GCP 架構設計模式:10 個最常用的雲端架構範例
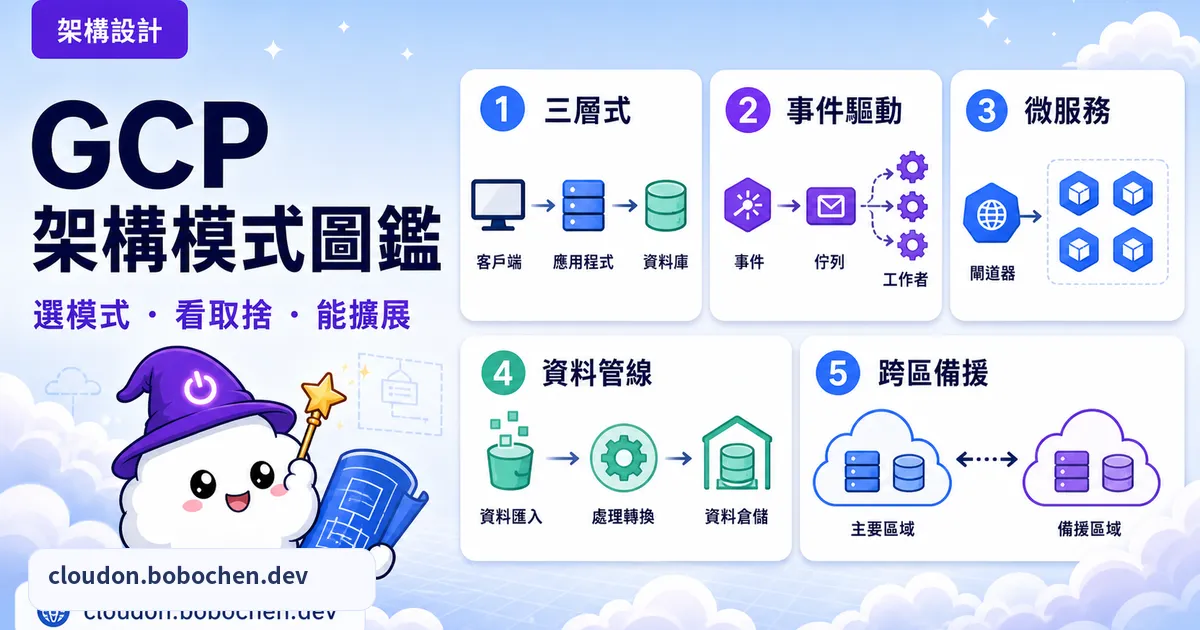
前言
架構設計是雲端工程師最核心的能力。一段程式碼寫得再漂亮,塞進一個爛架構裡,遲早還是會拖垮整個團隊。架構選對了,交付才快、系統才穩、帳單也才壓得住。
Google Cloud 有超過 200 種服務,但真正會在生產環境反覆出現的架構模式,其實就那幾種。這篇挑出 10 個最常用的 GCP 架構設計模式,每個都帶你看場景、ASCII 架構圖、GCP 服務選型、關鍵設計決策、成本等級,還有什麼情況適合用、什麼情況別用。不管你在準備 ACE / PCA 認證,還是正要規劃新專案,看完都能把腦中那團思路理出一套框架,順便練一下架構題最愛考的取捨思維。
模式一:Web 三層架構
場景描述
這是最經典、最常見的架構模式,大多數 Web 應用都適合:公司官網、電商平台、SaaS 產品後台。前端接使用者請求,中間層處理商業邏輯,後端負責存資料。
在 GCP 上,可以用 Cloud Run 取代傳統的 VM,好處是自動擴縮容、按用量計費。
架構圖
使用者
│
▼
┌──────────────────┐
│ Cloud CDN │ ← 靜態資源快取
└────────┬─────────┘
│
▼
┌────────────────────────┐
│ Global Load Balancer │ ← Anycast IP,全球接入
│ + Cloud Armor (WAF) │
└────────────┬───────────┘
│
┌──────────┴──────────┐
▼ ▼
┌───────────┐ ┌───────────┐
│ Cloud Run │ │ Cloud Run │ ← 自動擴縮 0→N
│ (前端 SPA)│ │ (API 後端)│
└─────┬─────┘ └─────┬─────┘
│ │
│ ┌─────┴─────┐
│ ▼ ▼
│ ┌────────────┐ ┌─────────┐
│ │ Cloud SQL │ │ Memorystore│
│ │ (PostgreSQL)│ │ (Redis) │
│ └────────────┘ └──────────┘
│
▼
┌──────────────┐
│Cloud Storage │ ← 靜態檔案 / 使用者上傳
└──────────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| Global HTTP(S) Load Balancer | 流量分配、SSL 終止 | — |
| Cloud Armor | WAF 防護、DDoS 防禦 | — |
| Cloud CDN | 靜態資源快取 | — |
| Cloud Run | 前端 + API 無伺服器運算 | GKE / App Engine |
| Cloud SQL (PostgreSQL) | 關聯式資料庫 | AlloyDB / Cloud Spanner |
| Memorystore (Redis) | 快取、Session 管理 | — |
| Cloud Storage | 靜態檔案儲存 | — |
關鍵設計決策
- Cloud Run 設定
min-instances:避免冷啟動延遲,建議至少設 1,流量高的服務設 2-3 - Cloud SQL 開啟 HA:同一區域內跨可用區 (zone) 自動容錯,failover 約 60 秒級(典型 60-120 秒)。若需跨區域 (cross-region) 容錯,需另行設定 cross-region read replica 並手動提升 (promote),HA 本身無法做到跨區域
- 使用 VPC Connector:讓 Cloud Run 透過私有網路存取 Cloud SQL,避免公開 IP
- Global Load Balancer 使用 Anycast IP:單一 IP 全球接入,自動路由到最近的後端
成本估算等級
$$ — 中等成本
| 元件 | 月估算(小型應用) |
|---|---|
| Cloud Run | $20-50(按請求計費) |
| Cloud SQL (db-f1-micro) | $10-30 |
| Load Balancer | $18 + 流量費 |
| Memorystore | $30-60 |
| 合計 | $80-170/月 |
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| 中小型 Web 應用 | 超低延遲需求(< 10ms) |
| 快速原型開發 | 超高寫入吞吐量 |
| 流量有波動的網站 | 需要 WebSocket 長連線 |
| 團隊較小、不想管 K8s | 複雜的有狀態服務 |
模式二:微服務架構
場景描述
當系統功能越來越複雜、團隊人數超過 10 人,單體應用就會變成瓶頸:部署越來越慢、一個 bug 就能拖垮整個系統、團隊之間還得互相等。微服務架構把系統拆成一個個獨立的小服務,每個團隊顧自己的服務,各自部署、各自擴展。
架構圖
使用者
│
▼
┌───────────────────────┐
│ Global Load Balancer │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ API Gateway │ ← Cloud Endpoints / Apigee
└───────────┬───────────┘
│
┌──────────────┼──────────────┐
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ 使用者服務 │ │ 訂單服務 │ │ 通知服務 │
│ (Cloud Run)│ │ (GKE) │ │ (Cloud Run)│
