135/month(省 25%)
3 年承諾:$86.4/month(省 52%)8. Firestore 查詢優化
避免掃描整個集合:
Before(掃描 10,000 文件):
// ❌ 壞做法
db.collection('users').get()
成本:$0.06 per 100k × 0.1 = $0.006 per 查詢After(使用索引,僅讀 10 文件):
// ✅ 好做法
db.collection('users').where('status', '==', 'active').limit(10).get()
成本:$0.06 per 100k × 0.00001 = $0.0000006 per 查詢9. Bigtable HDD 替代 SSD
如果對延遲沒那麼要求(例如批次分析),改用 HDD 可以省下 84% 的儲存成本:
| 儲存類型 | 成本 | 延遲 |
|---|---|---|
| SSD | $0.17/GB-month | <10ms |
| HDD | $0.026/GB-month | <100ms |
範例:
10 TB 歷史資料
SSD:$1,700/month
HDD:$260/month(省 85%)10. 監控與告警
設個預算告警,免得成本不知不覺就爆掉:
# 設定每月 $500 預算告警
gcloud billing budgets create \
--billing-account=0X0X0X-0X0X0X-0X0X0X \
--display-name="Storage Budget" \
--budget-amount=500 \
--threshold-rule=percent=50 \
--threshold-rule=percent=90 \
--threshold-rule=percent=100實際案例:
有家公司原本每月 GCP 儲存成本 $12,000,做完下面這幾件事後降到 $3,800(省了 68%):
- 啟用生命週期管理(省 $4,000)
- 刪除未使用快照(省 $1,800)
- Cloud SQL 降規格(省 $1,200)
- Bigtable 改用 HDD(省 $1,200)
總結與下一步
真正會考、也最容易踩雷的就那幾點——選型對應、最短儲存期限、HA 的 RPO/RTO,先把這些記牢,剩下的成本技巧是上考場前的加分題。
關鍵要點回顧
- 選型原則:依資料結構(結構化/非結構化)、規模、一致性需求挑服務,這也是選型題的判斷主軸。
- Cloud Storage:善用生命週期管理可省 60% 以上成本,但別忘了最短儲存期限這個雷。
- Cloud SQL:2025 年的新區域持久性磁碟架構提供 RPO=0 的容錯移轉,failover 後約 60 秒可恢復。
- NoSQL 選型:Firestore(行動 App)、Bigtable(時間序列/PB 級)、Spanner(全球分散+強一致性)。
- 成本優化:壓縮、區域選擇、承諾使用折扣都能顯著降本。
實戰檢查清單
實作 GCP 儲存方案前,先確認這些你都做到了:
- 根據存取頻率選擇正確的 Cloud Storage 儲存類別
- 設定物件生命週期策略自動降級
- Cloud SQL 啟用自動備份與高可用配置
- 定期測試資料庫恢復(每月一次)
- NoSQL 資料庫選型符合資料規模與模型
- 設定預算告警避免成本失控
- 刪除未使用的快照與舊資料
- 考慮承諾使用折扣(1 年或 3 年)
延伸學習資源
官方文件:
實作教學:
- Qwiklabs:Cloud Storage: Qwik Start
- Qwiklabs:Cloud SQL for MySQL: Qwik Start
- Qwiklabs:Firestore: Qwik Start
下一篇文章預告: ACE-202:打造不當機的系統:GCP 高可用架構設計實戰會仔細談自動擴充執行個體群組、負載平衡器、Cloud CDN 與 Cloud Armor,教你設計出真正不容易掛掉的系統架構。
ACE 考試重點整理
必背知識點
- Cloud Storage 四種儲存類別:Standard → Nearline(30 天)→ Coldline(90 天)→ Archive(365 天),存取頻率越低越便宜
- Lifecycle Policy 可自動降級儲存類別,節省成本
- Cloud SQL 是全託管 RDBMS,支援 MySQL/PostgreSQL/SQL Server
- Cloud Spanner 是全球分散式 RDBMS,需要強一致性 + 全球規模時選它
- Firestore 是文件型 NoSQL,Mobile/Web App 首選
- Bigtable 是寬列型 NoSQL,PB 級 IoT/時序資料首選
- BigQuery 是分析型資料倉儲,SQL 查詢 PB 級資料
常見陷阱題
Q:需要存 PB 級的 IoT 時序資料,延遲要求個位數毫秒,選什麼? A:Bigtable。BigQuery 延遲太高(秒級),Firestore 不適合 PB 級。
Q:需要全球規模的 OLTP 資料庫,要求強一致性和 SQL 支援,選什麼? A:Cloud Spanner。Cloud SQL 不支援全球規模;Firestore 不支援 SQL。
Q:應用目前用 MySQL,想遷移到 GCP 且改動最小,選什麼? A:Cloud SQL for MySQL。API 和查詢完全相容,遷移成本最低。
Q:Cloud Storage 物件 30 天後很少存取,90 天後幾乎不存取,如何省錢? A:設定 Lifecycle Policy:30 天後自動降級到 Nearline,90 天後降級到 Coldline。
關於本系列
本文是「GCP Mastery(GCP 精通之路)」系列的進階篇第 1 課(ACE-201)。整個系列從入門一路帶到實戰,是條完整的學習路徑。
系列文章列表:
- GCP-101:雲端小白必讀:為什麼 2026 年該選擇 GCP?