└──────┬─────┘ └──────┬─────┘ └──────┬─────┘
│ │ │
▼ │ ▼
┌────────────┐ │ ┌────────────┐
│ Cloud SQL │ │ │ Firestore │
└────────────┘ │ └────────────┘
▼
┌────────────┐
│ Cloud │
│ Spanner │
└────────────┘
◄── 服務間通訊 ──►
┌──────────────────────────────────────┐
│ Cloud Pub/Sub │ ← 非同步、解耦通訊
└──────────────────────────────────────┘
┌──────────────────────────────────────┐
│ Cloud Trace + Cloud Logging │ ← 分散式追蹤
└──────────────────────────────────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| Cloud Run | 無狀態微服務 | App Engine Flex |
| GKE | 有狀態 / 複雜微服務 | — |
| Cloud Pub/Sub | 非同步訊息通訊 | — |
| API Gateway / Apigee | API 管理、流量控制 | Cloud Endpoints |
| Cloud SQL / Spanner | 各服務獨立資料庫 | AlloyDB |
| Firestore | NoSQL 文件資料庫 | Bigtable |
| Cloud Trace | 分散式追蹤 | — |
| Cloud Logging | 集中日誌 | — |
關鍵設計決策
- Database per Service:每個微服務擁有自己的資料庫,避免資料耦合。使用者服務用 Cloud SQL,通知服務用 Firestore,選擇最適合的儲存方案
- 非同步優先:服務間優先使用 Pub/Sub 非同步通訊,只有需要即時回應的才用 HTTP/gRPC 同步呼叫
- Cloud Run vs GKE:無狀態服務用 Cloud Run(省錢省力),複雜有狀態服務才用 GKE
- Observability 三支柱:Cloud Trace(追蹤)、Cloud Logging(日誌)、Cloud Monitoring(指標)缺一不可
成本估算等級
$$$ — 中高成本
微服務數量越多,基礎設施和維運成本越高。GKE 叢集的基本費用加上多個資料庫實例,月費起步 $300-800 以上。
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| 大型系統(> 10 個模組) | 小型專案或 MVP |
| 多團隊並行開發 | 團隊少於 5 人 |
| 各模組需要獨立擴展 | 初期業務邏輯不明確 |
| 已有容器化經驗 | 沒有 DevOps 經驗 |
延伸閱讀:GKE 入門
模式三:事件驅動架構
場景描述
使用者上傳一張圖片,系統要做的事有:壓縮圖片、產生縮圖、寫入資料庫、發通知。這幾步彼此獨立,沒必要塞在同一個請求裡做完。事件驅動架構用「事件」把各步驟串起來,真正做到解耦,也更有彈性。
架構圖
使用者上傳圖片
│
▼
┌──────────────┐ ┌──────────────────┐
│ Cloud Storage │────►│ Eventarc │ ← 自動觸發
│ (原始圖片) │ │ (事件路由器) │
└──────────────┘ └────────┬─────────┘
│
┌─────────────┼─────────────┐
▼ ▼ ▼
┌────────────┐ ┌──────────┐ ┌────────────┐
│Cloud Function│ │Cloud Run │ │Cloud Function│
│ 壓縮圖片 │ │ 產生縮圖 │ │ 寫入紀錄 │
└──────┬─────┘ └────┬─────┘ └──────┬─────┘
│ │ │
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Cloud │ │ Cloud │ │ Firestore│
│ Storage │ │ Storage │ │ │
│ (壓縮版) │ │ (縮圖) │ └──────────┘
└──────────┘ └──────────┘
│
▼
┌──────────────┐
│ Pub/Sub │
│ (通知事件) │
└──────┬───────┘
│
▼
┌──────────────┐
│Cloud Function│
│ 發送 Email │
└──────────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| Cloud Functions (2nd gen) | 事件處理函式 | Cloud Run |
| Eventarc | 事件路由 | — |
| Cloud Pub/Sub | 事件匯流排 | — |
| Cloud Storage | 事件來源 + 儲存 | — |
| Firestore | 事件驅動的 NoSQL 儲存 | — |
關鍵設計決策
- Eventarc vs 直接觸發:Eventarc 提供統一的事件路由,比直接用 Cloud Storage trigger 更靈活、更好管理
- 冪等性設計:Cloud Functions 可能重複執行,每個函式都必須設計成冪等的(執行多次結果相同)
- Dead Letter Topic:設定死信主題,處理失敗的事件不會永久遺失
- Cloud Functions 2nd gen:基於 Cloud Run 建構,支援更長執行時間(最多 60 分鐘)和更大記憶體
成本估算等級
$ — 低成本
按呼叫次數計費,沒有事件就不花錢。流量不確定、或波峰波谷很明顯的場景特別適合。
| 元件 | 月估算(中等負載) |
|---|---|
| Cloud Functions | $5-20(按呼叫次數) |
| Pub/Sub | $5-15 |
| Cloud Storage | $5-10 |
| Firestore | $5-15 |
| 合計 | $20-60/月 |
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| 非同步處理(圖片、影片、文件) | 需要即時回應的 API |
| IoT 資料蒐集 | 複雜的交易流程 |
| 流量波動大的工作負載 | 需要嚴格順序處理 |
| 自動化工作流程 | 長時間運行的批次工作 |
模式四:資料湖架構
場景描述
企業常有大量結構化、非結構化資料散落在不同系統。資料湖架構先把所有原始資料集中存起來,再用 ETL 管線清洗、轉換,最後載入分析引擎,讓商業決策有資料可依。
架構圖
資料來源 資料湖 分析層
────── ────── ──────
┌──────────┐ ┌──────────────────┐
│ 應用程式 │──────────► │ │
│ 資料庫 │ │ │
└──────────┘ │ Cloud Storage │ ┌──────────────┐
│ (原始資料層) │ │ │
┌──────────┐ │ │────►│ BigQuery │
│ IoT │──────────► │ gs://data-lake/ │ │ (資料倉儲) │
│ 裝置 │ │ ├── raw/ │ │ │
└──────────┘ │ ├── processed/ │ └──────┬───────┘
│ └── curated/ │ │
┌──────────┐ │ │ ▼
│ SaaS │──────────► └────────┬─────────┘ ┌──────────────┐
│ API │ │ │ Looker │
└──────────┘ │ │ (視覺化) │
▼ └──────────────┘
┌──────────────┐
│ Dataflow │ ← Apache Beam ETL
│ (資料轉換) │
└──────────────┘
│
┌───────┴────────┐
▼ ▼
┌────────────┐ ┌──────────────┐
│ BigQuery │ │ Cloud Storage │
│ (分析表) │ │ (處理後資料) │
└────────────┘ └──────────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| Cloud Storage | 資料湖儲存(原始/處理後) | — |
| Dataflow | 串流 + 批次 ETL 處理 | Dataproc (Spark) |
| BigQuery | 資料倉儲、SQL 分析 | — |
| Looker / Looker Studio | 商業智慧視覺化 | — |
| Data Catalog | 資料目錄、中繼資料管理 | — |
| Cloud DLP | 敏感資料偵測與遮罩 | — |
關鍵設計決策
- 三層資料分區:raw(原始)→ processed(清洗後)→ curated(商業可用),每層有不同的存取權限
- Cloud Storage 生命週期:raw 資料 30 天後自動降級 Nearline,90 天降級 Coldline,降低儲存成本
- BigQuery 分區表:依日期分區,查詢時只掃描需要的分區,大幅降低費用
- Dataflow vs Dataproc:新專案用 Dataflow(託管式、自動擴展),已有 Spark 程式碼用 Dataproc
成本估算等級
$$$ — 中高成本
| 元件 | 月估算(TB 級資料) |
|---|---|
| Cloud Storage (10 TB) | $200-260 |
| Dataflow | $100-500(依處理量) |
| BigQuery | $50-300(依查詢量) |
| 合計 | $350-1,060/月 |
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| 多來源資料整合 | 資料量很小(< 100 GB) |
| 歷史資料分析 | 需要即時查詢(< 1 秒) |
| 機器學習資料準備 | 只有單一資料來源 |
| 合規性需求(資料留存) | 預算極為有限 |
延伸閱讀:BigQuery 資料分析 | Dataflow 與 Dataproc
模式五:即時串流分析
場景描述
電商平台要即時盯詐騙交易、遊戲公司要即時追玩家行為、物聯網系統要即時抓出異常的感測器。這些場景都得在資料進來的「當下」就分析、反應,不能等到隔天跑批次報表。
架構圖
即時資料來源 串流處理 輸出
┌──────────┐ ┌──────────────┐
│ App │──────────► │ │
│ Events │ │ Cloud │
└──────────┘ │ Pub/Sub │
│ │ ┌──────────────┐
┌──────────┐ │ (訊息佇列) │───────►│ Dataflow │
│ IoT │──────────► │ │ │ (串流處理) │
│ Core │ └──────────────┘ └──────┬───────┘
└──────────┘ │
┌────────────┼───────────┐
┌──────────┐ ▼ ▼ ▼
│ API │ ┌────────────┐ ┌──────────┐ ┌────────┐
│ Logs │ │ BigQuery │ │ Bigtable │ │ Cloud │