- GCP-102:GCP 新手上路:30 分鐘完成環境設定
- GCP-103:第一台雲端主機:Compute Engine 完全指南
- GCP-104:GCP 網路基礎:VPC、防火牆與安全連線完全指南
- ACE-201:GCP 資料儲存策略(本文)
- ACE-202:打造不當機的系統:GCP 高可用架構設計實戰
完整系列規劃請見:課程總覽
標籤:#GCP #CloudStorage #CloudSQL #Firestore #Bigtable #Spanner #成本優化 #高可用架構 #資料庫選型
AI Breadcrumbs
Topic Boundaries Marked
本文章標記了以下主題邊界(topic-boundary),供後續拆分影片使用:
- 段落 2 後:選型決策樹(可獨立成「如何選擇 GCP 儲存服務」)
- 段落 3 後:Cloud Storage 完整(可獨立成「Cloud Storage 完全指南」)
- 段落 4 後:Cloud SQL 高可用(可獨立成「Cloud SQL 高可用實戰」)
- 段落 5 後:NoSQL 比較(可獨立成「Firestore vs Bigtable vs Spanner」)
- 段落 6 後:成本優化(可獨立成「GCP 儲存省錢技巧」)
Dependencies
- Based on:
01-research.md - Affects:
03-review.md(審稿將基於此草稿),article-content.json(最終輸出)
Writing Decisions
- 語調:實戰導向,提供具體數字與成本範例
- 結構:遵循「問題 → 解決方案 → 實戰範例」模式
- 可視化:使用表格與 ASCII 圖表增強可讀性
- SEO 優化:
- 標題包含主要關鍵字(GCP、Cloud Storage、Cloud SQL)
- 每段落包含次要關鍵字(Firestore、Bigtable、Spanner、成本優化)
- 內部連結至系列其他文章
- 外部連結至官方文件與權威來源
- 主題拆分考量:每個 topic-boundary 標記的段落都具備獨立性,可單獨成影片
Sources Used
所有外部來源已在文中標註連結,符合「Sources」要求。
相關文章
您可能也會對這些文章感興趣
GCP 資料儲存策略:Cloud Storage 與 Cloud SQL 選型指南
全面比較 GCP 儲存服務:Cloud Storage 儲存類別與生命週期、Cloud SQL vs AlloyDB vs Spanner 資料庫選型、Firestore vs Bigtable NoSQL 策略。包含成本效能分析、ACE...
GCP AI 與大數據:從 BigQuery 到生成式 AI 的完整工具鏈
完整掌握 GCP 大數據與 AI 工具鏈:從 BigQuery 資料倉儲、Dataflow/Dataproc 數據處理、Pub/Sub 訊息佇列,到 Vertex AI 機器學習與 Gemini API 生成式 AI。包含實戰案例:智能客服...
打造不當機的系統:GCP 高可用架構設計實戰
完整掌握 GCP 高可用架構設計:從 Managed Instance Group 自動擴縮容、負載平衡器選型、Cloud CDN 全球加速,到多區域容錯設計。包含 2026 最新功能如 Predictive Autoscaling、Ser...