└──────────┘ │ (即時分析) │ │ (低延遲) │ │Monitoring│
└──────┬─────┘ └──────────┘ │ (告警) │
│ └────────┘
▼
┌──────────────┐
│ Looker │
│ Studio │
│ (即時儀表板)│
└──────────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| Cloud Pub/Sub | 訊息接收、緩衝 | — |
| Dataflow (Streaming) | 即時串流處理 | — |
| BigQuery (Streaming insert) | 即時分析查詢 | — |
| Bigtable | 低延遲時序資料 | — |
| Looker Studio | 即時儀表板 | Looker |
| Cloud Monitoring | 告警、異常偵測 | — |
關鍵設計決策
- Pub/Sub 作為緩衝:即使 Dataflow 暫時無法處理,訊息會在 Pub/Sub 中保留(最多 31 天),不會遺失
- Dataflow Windowing:使用滑動視窗(Sliding Window)做即時聚合,例如「過去 5 分鐘的平均值」
- BigQuery Streaming Insert:資料延遲約 2-5 秒即可查詢,但費用比批次載入高
- Bigtable 用於低延遲:需要毫秒級讀取的場景(如即時推薦),用 Bigtable 取代 BigQuery
成本估算等級
$$$$ — 高成本
串流處理要 24/7 開著運算資源,Dataflow streaming job 和 BigQuery streaming insert 都比批次處理貴。
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| 即時詐騙偵測 | 可以等隔天出報表的分析 |
| IoT 即時監控 | 資料量很小的系統 |
| 即時推薦系統 | 預算有限的新創 |
| 遊戲即時排行榜 | 資料不需要即時處理 |
模式六:CI/CD Pipeline
場景描述
開發團隊每天都在提交程式碼,要是每次部署都得手動操作,不只浪費時間,還很容易出錯。CI/CD Pipeline 把從提交程式碼到上生產的整段流程都自動化:自動測試、自動建容器映像、自動部署到目標環境。
架構圖
開發者 建置 & 測試 部署
┌──────────┐ ┌──────────────────┐
│ GitHub / │ push │ │
│ Cloud │─────────►│ Cloud Build │
│ Source │ │ │
└──────────┘ │ ┌────────────┐ │
│ │ 1. Lint │ │
│ │ 2. Test │ │
│ │ 3. Build │ │
│ │ 4. Scan │ │
│ └────────────┘ │
└────────┬─────────┘
│
▼
┌──────────────────┐
│ Artifact Registry│ ← 容器映像倉庫
│ (Container Image)│
└────────┬─────────┘
│
┌───────────┼───────────┐
▼ ▼ ▼
┌───────────┐ ┌────────┐ ┌──────────┐
│ Cloud Run │ │ GKE │ │Cloud │
│ (Staging)│ │(Staging)│ │Functions │
└─────┬─────┘ └───┬────┘ └────┬─────┘
│ │ │
▼ ▼ ▼
┌─────────────────────────────────┐
│ 手動審核 / 自動金絲雀部署 │
└──────────────┬──────────────────┘
│
▼
┌───────────┐ ┌────────┐
│ Cloud Run │ │ GKE │
│ (Prod) │ │ (Prod) │
└───────────┘ └────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| Cloud Build | CI/CD 執行引擎 | GitHub Actions |
| Artifact Registry | 容器映像、套件儲存 | — |
| Cloud Deploy | 持續交付管線 | — |
| Cloud Run / GKE | 部署目標 | — |
| Binary Authorization | 映像簽章驗證 | — |
關鍵設計決策
- Artifact Registry 取代 Container Registry:Container Registry 已於 2025 年正式關閉(停寫、停讀),新專案一律使用 Artifact Registry
- Cloud Deploy 金絲雀部署:先將新版本部署到 10% 流量,觀察錯誤率後再全量部署
- Binary Authorization:只允許經過簽章的映像部署到生產環境,防止未經測試的程式碼上線
- 多環境策略:dev → staging → prod,每個環境獨立的 GCP 專案,透過 IAM 控管權限
成本估算等級
$ — 低成本
| 元件 | 月估算 |
|---|---|
| Cloud Build | 每月 2,500 分鐘免費,超過 $0.006/分 |
| Artifact Registry | $0.10/GB/月 |
| Cloud Deploy | 免費(底層用 Cloud Build) |
| 合計 | $10-50/月(中小團隊) |
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| 所有需要自動化部署的專案 | 極少更新的靜態網站 |
| 容器化應用 | 完全不用容器的 legacy 系統 |
| 多環境(dev/staging/prod) | 個人 side project |
| 需要合規審計的企業 | — |
延伸閱讀:Cloud Build CI/CD
模式七:混合雲架構
場景描述
大型企業不可能一夜之間把所有系統搬上雲。混合雲架構讓地端資料中心和 GCP 並存:核心銀行系統留在地端,新功能放到雲端,兩邊透過安全的網路連線互通。這也是 PCA 考試的重點之一。
架構圖
地端資料中心 Google Cloud
───────────── ────────────
┌──────────────┐ ┌──────────────────────┐
│ │ │ │
│ Legacy Apps │ │ ┌──────────────┐ │
│ (地端 VM) │ │ │ GKE │ │
│ │ │ │ Enterprise │ │
│ ┌────────┐ │ Cloud VPN / │ │ (容器平台) │ │
│ │ DB │ │ Interconnect │ └──────────────┘ │
│ │ Server │ │◄──────────────────►│ │
│ └────────┘ │ (加密通道) │ ┌──────────────┐ │
│ │ │ │ Cloud Run │ │
│ ┌────────┐ │ │ │ (新服務) │ │
│ │ On-prem│ │ │ └──────────────┘ │
│ │ K8s │ │ │ │
│ └────────┘ │ │ ┌──────────────┐ │
│ │ │ │ BigQuery │ │
└──────────────┘ │ │ (資料分析) │ │
│ └──────────────┘ │
│ │
└──────────────────────┘
◄── 統一管理 ──►
┌─────────────────────────────────────────────────────────┐
│ GKE Enterprise Fleet │
│ 統一政策 ── 統一觀測 ── 統一安全 ── 統一網路 │
└─────────────────────────────────────────────────────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| GKE Enterprise | 多叢集 / 混合雲容器管理 | — |
| Cloud VPN | 地端到 GCP 加密通道 | Cloud Interconnect(頻寬更大) |
| Cloud Interconnect | 專用線路(10/100 Gbps) | Partner Interconnect |
| Cloud DNS | 混合 DNS 解析 | — |
| Config Management | 統一政策管理 | — |
關鍵設計決策
- Cloud VPN vs Interconnect:流量 < 10 Gbps 用 VPN(便宜、快速設定),> 10 Gbps 或需要低延遲用 Dedicated Interconnect
- GKE Enterprise Fleet:統一管理地端和雲端的 Kubernetes 叢集,一致的安全政策和觀測能力
- 逐步遷移策略:先遷移無狀態服務,再遷移有狀態服務,最後遷移核心資料庫
- 網路設計:避免 IP 衝突,使用 /16 以上的 VPC CIDR,預留擴展空間
成本估算等級
$$$$ — 高成本
Dedicated Interconnect 的月費,加上 GKE Enterprise 授權費,基礎成本是所有模式裡最高的。適合那種已經在地端投了一大筆的企業。
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| 大型企業漸進式雲端遷移 | 全新系統(直接雲原生) |
| 法規要求資料留在地端 | 小型團隊 / 新創 |
| 已有地端 Kubernetes 投資 | 預算有限 |
| 多雲策略 | 沒有專職 DevOps 團隊 |
延伸閱讀:混合雲與連線方案
模式八:高可用多區域架構
場景描述
單一區域的 GCP 資料中心也可能出問題(雖然很少)。SLA 要求 99.99% 以上的服務,就一定得設計跨區域架構:就算整個 asia-east1 區域當掉,asia-northeast1 也能接手,使用者完全無感。
架構圖
使用者
│
▼
┌────────────────────────┐
│ Global Load Balancer │ ← Anycast IP
│ (跨區域流量分配) │
└────────────┬───────────┘
│
┌────────────┴────────────┐
▼ ▼
┌──────────────────┐ ┌──────────────────┐
│ asia-east1 │ │ asia-northeast1 │
│ (台灣) │ │ (東京) │
│ │ │ │
│ ┌────────────┐ │ │ ┌────────────┐ │
│ │ MIG │ │ │ │ MIG │ │
│ │ (min: 2) │ │ │ │ (min: 2) │ │
│ └────────────┘ │ │ └────────────┘ │
│ │ │ │
│ ┌────────────┐ │ │ ┌────────────┐ │
│ │ Cloud SQL │ │ │ │ Cloud SQL │ │
│ │ (Primary) │◄─┼─────┼──│ (Read │ │
│ │ │ │非同步 │ │ Replica) │ │
│ └────────────┘ │ │ └────────────┘ │
│ │ │ │
│ ┌────────────┐ │ │ ┌────────────┐ │
│ │Memorystore │ │ │ │Memorystore │ │
│ │ (Redis) │ │ │ │ (Redis) │ │
│ └────────────┘ │ │ └────────────┘ │
└──────────────────┘ └──────────────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| Global HTTP(S) Load Balancer | 跨區域流量分配(Anycast IP) | — |
| Managed Instance Group (MIG) | 自動擴縮容 VM 群組 | Cloud Run |
| Cloud SQL HA(區域內 zone 容錯)+ Cross-region Read Replica(跨區域唯讀副本) | 主要 + 跨區域唯讀副本 | Cloud Spanner(原生多區域) |
| Memorystore | 區域級快取 | — |
| Cloud Monitoring | 健康檢查、自動容錯切換 | — |
| Cloud Armor | DDoS 防護 | — |
關鍵設計決策
- Global LB + Anycast IP:使用者連到同一個 IP,Google 網路自動路由到最近、最健康的後端
- MIG 跨區域:每個區域至少 2 個 instance,確保單一 zone 故障不影響服務
- Cloud SQL Cross-region Replica:平時讀寫分離(副本分擔讀取流量),災難時可手動提升為主要
- Cloud Spanner 替代方案:如果需要自動化的多區域寫入,考慮 Cloud Spanner(但成本更高)
成本估算等級
$$$$ — 高成本
所有資源都得開兩份(兩個區域),再加上跨區域資料同步的流量費。
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| SLA 99.99% 以上的服務 | 內部工具系統 |
| 電商平台、金融服務 | 成本敏感的新創 |
| 全球使用者 | 僅服務單一國家的小型應用 |
| 法規要求業務持續性 | MVP / 實驗性專案 |
延伸閱讀:GCP 高可用架構設計實戰 | 負載平衡器完全指南
模式九:災難復原架構
場景描述
高可用是「預防停機」,災難復原則是「停機後怎麼救回來」。就算你做了多區域高可用,還是得有一套災難復原計畫:萬一資料被誤刪、勒索軟體把資料庫加密了,要怎麼恢復?GCP 有不同等級的 DR 策略,從冷備份到熱待機都有。
架構圖
主要區域 (asia-east1) DR 區域 (us-central1)
──────────────────── ─────────────────────
┌──────────────────┐ ┌──────────────────┐
│ │ │ │
│ ┌────────────┐ │ │ ┌────────────┐ │
│ │ Cloud Run │ │ 定期快照 │ │ Cloud Run │ │
│ │ (Active) │ │ ─────────────────►│ │ (Standby) │ │
│ └────────────┘ │ │ │ min-inst: 0│ │
│ │ │ └────────────┘ │
│ ┌────────────┐ │ 跨區域複製 │ ┌────────────┐ │
│ │ Cloud SQL │ │ ─────────────────►│ │ Cloud SQL │ │
│ │ (Primary) │ │ 非同步 │ │ (Replica) │ │
│ └────────────┘ │ │ └────────────┘ │
│ │ │ │
│ ┌────────────┐ │ 跨區域複製 │ ┌────────────┐ │
│ │ Cloud │ │ ─────────────────►│ │ Cloud │ │
│ │ Storage │ │ 自動 (dual/ │ │ Storage │ │
│ │ (資料) │ │ multi-region) │ │ (副本) │ │
│ └────────────┘ │ │ └────────────┘ │
│ │ │ │
└──────────────────┘ └──────────────────┘
DR 策略對照
──────────
┌──────────┬──────────┬──────────┬──────────┐
│ 策略 │ RTO │ RPO │ 成本 │
├──────────┼──────────┼──────────┼──────────┤
│ 備份還原 │ 24 hr │ 24 hr │ $ │
│ 先導燈光 │ 1-4 hr │ 分鐘 │ $$ │
│ 溫待機 │ 10 min │ 秒 │ $$$ │
│ 熱待機 │ < 1 min │ 0 │ $$$$ │
└──────────┴──────────┴──────────┴──────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| Cloud SQL Cross-region Replica | 資料庫跨區域複製 | Cloud Spanner |
| Cloud Storage (dual-region) | 物件儲存自動跨區域複製 | Multi-region |
| Cloud Run (min-instances: 0) | DR 區域待機服務 | GKE |
| Cloud DNS | DNS 容錯切換 | Global LB |
| Cloud Scheduler | 定期 DR 演練 | — |
| Backup and DR Service | 集中備份管理 | 自建快照排程 |
關鍵設計決策
- RTO/RPO 決定策略:先問業務「可以接受多久不能用」和「可以丟多少資料」,再選擇 DR 等級
- Cloud Storage Dual-region:比 Multi-region 便宜,自動在兩個特定區域間複製,滿足大多數 DR 需求
- DR 演練:每季定期演練 failover 流程,確保文件和流程都是最新的
- Cloud Run min-instances: 0:DR 區域的服務平時不開機,不花運算費用,failover 時才啟動
成本估算等級
$$ ~ $$$$ — 視策略而定
備份還原只多花一點儲存費,熱待機則要養一整套雙倍的基礎設施。
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| 任何生產環境(至少需要備份還原) | 開發 / 測試環境 |
| 金融、醫療等法規要求 | 可以接受長時間停機的系統 |
| 資料無法重新產生的系統 | 資料可以重新蒐集的系統 |
| 跨國企業 | 個人專案 |
模式十:AI 應用架構
場景描述
現在隨便接一個案子,客戶八成都會問一句「能不能加個 AI」——客服聊天機器人、文件摘要、智慧搜尋、影像分析,全都是常見需求。好消息是有了 GCP 的 Gemini Enterprise Agent Platform(含 Agent Builder、Model Garden)和 Gemini API,開發者不用自己訓練模型,就能很快把 AI 應用做出來。
架構圖
使用者
│
▼
┌───────────────────────┐
│ Global Load Balancer │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Cloud Run │ ← AI 應用後端
│ (Application API) │
└───────────┬───────────┘
│
┌──────────────┼──────────────┐
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ Gemini 3.1 │ │ Agent │ │ Vertex AI │
│ API │ │ Search │ │ Vector │
│ (生成式AI)│ │ (企業搜尋) │ │ Search │
└────────────┘ └────────────┘ │ (RAG) │
└──────┬─────┘
│
▼
┌────────────┐
│ Cloud │
│ Storage │
│ (文件庫) │
└────────────┘
┌───────────────────────────────────────────────┐
│ 資料層 │
│ │
│ ┌────────────┐ ┌──────────┐ ┌───────────┐ │
│ │ Firestore │ │ BigQuery │ │ Cloud │ │
│ │ (對話紀錄) │ │ (分析) │ │ Storage │ │
│ │ │ │ │ │ (檔案) │ │
│ └────────────┘ └──────────┘ └───────────┘ │
└───────────────────────────────────────────────┘使用的 GCP 服務
| 服務 | 角色 | 替代方案 |
|---|---|---|
| Gemini 3.1 API | 文字生成、摘要、翻譯 | Claude API |
| Agent Search(前身 Vertex AI Search) | 企業級搜尋(結合 LLM) | — |
| Vertex AI Vector Search | RAG 向量搜尋 | — |
| Cloud Run | AI 應用後端 | GKE |
| Firestore | 對話紀錄、使用者偏好 | Cloud SQL |
| BigQuery | AI 使用量分析 | — |
| Cloud Storage | 文件、圖片儲存 | — |
關鍵設計決策
- Gemini API vs Vertex AI Endpoint:直接呼叫 Gemini 3.1 API 最快上手,需要微調模型才用 Vertex AI 自訂端點
- 企業搜尋改名了:原本的 Vertex AI Search 已更名為 Agent Search,現在隸屬 Gemini Enterprise Agent Platform。看舊文件或考古題還是會碰到舊名,知道是同一個東西就好
- RAG 架構:用 Vertex AI Vector Search 建立向量索引,Gemini 產生回答時參考企業內部文件,提高準確度
- Firestore 存對話紀錄:NoSQL 文件模型天然適合存儲不固定結構的對話歷史
- 成本控制:設定 Gemini API 的每分鐘 token 上限,避免異常流量導致帳單暴增
- 安全防護:使用 Model Armor(Google Cloud 的 AI 內容安全服務,可過濾 prompt 與模型回應),防止生成不當內容
成本估算等級
$$ ~ $$$ — 視呼叫量而定
| 元件 | 月估算 |
|---|---|
| Gemini 3.1 API | $50-500(依 token 量) |
| Cloud Run | $20-50 |
| Firestore | $10-30 |
| Vector Search | $50-200 |
| 合計 | $130-780/月 |
適合場景 & 不適合場景
| 適合 | 不適合 |
|---|---|
| 客服聊天機器人 | 不需要 AI 的 CRUD 系統 |
| 文件摘要、智慧搜尋 | 需要 100% 精確結果 |
| 內容生成、翻譯 | 高度機密資料(需額外考量) |
| 影像分析、分類 | 預算極為有限 |
延伸閱讀:GCP AI 與大數據服務
如何選擇架構模式?
接到新專案,不確定該選哪種架構模式?下面這張快速決策樹可以幫你定位:
你的系統是什麼類型?
│
├── Web 應用
│ ├── 小型 / MVP ──────────────────► 模式一:Web 三層架構
│ ├── 大型 / 多團隊 ───────────────► 模式二:微服務架構
│ └── 需要高可用(99.99%+)────────► 模式八:高可用多區域
│
├── 資料處理
│ ├── 批次分析 ─────────────────────► 模式四:資料湖架構
│ └── 即時分析 ─────────────────────► 模式五:即時串流分析
│
├── 事件 / 自動化
│ └── 非同步處理 ───────────────────► 模式三:事件驅動架構
│
├── AI 應用
│ └── 生成式 AI / LLM ──────────────► 模式十:AI 應用架構
│
├── 基礎設施
│ ├── 有地端資料中心 ───────────────► 模式七:混合雲架構
│ ├── 需要自動化部署 ───────────────► 模式六:CI/CD Pipeline
│ └── 災難復原需求 ─────────────────► 模式九:災難復原架構
│
└── 以上皆是 ──────────────────────────► 組合使用!重要提醒:實際專案通常是好幾種模式混著用。例如一個電商平台,可能同時用到模式二(微服務)+ 模式六(CI/CD)+ 模式八(高可用)+ 模式五(即時分析)。
ACE / PCA 考試與架構設計
架構設計是 Professional Cloud Architect (PCA) 考試的核心,在 Associate Cloud Engineer (ACE) 考試裡的比重也越來越高。
ACE 考試重點
ACE 考試中的架構題通常考:
- 服務選型:給定場景,選擇正確的 GCP 服務組合
- 成本優化:選擇最經濟的架構方案
- 基本高可用:區域 vs 多區域的選擇
常見考題模式:
| 題目關鍵字 | 對應模式 | 重點服務 |
|---|---|---|
| 「無伺服器」「自動擴展」 | 模式一 / 三 | Cloud Run, Cloud Functions |
| 「解耦」「非同步」 | 模式二 / 三 | Pub/Sub, Eventarc |
| 「即時分析」「串流」 | 模式五 | Dataflow, BigQuery Streaming |
| 「CI/CD」「自動部署」 | 模式六 | Cloud Build, Artifact Registry |
| 「地端」「混合」 | 模式七 | GKE Enterprise, Cloud VPN |
| 「RTO」「RPO」 | 模式九 | Cross-region replica |
PCA 考試重點
PCA 考試挖得更深,會考:
- 架構的 trade-off:為什麼選擇這個架構而不是另一個?
- 案例分析:給定一家公司的業務需求,設計完整架構
- 成本 vs 效能 vs 安全性的三角取捨
- 遷移策略:如何從地端遷移到雲端
備考建議:
- 熟悉每種模式的 GCP 服務組合
- 理解每種模式的適用場景和限制
- 練習在「成本」和「效能」之間做取捨
- 多做 Google Cloud 官方的架構案例練習
延伸閱讀:ACE 認證考試準備攻略 | 雲端遷移策略
總結
以下是 10 個架構模式的速查表:
| # | 模式 | 核心服務 | 成本 | 複雜度 |
|---|---|---|---|---|
| 1 | Web 三層架構 | Cloud Run + Cloud SQL | $$ | 低 |
| 2 | 微服務架構 | GKE + Cloud Run + Pub/Sub | $$$ | 高 |
| 3 | 事件驅動架構 | Cloud Functions + Eventarc | $ | 中 |
| 4 | 資料湖架構 | Cloud Storage + Dataflow + BigQuery | $$$ | 中高 |
| 5 | 即時串流分析 | Pub/Sub + Dataflow + BigQuery | $$$$ | 高 |
| 6 | CI/CD Pipeline | Cloud Build + Artifact Registry | $ | 低 |
| 7 | 混合雲架構 | GKE Enterprise + Cloud VPN | $$$$ | 很高 |
| 8 | 高可用多區域 | Global LB + MIG + Cloud SQL HA | $$$$ | 高 |
| 9 | 災難復原架構 | Cross-region Replica + Storage | $$ ~ $$$$ | 中高 |
| 10 | AI 應用架構 | Gemini 3.1 + Vertex AI + Cloud Run | $$ ~ $$$ | 中 |
提醒一下:文中各模式的金額都是「概略估算」,方便你抓量級用的,實際請以 GCP 官方定價 為準。定價、免費額度會隨時間變動,規劃預算前務必自己用官方 Pricing Calculator 再算一次。
記住三件事:
- 從簡單開始:先用模式一,真的卡住了再演進到更複雜的模式,別一開始就上微服務
- 成本意識:貴的架構不代表好,能撐住業務需求又不燒錢的才是對的
- 持續演進:架構很少一次到位,多半是隨著業務長大慢慢調出來的
說到底,架構設計沒有標準答案,永遠是看當下的條件做取捨。這 10 個模式給你一組腦中的抽屜,下次接到題目或新專案,至少知道從哪幾個抽屜開始翻——剩下的就靠你自己練手感了。
更多學習資源
相關文章
您可能也會對這些文章感興趣
GCP 架構設計模式:10 個最常用的雲端架構範例
精選 10 個 Google Cloud 最實用的架構設計模式:Web 三層架構、微服務、事件驅動、資料湖、即時分析、混合雲、CI/CD、高可用、多區域災難復原、AI 應用。每個模式附架構圖和 GCP 服務選型。
GCP 認證攻略:從 ACE 到 PCA 的完整學習路徑與備考指南
完整解析 GCP 認證體系:ACE 與 PCA 考試準備策略、2026 年最新考試變化(Well-Architected Framework、GenAI)、免費學習資源大全、6-8 週備考時程規劃、考試技巧與心態調整。PCA 認證者平均年薪...

GKE Autopilot 聽起來超棒,但它的缺點你最好先知道
GKE Autopilot 用「全託管」換「控制權」——從 Pay-per-Pod 成本陷阱、Security Context 限制、冷啟動擴展延遲、到 Alpha/Beta 功能滯後,這篇從架構師視角整理出選 Autopilot 前你一定...
